CUDAってどんなもの?
『CUDA』は、NVIDIA社のGPUをグラフィック処理以外の汎用の計算用途に使えるようにするための、統合開発環境(コンパイラ等)とランタイムライブラリの集合です。
GPUの内部アーキテクチャは、CPUよりもコア数・スレッド数が大変多い構造になっています(数千スレッド~)。また、GPU上の処理を記述するには、CUDAが登場するより前には、 シェーディング言語といったグラフィック処理専用のプログラミング言語を使いこなす必要がありました。
こうした状況に対し、NVIDIA社はGPUのポテンシャルを簡単に引き出せるようにするべく、CUDAを提供してきました。CUDA環境では、GPUを使うプログラムを記述するためにC/C++言語を少しだけ拡張した記法で書く形となっています。そのソースコードを nvcc というCUDA用コンパイラでコンパイルすると、GPUを使ってくれるバイナリ(実行可能形式)を出力してくれます。あとはそれをシェルから起動すれば、GPUを使って計算が行われる、という構図となっています。
CUDA Samples をコンパイル&実行してみる
NVIDIA社はCUDA向けの様々なサンプルプログラムをオープンソースでGitHubに公開しています。
ソースコードに加えてMakefile(または Visual Studio用*.slnファイル) が一式入手できるので、コンパイルが簡単です。
レポジトリからソースコード一式をZIPダウンロードします。これをCUDAをインストール済みのマシンへコピーして、unzip で展開します。(git に慣れている人は git clone してもらっても、もちろんOKです。)
$ unzip cuda-samples-master.zip
$ cd cuda-samples-master/
$ cd Samples/
Samplesの下には様々なサンプルがあります。いろんなプログラムがありますので色々見てみてください。
$ ls
0_Introduction 2_Concepts_and_Techniques 4_CUDA_Libraries 6_Performance
1_Utilities 3_CUDA_Features 5_Domain_Specific 7_libNVVM
数値計算の例として、0_Introduction の下にある matrixMul(行列積)をコンパイルしてみます。CUDAで書かれたプログラム本体のソースコードはmatrixMul.cuです。
$ cd 0_Introduction/matrixMul/
$ make
/usr/local/cuda/bin/nvcc -ccbin g++ -I../../../Common -m64 --threads 0 --std=c++11 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_61,code=sm_61 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_75,code=sm_75 -gencode arch=compute_80,code=sm_80 -gencode arch=compute_86,code=sm_86 -gencode arch=compute_89,code=sm_89 -gencode arch=compute_90,code=sm_90 -gencode arch=compute_90,code=compute_90 -o matrixMul.o -c matrixMul.cu
ここで、注意点が1つあります。GPUには能力的な世代がいくつかあり、それが Compute Capability という小数値で識別されるようになっています。基本的に、新しくリリースされた高機能なGPUほど、高いCompute Capabilityを有しており、CUDAを介して利用可能なGPU機能も増えています。GPUごとの Compute Capabilityは次のページから参照することができます。
さて、今やろうとしている make では、デフォルトで最新のGPU世代にも対応したバイナリを生成しようとします。上記の -gencode arch=compute_50,code=sm_50 ~ -gencode arch=compute_90,code=compute90 のあたりがそれらで、Compute Capability 5.0~9.0 に対応したバイナリを生成しようとしています。しかし、もしお使いのCUDAのバージョンが古い場合(目安としては11.4以前)には、高い Compute Capability の値に適合するバイナリを生成する機能を nvcc コンパイラが有していないことがあります。その場合には、次のようなエラーが出ます。
nvcc fatal : Unsupported gpu architecture 'compute_89'
このエラーは、compute_89(Compute Capability 8.9) のGPUアーキテクチャ向けのバイナリ生成を要求されたが、使っているCUDAに内蔵されている nvcc コンパイラがそれに対応していないことを意味しています。このような場合には、生成させるバイナリが求める Compute Capability を下げることが回避策となります。CUDA SamplesのMakefile中では、これが SMS という変数で制御されているので、これを例えば次のように下げます。(今回使ったGPUは NVIDIA V100 で、その Compute Capability は 7.0 です)
$ SMS=70 make
/usr/local/cuda/bin/nvcc -ccbin g++ -I../../../Common -m64 --threads 0 --std=c++11 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_70,code=compute_70 -o matrixMul.o -c matrixMul.cu
/usr/local/cuda/bin/nvcc -ccbin g++ -m64 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_70,code=compute_70 -o matrixMul matrixMul.o
このようにすると、Compute Capability 7.0 に適合するバイナリを生成するように動作が変わります。無事コンパイルに成功すると次のようにバイナリ matrixMul がカレントディレクトリに生成されます。
$ ls
Makefile matrixMul.o matrixMul_vs2019.sln matrixMul_vs2022.vcxproj
matrixMul matrixMul_vs2017.sln matrixMul_vs2019.vcxproj NsightEclipse.xml
matrixMul.cu matrixMul_vs2017.vcxproj matrixMul_vs2022.sln README.md
生成されたバイナリを実行してみましょう。コマンドラインからプログラムを装飾無しに起動するだけです。
$ ./matrixMul
GPU Device 0: "Volta" with compute capability 7.0
MatrixA(320,320), MatrixB(640,320)
Computing result using CUDA Kernel...
