
AMDのAI 向け新GPU製品 Instinct MI300X および Instinct MI300Aの詳細が発表されました。 ネットでは取り上げられなかった 情報も交えて紹介いたします。
■Instinct MI300Xについて

図1 AMD Instinct MI300X 及び MI300A
AMD InstinctMT MI300X は NVIDIA の H100 を凌駕するデータセンタ用の高性能 GPU です。すでに1月のCESの前日基調講演や6月の「Data Center and AI Technology Premiere」で発表されていましたが、今回サンノゼで開催された「AMD Advancing AI」(*1)では詳細な情報や性能を含む正式な発表に加え、Supernicro をはじめとする複数のベンダーからのInstinct MI300X を搭載した8-GPUサーバ等の製品化を紹介し、着実な製品開発が進んでいることを強調しています。
■Instinct MI300シリーズの仕様
発表された仕様をNVIDIAのH100やAMDのInstinct MI250Xと比較してみると、以下の表のようになります。
表1. Instinct MI300シリーズの仕様及びH100/MI250Xとの比較
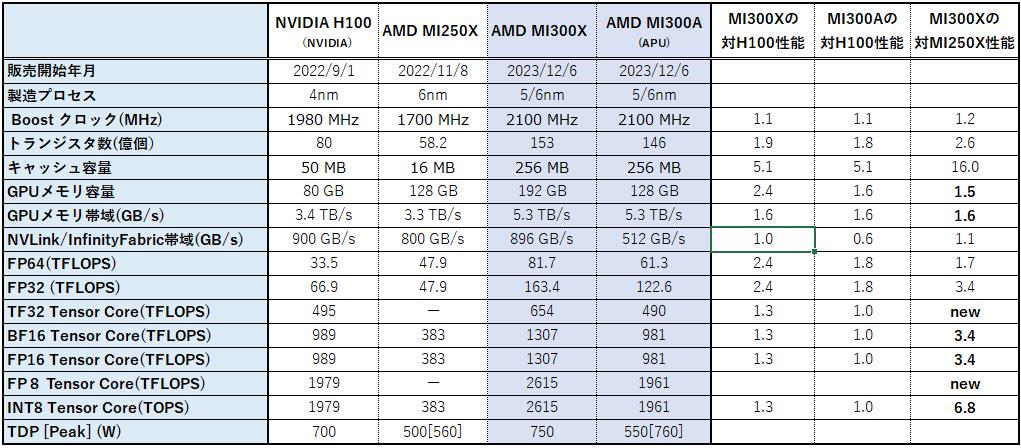
ここから、Instinct MI300XはNVIDIAに対して遅れを取っていた部分をキャッチアップし、NVIDIAの H100をも凌駕するGPUであることが判ると思います。以下、個々に見てみます。
演算性能はH100に対して1.3倍以上のピーク性能を確保しています。MI250XまではTF32やFP8などの型のサポートをしていませんでしたが、MI300シリーズでキャッチアップできています。
GPUメモリはH100に対して搭載するHBM3メモリの個数を増やすことで帯域を上げ1.6倍の性能を達成しています。更に、HBM3メモリ1個あたりの容量を16GBから24GBに増やすことで192GBもの大容量化を実現しています。CPUとのインターフェイスはPCIe 5.0で接続されており、H100と同等です。

図2 MI300Xの紹介(*1からスナップショット)
これは発表の冒頭において MI300X の詳細を説明する最初のスライドです。ここでは AMD の MI250X との比較を行い、大幅な改善が示されていますが、前の表にも表現されていない重要な要素がこのスライドに示されています。
それは「Sparsity」です。日本ではよく「疎性」と訳されていますが、深層学習モデルでは、疎な行列を扱う場合が多く、この特性を利用して計算性能を2倍に向上させる仕掛け「Sparsity」に対応したことをこのスライドは示しています。
「Sparsity(疎性)」の仕掛けを簡単に説明すると、高々半分しか非0のデータがないと仮定して行列の内積計算(乗加算)をする仕掛けです。仮に半分以上に非0のデータがあったとしても、半分以上は無視して0と仮定して計算します。0の掛け算の結果は0なので、乗算や加算をしなくても0と仮定した内積計算が可能です。当然、無視すれば計算結果は本来の値とは異なりますが、深層学習ではドロップアウトという手法があるように、重み行列の一部をマスクし無視(0と仮定)して計算しても学習が可能です。この疎性を利用した加速手法は NVIDIA の A100 などの Ampere 世代で導入された技術であり、詳細は NVIDIA の White Paper(*2) に開示されています。
この「Sparsity(疎性)」機能の有無だけで、従来は AMD の GPU は NVIDIA に対して大規模言語モデルなどの性能で、2倍の性能差を抱えていましたが、今回 AMD でも導入したことで、同じ土俵で戦うことができるようになりました。リサ・スー CEO がこのスライドで 「Sparsity」 のサポートを最初に言及していたことからもその重要性が理解できます。
■大規模GPUサーバに向けて

