
NVIDIA H100 と GeForce RTX 4090 の機械学習ベンチマーク報告書をこちらで公開しました。報告書の中では、これらのGPUに NVIDIA A100 と RTX 3090 を加えた計4種のGPUで、機械学習の学習性能を比較評価しています。
スペック情報
NVIDIA H100 PCIe、NVIDIA A100 PCIe、GeForce RTX 4090、GeForce RTX 3090 のスペック比較表は次のとおりです。CUDAコア数とGPU Boost時クロックが向上していることがわかります。
|
GPU型番 |
NVIDIA H100-PCIE |
NVIDIA A100-PCIE |
Geforce RTX4090 |
Geforce RTX 3090 |
|
アーキテクチャ |
Hopper |
Ampere |
Ada Lavelace |
Ampere |
|
GPUベースクロック |
990 MHz |
765 MHz |
|
|
|
GPU Boost時クロック |
1755 MHz |
1410 MHz |
2520 MHz |
1695 MHz |
|
CUDAコア数 |
14592 |
6912 |
16384 |
10496 |
|
TensorCore数 |
456 |
432 |
512 |
328 |
|
メモリ仕様 |
HBM2e |
HBM2e |
GDDR6X |
GDDR6X |
|
メモリインタフェース |
5120 bit |
5120 bit |
384 bit |
384 bit |
|
メモリ帯域 |
2000 GB/sec |
1935 GB/sec |
1008 GB/sec |
936 GB/sec |
|
メモリ容量 |
80 GB |
80 GB |
24 GB |
24 GB |
|
最大消費電力 |
350 W |
300 W |
450 W |
350 W |
|
FP64理論性能 |
48 TFLOPS |
9.7 TFLOPS |
|
|
|
FP32理論性能 |
48 TFLOPS |
19.5 TFLOPS |
82.6 TFLOPS |
35.6 TFLOPS |
|
FP16理論性能 |
96 TFLOPS |
78 TFLOPS |
82.6 TFLOPS |
35.6 TFLOPS |
|
TensorCore FP64 理論性能 |
48 TFLOPS |
19.5 TFLOPS |
|
|
|
TensorCore FP16 理論性能 (スパース性機能) |
800 TFLOPS (1600 TFLOPS) |
312 TFLOPS (624 TFLOPS) |
330.3 TFLOPS (660.6 TFLOPS) |
142 TFLOPS (284 TFLOPS) |
|
TensorCore TF32 理論性能 (スパース性機能) |
400 TFLOPS (800 TFLOPS) |
156 TFLOPS (312 TFLOS) |
82.6 TFLOPS (165.2TFLOPS) |
35.6 TFLOPS (71 TFLOPS) |
|
TensorCore FP8 理論性能 (スパース性機能) |
1600 TFLOPS (3200 TFLOPS) |
|
660 TFLOPS (1321.2 TFLOPS) |
|
抜粋:CNNモデル別 GPU世代間性能比
様々なモデルで、精度を変更しながら、NVIDIA H100、NVIDIA A100、RTX4090、RTX3090について、学習速度をベンチマーク取得しました。H100とA100、RTX4090とRTX3090を比較しやすくするためパフォーマンス比にしたグラフを次に示します。
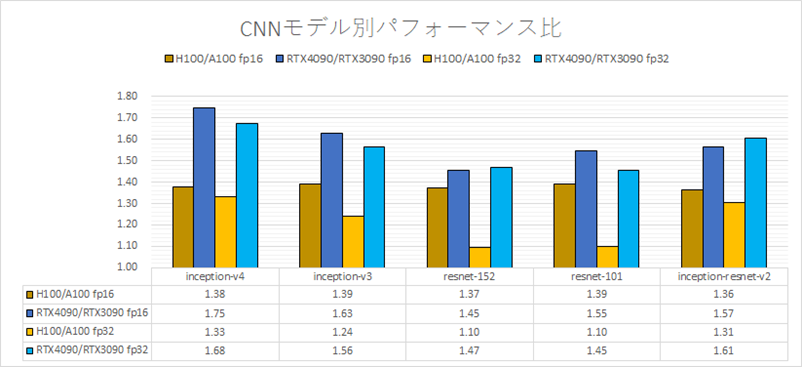
理論性能と実効性能の差についてはベンチマーク報告書の中で詳細に記載しています。
続きはベンチマーク報告書で
公開されている情報だけからでは、性能を予測するのは困難です。実際の性能が気になる方は、こちらのリンクからベンチマーク報告書をダウンロードしてご確認ください。