done
Performance= 2707.42 GFlop/s, Time= 0.048 msec, Size= 131072000 Ops, WorkgroupSize= 1024 threads/block
Checking computed result for correctness: Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
正常に動作すれば、このように行列積が実行された結果の概要が出力されます。
補足)他のGPUアプリの起動手順について
上記のサンプルプログラムのように短いものであれば、ソースコード(*.cu)をnvccでコンパイルして生成されたバイナリを起動する、という単純なファイル構成ですが、本格的な実用GPUアプリの場合には、GPUアプリケーションを起動する手順が異なってきます。
一例をあげると、弊社で出荷実績の多い GROMACS や Amber のGPUバイナリは次のように起動させます。(GPUバイナリの名称は弊社の慣習によるものもあるため、他サイトでは違う名称になる可能性がありますことを予めご了承ください。)
- GROMACS
$ mpirun -np NGPUS gmx_gpu_mpi -nb gpu -pme gpu
GROMACSのGPU版では、non-bonded な計算(-nb)とPME計算(-pme)をGPUに担当させて、残りの処理はCPUに担当させることが多いかと思います。参考 - Amber
$ mpirun -np NGPUS pmemd.cuda_SPFP.MPI
Amberでは全部の処理をGPUに行わせるので、GROMACS の -nb のような分担は行いません。参考
このようにGPU対応アプリの起動コマンド列は、アプリ毎に異なります。ただし、多くの場合、元々の(CPU)アプリの起動方法を、少しだけ変えたコマンドになることが多いです。アプリの使用マニュアルにGPU版の起動方法が書かれているのが普通ですので、それぞれの使用マニュアルを丁寧に読んでみてください。
本当にGPUが使われているのか?を確認する手順(CUDAアプリ共通)
※この節で書かれている内容は、CUDAを使って書かれているGPUアプリであれば共通に当てはまります。
OS上で認識されているGPUデバイス(CUDAで利用可能なデバイス)を一覧表示させるにはdeviceQueryというサンプルプログラムを使うのが簡便です。このプログラムは、上述の CUDA Samples のSamples/1_Utilities/deviceQuery にあります。
同様に make した deviceQuery を実行すると次のような出力が得られます。
$ ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Tesla V100-PCIE-16GB"
CUDA Driver Version / Runtime Version 11.4 / 11.4
CUDA Capability Major/Minor version number: 7.0
Total amount of global memory: 16160 MBytes (16945512448 bytes)
(080) Multiprocessors, (064) CUDA Cores/MP: 5120 CUDA Cores
GPU Max Clock rate: 1380 MHz (1.38 GHz)
Memory Clock rate: 877 Mhz
Memory Bus Width: 4096-bit
L2 Cache Size: 6291456 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 98304 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 7 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 61 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.4, CUDA Runtime Version = 11.4, NumDevs = 1
