『NVLink Bridgeで複数GPUを繋いだら、それらが1GPUとして扱えるようになるんでしょ?』という誤解をされているお客様をしばしばお見受けいたします。こちらの記事では、それが誤解であること、また、SLIやUnified Memoryといった関連する情報についても整理して解説いたします。間違った期待を抱いて失敗しないように、正しい理解を深めていきましょう。
GPUのメモリ空間は他デバイスから隔絶されています
GPU上には演算するためのプロセッサと、データを一時的に置いておくためのメモリ(VRAM)が搭載されています。GPUのメモリを、CUDAで書かれたプログラムから利用するには、cudaMallocでメモリ領域を確保し、cudaMemcpyを使ってホスト(CPU側)のメモリとデータの送受信を行い、GPU上で演算kernelとする関数(以下、GPU-Kernel)を呼び出し、最後にcudaFreeでメモリ領域を解放する、といった流れになります。
ポイントは、GPU-Kernelの中で読み書き可能なメモリ領域はそのGPUのVRAMの中に限られているという点です。
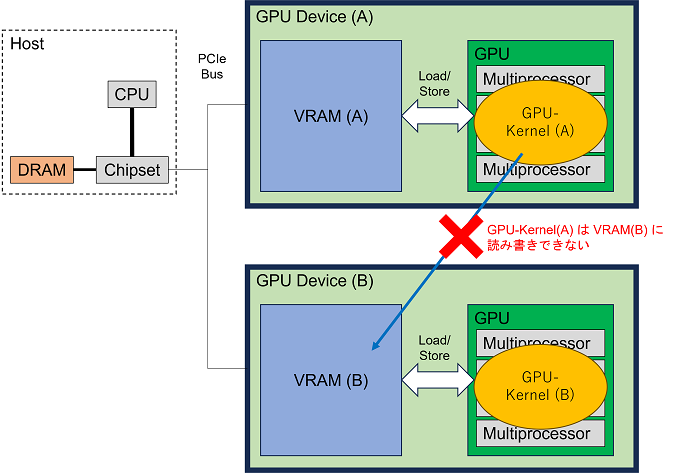
CUDAプログラムの全体ではホストメモリ(RAM)の領域とVRAMの領域が存在しますが、そのうちGPU-Kernelからはそれが動いているGPUのVRAMの中だけにしか読み書きできません。これはGPUのデバイス毎の話ですので、あるGPU(A)でGPU-Kernel(A)が動いているとき、GPU-Kernel(A)は別のGPU(B)のVRAMには読み書きできません。プログラミングの側面から言い換えると、GPU-Kernelのメモリアドレス空間がそのGPUのVRAM内に限られているので、その範囲外にアクセスすることができません。(学術的には、[ホストとGPU]や、[GPUと別GPU]は、分散メモリ環境であると言うことができます。)
NVLink Bridge、NVLinkで繋ぐとはどういう意味?
CUDAの成長期において、複数GPUを使用して並列計算を行うことが流行し始めました。CUDAでは、ホスト(=CPU側)でプログラムを動かし、そのプログラムからGPUを使用する処理を呼び出すという流れで動きますので、複数のGPUを活用するには、ホスト側のプログラムがGPUを使用する処理を並列に実行するという形態となります。たとえば、OpenMPで複数スレッドを立てて各スレッドがCUDAでGPUを使う、あるいは、MPIで複数プロセスを起動して各プロセスがCUDAでGPUを使う、といったやり方が、よく見られるやり方です。
並列計算において、プロセッサー(この場合GPUのこと)間で中間データの通信をすることは一般的な要求です。そして、複数GPUを用いた並列計算では、GPUの演算性能が十分に高いこともあり、[GPUのVRAM]と[別のGPUのVRAM]の間のデータ通信が遅いという問題が顕在化しました。この通信は、前段落に書いた通り、GPU-Kernel(A)は別のGPU(B)のVRAMには読み書きできないという制限があるため、本質的に不可欠な処理です。
