はじめに
前回の記事でAWS EC2 M6gインスタンスに使われているGraviton2についての簡単な紹介と、HPLベンチマークの結果を掲載しました。今回はOpenFOAMについてのベンチマーク結果をご紹介します。実のところA1インスタンスの登場時にも同様の検証を行っていましたが、当時はこのブログもなかったので、私が参加した勉強会などのLT等で紹介するにとどまりました。
ベンチマーク内容
これも前回触れましたが、OpenFOAM-v1912をUbuntu20.04LTS標準のgcc-9.3.0, OpenMPI-4.0.3でビルドしました。ベンチマークデータは弊社も賛助会員のオープンCAE学会が公開しているチャネル流ベンチマークです。今回はスケジューラもないので、NoBatch-*ディレクトリにあるものを並列数のみ変更して使用しています。そのためソルバはGAMG-DIC, PCG-DICで、メッシュ数は300万及び37万です。
A1インスタンス(最大16コア)で取得したものも併記しますが、2018年12月に発表直後に取得したデータです。OpenFOAM-v1806, OSはRHEL7.4, gcc-4.8.5, OpenMPI-1.10.7という組み合わせになっています。
結果
それぞれの結果を載せます。グラフの左側が今回のM6gによる結果、右側がA1で取得したものです。付属のツールが吐き出したグラフをそのまま利用していますが、一部体裁が整っていません。読み取るのに少々お手数をおかけしますが、何卒ご了承ください。
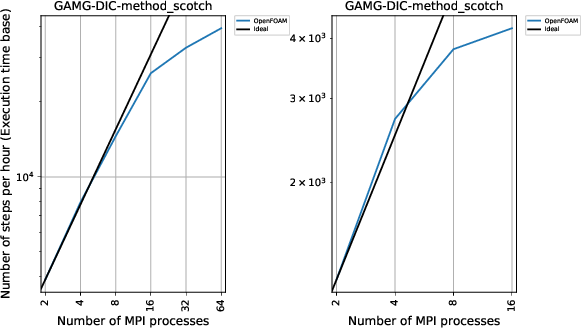
GAMG-DICソルバー 37万メッシュでの1時間あたりのステップ数
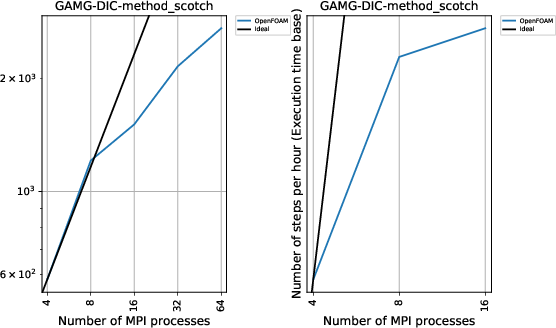
GAMG-DICソルバー 300万メッシュでの1時間あたりのステップ数
A1では8並列あたりで完全に頭打ちになっていたものが、数字的に数倍の性能を叩き出しているにもかかわらず、スケーラビリティが改善しています。
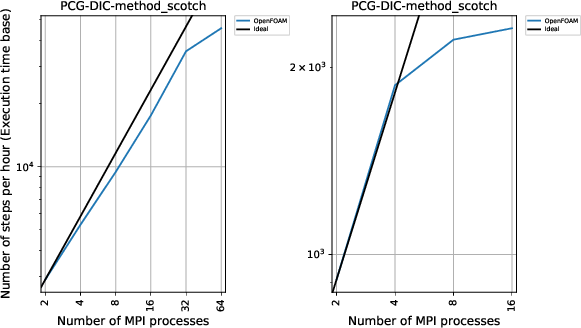
PCG-DICソルバー 37万メッシュでの1時間あたりのステップ数
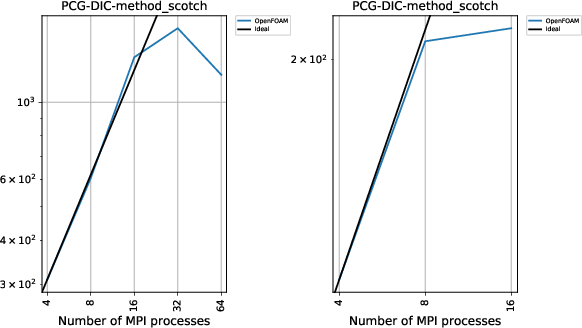
PCG-DICソルバー 300万メッシュでの1時間あたりのステップ数
こちらは更に顕著ですが、やはり絶対性能が大幅改善しているのに32並列までは性能が伸びているので、CPU性能だけでなくメモリ帯域についても著しい改善が施されているようです。
まとめ
Graviton/Graviton2についてのメモリの規格やチャネル数など、具体的なところは明らかにされていないようですが、過去のx86系CPUでもそうだったように、キャッシュの増加及びアルゴリズムの改善がこうした性能に強く寄与します。そこにさらなるチューニングが入り、メモリの絶対性能が向上した場合、強力な計算性能をもつCPUであるように見受けられます。
Intel/AMDもさらなる新製品を投入予定です。Gravitonシリーズはそもそも汎用に安価なサービスを構築するために設計されており、決してHPC向けに設計していないことからゲーム・チェンジはは今後も難しい気はしますが、64個ものコアと256GBものメモリを搭載したマシンが、スポット価格とはいえ1時間150円程度で使えることに驚嘆を禁じえません。
この、OpenBLAS-0.3.9とOpenFOAM-v1912のセットアップ済みAMIは公開可能です。もし、お試しになりたい場合はご連絡ください。使い勝手も従来のx86系と変わりませんし、ARMだからといってハマることはありませんでした。生のARMサーバー機にOSインストール等では少々勝手の違うところがあって、一筋縄では行かないケースもありましたし、性能を絞りだそうとチューニングし始めるとキリがありませんが、クラウド上であればお気軽にお試しが可能です。
それではまたの機会に。