図3 GPUサーバ内のGPU間接続(*1からスナップショット)
1つのGPUのメモリに入りきらない巨大な深層学習のモデルは複数のGPUで分割し格納します。このような分割されたモデルを学習する場合は、GPU間の通信性能が極めて重要です。H100ではNVLinkが利用でき900GB/sの帯域を確保していますが、MI300XではInfinity Fabricでほぼ同等の896GB/sの帯域を実現しています。これは机上だけの話ではなく、Supermicroをはじめとする複数のベンダーから8-GPUサーバの販売開始が発表(*4,*5,*6)されており、実際に動作し入手可能な技術です。
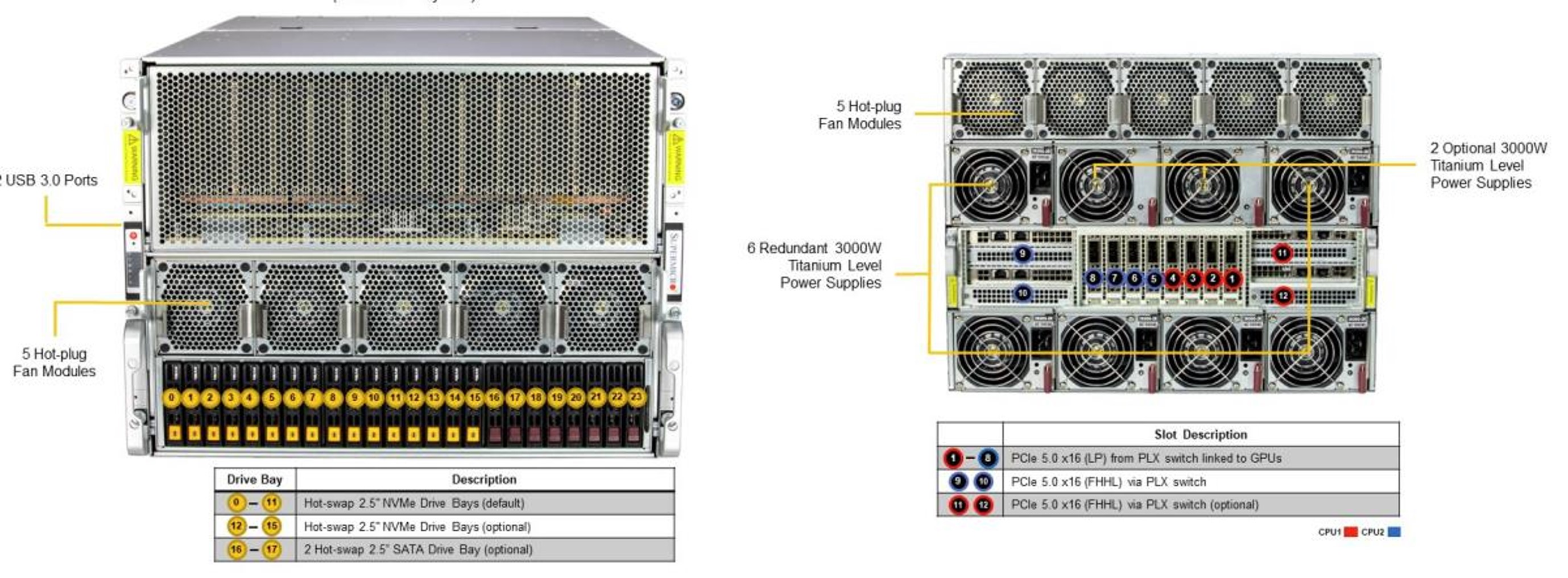
図4 AMD Instinct MI300X を8台搭載するGPUサーバ(*4)
なお、AMDはInfinity Fabricの情報を公開し、BroadcomやCiscoなどと共に、複数のGPUサーバを接続するネットワークとしてEthernet をベースとしたUltra Ethernet を開発するコンソーシアムをこの7月に立ち上げており、オープンな技術かどうかという点でMellanoxを買収したNVIDIAとは実現手法は異なるものの、複数のGPUサーバを高速なネットワークのバックボーンで接続し、巨大なAIサーバクラスタを構築するという目標は同じようです。

