
Nvidia A100 のベンチマーク情報を公開しました。 今回は、CNNだけでなくBERTでもベンチマークしました。下からダウンロードページに飛びます。
今回、アーキテクチャがAmpereへと更新され、性能向上だけでなく、様々な機能が搭載されました。
スペック情報
NVIDIA A100-PCIEと、NVIDIA V100S-PCIEのスペック比較です。
TensorCore、FP16の性能が大きく伸びました。
|
GPU型番 |
NVIDIA A100-PCIE |
NVIDIA Tesla V100S-PCIE |
|
アーキテクチャ |
Ampere |
Volta |
|
GPUベースクロック |
765 MHz |
1245 MHz |
|
GPU Boost時クロック |
1410 MHz |
1597 MHz |
|
CUDAコア数 |
6912 |
5120 |
|
TensorCore数 |
432 |
640 |
|
メモリ仕様 |
HBM2 |
HBM2 |
|
メモリインタフェース |
5120 bit |
4096 bit |
|
メモリ帯域 |
1555 GB/sec |
1134 GB/sec |
|
メモリ容量 |
40 GB |
32 GB |
|
最大消費電力 |
250 W |
250 W |
|
FP64理論性能 |
9.7 TFLOPS |
8.2 TFLOPS |
|
FP32理論性能 |
19.5 TFLOPS |
16.4 TFLOPS |
|
FP16理論性能 |
78 TFLOPS |
31.4 TFLOPS |
|
TensorCore FP64理論性能 |
19.5 TFLOPS |
|
|
TensorCore FP16理論性能 (スパース性機能) |
312 TFLOPS (624 TFLOPS) |
130 TFLOPS |
|
TensorCore FP32理論性能 (スパース性機能) |
156 TFLOPS (312 TFLOS) |
|
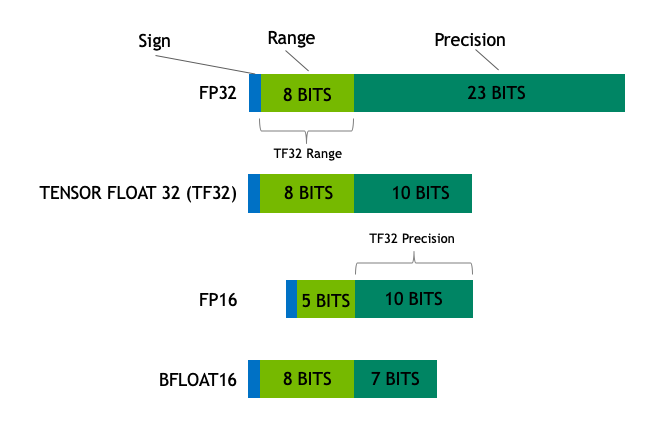
TF32、BF16、FP64へのTensorCoreの適用
TensorCoreは、Voltaでは、FP16(半精度)、Turingでは、INT8、INT4まで適用できましたが、Ampereからは、TF32、BF16という精度も扱えるようになります。
今まで、FP16では、表現できる数値の範囲がFP32に比べて、小さくなってしまい、範囲を超えてしまった数値が出てきて学習の結果に影響が表れることがありました。NVIDIAは混合精度やロス・スケーリングといった手法によって、FP16の有効性を主張していました。TF32やBF16は、FP32と同等の数値範囲を表現できるので、そういった欠点を解消できます。
MIGの導入
MIG(マルチインスタンスGPU)により、GPUを分割して使用することが可能になります。1人が1つのGPUを占有して使用しているが、オーバースペックだという意見がありました。
NVIDIA A100は、最大7つのGPUに分割でき、分割した場合、OSからは7つのGPUが存在するように見えます。GPUを持て余してしまう方に最適です。
まとめ
NVIDIA A100の簡単な紹介でした。実際の性能が気になる方は、下のリンクからベンチマークレポートをダウンロードしてみてください。