Result = PASS
GPUの番号ごとに、GPUごとの細かいスペックが列挙されます。大事なのは、GPUの番号がどのGPUに対応しているのかを把握しておくことです。この番号を、CUDAアプリケーションでは「GPUのID」として使います。
もしシステム上に複数の(CUDA対応の)GPUが搭載されている場合には、CUDAアプリ側では、それら全てを利用する機会がデフォルトでは得られます。これに対し「描画は軽量なQuadroで、計算はハイエンドのGPUで」と使い分けたい場合がよくあります。そのとき、CUDAで利用してよいとするGPUの集合を定義することが CUDA_VISIBLE_DEVICES という環境変数で可能です。
CUDA_VISIBLE_DEVICESに何も値を設定しない場合には、システム上で認識されている全ての(CUDA対応の)GPUが利用してよいものとみなされます。CUDA_VISIBLE_DEVICESに1つのGPU IDだけを指定している場合には、その一つだけをCUDAアプリから利用してよいとされます。
例)deviceQueryで “Device 1:” と表示されたものだけをCUDAアプリに利用してよいとする場合
export CUDA_VISIBLE_DEVICES=1CUDA_VISIBLE_DEVICESに複数のGPU IDを指定したい場合には、カンマで区切って、全体をクオーテーションします。
例)ID0 番 と ID1 番をCUDAアプリに利用してよいとする場合
export CUDA_VISIBLE_DEVICES="0,1"
ここで「利用してよいとする」と回りくどい書き方にしているのは、「利用してよい」とされたGPUの中から最終的に実際にどのGPUに対してどの処理を割り当てるかはCUDAアプリ側の実装で決まるためです。
さて、CUDAアプリを動かしている間にNVIDIA GPUの使用状況を確認するには nvidia-smi というコマンドを使います。
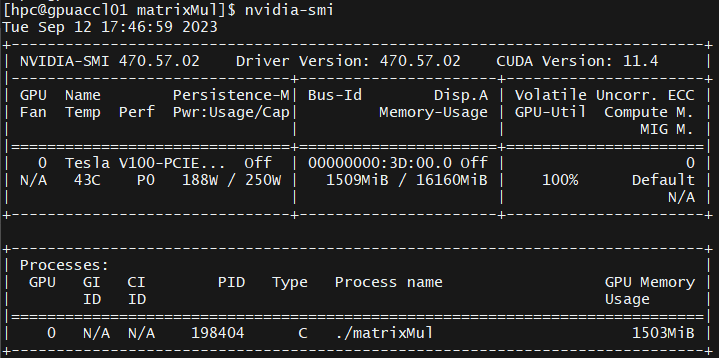
このコマンドは、実行したときのGPUのコアやGPUメモリの使用率を表示してくれます。画面の下の方には、GPU番号とプロセスの名前が表示されていますので、どのプロセスがどのGPUを使っている状況なのかも確認できます。
短時間で終わるCUDAアプリを実行する場合などに、nvidia-smiを実行しつづけて見張りたいことがあります。そんなときは次のようなやり方が可能です。
nvidia-smiの-l SEC (-loop=SEC)オプションでループ実行させる方法
例えば 2秒間隔 で繰り返し出力させるには次のようにします。
$ nvidia-smi -l 2watchコマンドを使ってnvidia-smiコマンド自体を繰り返し起動させる方法
watchコマンドは後ろに指定されたコマンドを一定間隔で繰り返し起動するコマンドです。
例えば 3秒間隔 で繰り返し起動させるには次のようにします。
$ watch -n 3 nvidia-smi
まとめ
以上が、CUDAで書かれたGPUアプリをコンパイルして動かす基本的なやり方です。修得しようとすると時間の掛かるCUDAのプログラミングにはあえて踏み込まずに、動かすということを目標にまとめてみましたが、いかがでしたでしょうか。GPUについて触ってみたいけれども難解なところは踏み込みたくないなぁ、というお客様がGPUに第一歩を踏み出すお手伝いができれば幸いです。
GPUを取り巻く技術はハードウェア・ソフトウェアともにかなり発展してきており、AI向けの回路が増強されたり、以前出来なかったプログラミング作法が可能になったりと、ユーザーのみなさまが追いかけるのも年々大変になりつつあります。お客様の研究開発を加速できるように、弊社のエンジニア一同、日々新しい技術の修得と研鑽に努めてまいります。