この通信処理を具体的に見てみましょう。GPU(のVRAM)とGPU(のVRAM)の間でデータ通信を行うには、GPUがPCIeバスに繋がっていることから、次のように行えばよいことがわかります。
GPUのVRAM → (①PCIeバス経由でコピー) → ホストメモリ → (②PCIeバス経由でコピー) → 別GPUのVRAM
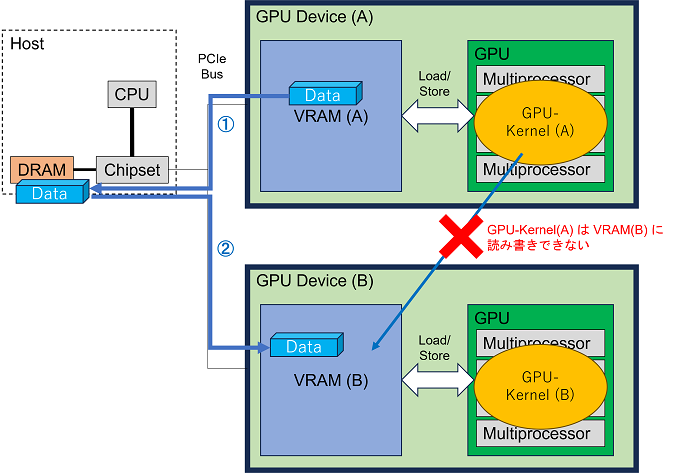
このうち、いちいちホストメモリにコピーしていると遅延が大きいので、ホストメモリを介さないで直接GPU間でデータ通信を行いたいという要求が生まれます。
GPUのVRAM → (①PCIeバス経由でコピー) → 別GPUのVRAM
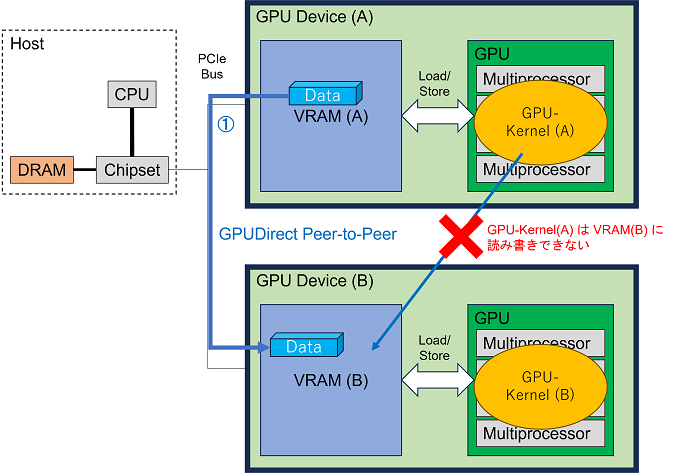
このやり方が GPUDirect Peer-to-Peer 転送と呼ばれているものです。技術的には、GPUのVRAM間で Direct Memory Access (DMA) 転送を行うことに等しく、DMA自体は従来から存在していた技術でした。
さて、ここまで最適化しても、PCIeバス経由でコピーすることが性能ボトルネックとして立ちはだかります。当時、これは PCIe Gen 3.0 x16(単方向で約16GB/s)でした。これを打破したいという思いがNVIDIA社にあったのでしょう、このGPUのVRAM – 別GPUのVRAM 間のデータ通信を直接高速に行えるように NVLink という通信規格がNVIDIA社によって開発され、物理的に隣接する2GPU間でNVLink通信を行えるようにする「コの字」型の接続部品 NVLink Bridge が販売されました。これによってGPU間で50GB/s~100GB/s級の通信速度を利用できるようになりました。
GPUのVRAM → (①NVLink経由でコピー) → 別GPUのVRAM
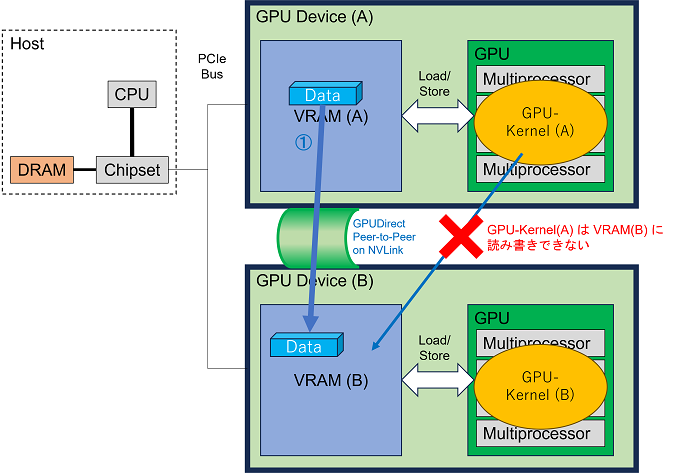
これが、NVLink BridgeでGPU間をNVLink接続することの意味です。NVLinkでGPU間を結ぶと、その間の通信速度が向上します。それ以上でもそれ以下でもありません。NVLinkでGPU間を結んだからと言って、GPU-Kernel(A) が別のGPU(B)のVRAM に読み書きできるようになるわけではありません。
ちなみに NVIDIA DGX A100 や NVIDIA DGX H100 等では、NVLink Bridgeではなく専用ボードを用いて2枚以上のGPUが互いにNVLink接続されていますが、これは物理的なフォームファクタ(形状)が変わっただけで、論理的には以上と同じ話です。
NVLinkを結んでも何故1GPUとして扱えないのか?