図5 GPUサーバ間の接続(*1からスナップショット)
■Instinct MI300Aについて
Instinct MI300A は MI300Xの一部のGPU用のダイ(半導体チップ)をZen4-CPUのダイに置き換え、一つのパッケージにCPUとGPUを同居させたAPU(Accelerated Processing Unit)製品です。APUはCPUとGPUがメモリアドレス空間を共有することで、GPUの計算の前後で必要としていたCPU-GPU間のデータ転送が省略でき高性能化が実現できます。APU製品は従来からAMDのコンシューマー用製品には存在していましたが、今回データセンタ用のAPUとしてMI300Aが初めて登場し、製品の高性能化だけでなく省スペース、省電力、あるいは低価格化に貢献します。
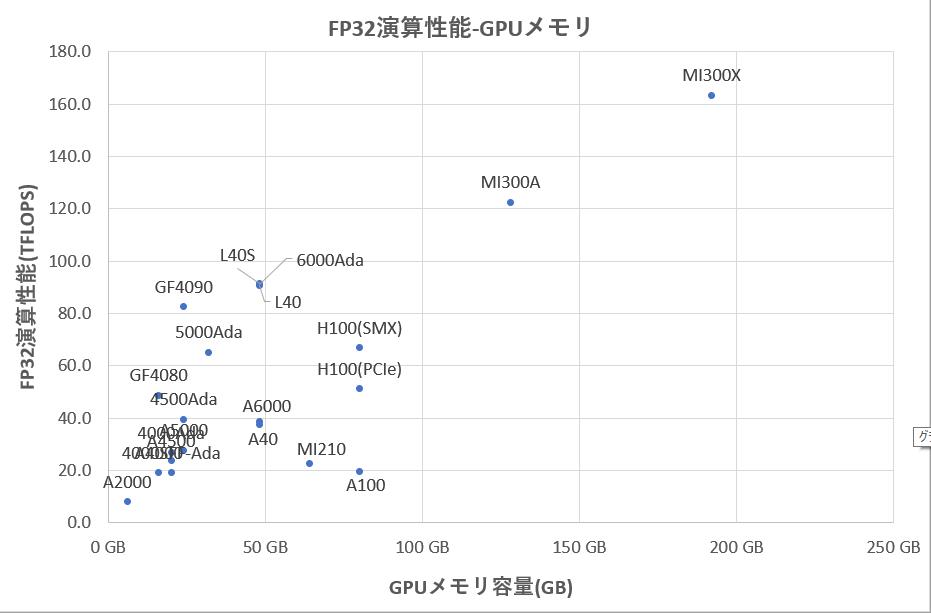
図6 GPUのFP32性能-GPUメモリ容量
MI300AはMI300XよりもGPU性能はやや劣るものの図1や図6から判るように、NVIDIA H100に対しても充分に互角以上の性能を秘めています。このMI300Aを搭載したサーバの製品化も進んでいます(図7)。注意頂きたいのは、APUを搭載したサーバの主記憶はHBM3メモリだけでありDIMMメモリを搭載しメモリを増設することはできないことです(但し4-APU搭載時には512GBもの容量があります)。HBMを搭載したIntelのXeon® CPU Maxでも同様な制約があり、CPUとGPUでHBMのメモリ空間を共有した場合には暫くは避けられず、今後OSが特性の異なるメモリであっても動的に適切に制御できるようになることが期待されます。

図7 AMD Instinct MI300A を4台搭載するGPUサーバ(*5,6)
左:水冷、右:空冷
■最後に
今回の発表はAMDがAIにむけNVIDIAと競合できることを強烈にアピールするものでした。また、最後に達成感からか感極まって言葉を詰まらせるリサ・スーCEOが印象的で、今後AMDがAIに注力すること、AMDのAIが充分に実用可能になることを確信できる発表でした。
当社は昨年AMDのInstinct MI250の性能評価を公開(*7)しています。引き続きAMDのAI製品に着目し、Instinct MI300シリーズの性能評価、製品販売を進めていく所存です。ご期待ください。
■参考資料、引用
1) https://www.amd.com/en/corporate/events/advancing-ai.html
2) https://www.nvidia.com/content/PDF/nvidia-ampere-ga-102-gpu-architecture-whitepaper-v2.pdf
3) https://www.supermicro.com/en/accelerators/amd
4) https://www.supermicro.com/en/products/system/gpu/8u/as-8125gs-tnmr2
5) https://www.supermicro.com/en/products/system/gpu/2u/as-2145gh-tnmr
6) https://www.supermicro.com/en/products/system/gpu/4u/as-4145gh-tnmr
7) https://www.hpc.co.jp/tech-blog/2022/07/29/amd-instinct-mi250-benchmark