NVLink接続することでGPU間の通信帯域は向上しますが、メモリアドレス空間がGPU間で統合されたり拡張されたりはしないからです。具体的に書くと、GPU(A)で動いているGPU-Kernel(A) は 別のGPU(B)のVRAM には読み書きできない、という制限は、NVLink接続したとしても変わりません。したがって、GPU(A)で動いているGPU-Kernel(A) が利用できるメモリ領域は、依然として GPU(A)のVRAM だけです。
例を挙げると、12GBのVRAMを持つ GPU 2枚 をNVLink Bridgeで接続した場合、24GBのメモリ領域を確保して使おうとするCUDAプログラムは、24GBのメモリ領域を確保するところでエラーになりますので、動作しません。その場合に可能なのは、12GBのメモリ領域を確保して使うCUDAプログラムを各GPU別々に稼働させることです。
関連情報1.SLI
PCのゲームやグラフィック処理用途では SLI という複数GPU動作システムがあり、複数GPUを並列動作させ、出力を1つに集約させることができ、高いグラフィック性能を得ることができます。しかし、SLIは、機械学習やHPCといった汎用GPU(GPGPU)計算には使えません。SLIは描画処理を担当する部分のプログラム自体がNVIDIA社によって作りこまれているからこそ、そこに並列化を仕掛けることができるのであって、GPUにどんな処理をさせるかわからない汎用計算にはSLIを適用できません。
関連情報2.Unified Memory
Unified Memory は、1枚のGPUのメモリアドレス空間を仮想的に拡張し、ホストメモリや別GPUのメモリにも一つのメモリアドレス空間として読み書き可能とする技術です。これにより、GPU-Kernel(A)が別のGPU(B)のVRAMに読み書きすることも出来るようになります(後述のとおり、速度に難点がありますが)。こうした技術は、分散メモリ環境で仮想的な共有メモリを実現する “分散共有メモリ” と類される技術です。
分散共有メモリのよくある実装の動きとしては、プロセスが物理メモリのメモリアドレス範囲を超えたところへアクセスしようとしたことを paga fault 等を用いて検出し、当該ページ内容を保持している別の物理メモリからメモリページをその場でコピーしてくる、というものです。データベースアプリケーションのように、読み込みが主なワークロードであれば、ページのキャッシュヒット率が高いので、分散共有メモリでもそれほど性能低下は招かないでしょう。しかし、機械学習やHPCのように、データの読み込みも書き込みも頻繁なワークロードでは、ページのキャッシュヒット率が低く、また、page fault が発生してからメモリページが到着するまで毎回μ秒単位のストールが発生するため、動作が遅くなります。そのため、多くの場合、Unified Memoryに頼るよりも、cudaMemcpy() 等を使ってGPU間データ通信を行うようにプログラマが露に並列処理を実装した方が、(プログラマの知識を活用して)必要十分な量のデータ通信を最適なタイミングで実施することができるので、高速に動作するコードになります。
また、CUDAで Unified Memory を使うには、通常の cudaMemcpy() ではなくcudaMemcpyManaged() というAPI関数を使用してメモリ確保をする必要があるので、たいてい、そのようにソースコードを書き換える必要が生じます。さらに、性能を及第点レベルに持っていくには cudaMemAdvise() や cudaMemPrefetchAsync() 等のAPI関数を使ってプリフェッチを活用するよう書き換えることも不可欠となります。
関連情報3.MATLAB と NCCL
MATLAB の GPU Coder には、CUDA に最適化されたコードを出力する機能があります。cudaMalloc() および cudaMallocManaged() を利用することが出来るようになっている他、CPU および GPU 区画間のデータの依存関係を解析し、生成コード内のcudaMemcpy() の呼び出しの数を最小化するように最適化を実行してくれます。また、MATLAB はGPU通信用の NVIDIA NCCL ライブラリに対応し、複数GPUの利用可否を設定できます。その際、NVLink があれば利用されますし、Infiniband などのマシン間の高速相互接続または GPUDirect RDMAも活用できます。このように、抽象度の高いアプリケーションコードをGPU利用コードへ落とし込む処理系には、プログラマに対して複数GPU並列化を支援する機会があります。
今後の展望:Grace Hopper Superchip でついに実現される、統合メモリ
NVIDIA Grace CPU の内部: NVIDIA が HPC と AI のためのスーパーチップのエンジニアリングを強化
Grace CPU と Hopper GPU を組み合わせた NVIDIA Grace Hopper Superchip では、Grace CPU と Hopper GPU が CUDA アプリケーションでアドレス空間とページ テーブルまで共有できるようになっています。Grace Hopper GPU がページング可能なメモリ割り当てにアクセスすることもでき、Grace Hopper Superchip では、プログラマがシステムのアロケーターを使って GPU のメモリを割り当てることができ、GPU とmallocメモリへのポインターを交換できる機能もあります。ここまでくると「統合されたメモリ」と言えるでしょう。利用できる日がとても楽しみですね。
