
史上初エクサスケールシステム、Frontier
ISC2022において、発表されたTOP500にて、Frontierが2位の富岳(442.01 PFLOPS)を抜いて、1.102 EFLOPS と、初めて「EFLOPS」の数値を達成して1位となりました。
Frontierは、74台のCray EXキャビネットに9,408ノードを収容し、それぞれにAMD Milan “Trento” 7A53 Epyc CPUを1個とAMD Instinct MI250X GPUを4個搭載して構成されています。総GPU数は 37,632基です。
AMD Instinct MI250
今回は、Frontierで使用しているAMD Instinct MI250Xの下位モデル AMD Instinct MI250を4基搭載のマシン(SuperMicro製 4124GQ-TNMI)をベンチマークする機会を得られました。GPUと言えばNVIDIAという状態が長らく続きましたが、AMDが競合となり得るのか、NVIDIA A100と比較しました。
下表は、ハードウェアスペックの比較です。
| GPU製品名 | AMD Instinct MI250 | NVIDIA A100 SXM4 |
| アーキテクチャ | CDNA 2 | Ampere |
| GCD(Graphic Compute Die)数 | 2 | 1 |
| GPUベースクロック | 800 MHz | 765 MHz |
| GPU boost時クロック | 1700 MHz | 1410 MHz |
| メモリ仕様 | HBM2e | HBM2e |
| メモリインターフェース* | 8192 bit | 5120 bit |
| メモリ帯域幅* | 3200 GB/sec | 2039 GB/sec |
| メモリ容量* | 128 GB | 80 GB |
| 最大消費電力* | 560 W | 400 W |
|
ベクトル演算理論性能* FP64 FP32 FP16 |
45.3 TFLOPS 45.3 TFLOPS 45.3 TFLOPS** |
9.7 TFLOPS 19.5 TFLOPS 78 TFLOPS |
|
行列演算理論性能* FP64 FP32 TF32(スパース性機能) FP16(スパース性機能) |
90.5 TFLOPS 90.5 TFLOPS – 362.1 TFLOPS |
19.5 TFLOPS – 156(312) TFLOPS 312(624)TFLOPS |
| GPU(GCD)間通信 | Infinity Fabric Link | NVLink |
| GPU(GCD)間帯域幅 | 400 GB/sec (8 × 50 GB/sec) | 300 GB/sec(12 × 25 GB/sec) |
*2GCD合わせての数値 **カタログ等に不記載のため推測値
特に注目すべきは三つです。一つ目は、Graphic Compute Die(GCD)です。AMD Instinct MI250は、1つのGPUに2つのダイを有するマルチダイになります。OS上は、2つのGPUに見えることになります(ご存知の方は、Tesla K80を想像して頂ければと思います)。
二つ目は、倍精度(FP64)、単精度(FP32)の性能です。AMD Instinct MI250 の方が NVIDIA A100よりも高い理論性能となっています。AMD Instinct MI250は、GPU計算をHPC分野における位置づけを大きく高めることになるでしょう。
三つ目は、半精度の行列演算理論性能もNVIDIA A100を上回っている点です。理論性能上は、AIにおいても、NVIDIA A100を上回っています。
CNNベンチマーク
今回、AMD Instinct MI250のベンチマークには、AMD Infinity Hubからダウンロードした、コンテナイメージ、amdih/tensorflow:rocm5.0-tf2.7-devに同梱してある、tf_cnn_benchmarks.pyを利用しました。比較対象のNVIDIA A100のマシンは、HGX A100です。ソフトウェアは、NGCからダウンロードした、コンテナイメージ、nvidia/tensorflow:20.11-tf1-py3に同梱してある、nvidia-example/cnnを利用しました。また、バッチサイズは、下表の通りです。すべて1GPUあたり(Instinct MI250 は2GCDあたり)の値です。
| inception-v4 | inception-v3 | resnet-152 | resnet-101 | |
| fp16 | 300 | 560 | 300 | 400 |
| fp32 | 150 | 280 | 150 | 200 |
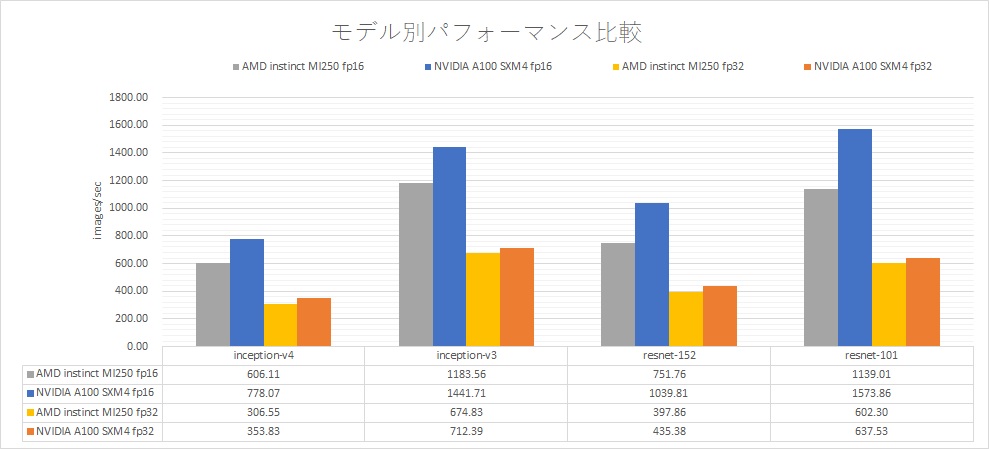
ベンチマークは、1GPU(AMD Instinct MI250は、2GCD)で比較しています。AMD Instinct MI250は、NVIDIA A100に対して、FP16で、A100の72~82%、FP32で、87~94%の性能でした。NVIDIA A100のFP32は自動的にTF32に変換され行列演算を行う状態でベンチマークを行っています。
理論性能は、AMD Instinct MI250は、NVIDIA A100に対して、FP16で、ベクトル演算は、58%程度、行列演算は、116%、FP32では、ベクトル演算は、232%、行列演算は、58%(NVIDIA A100は、TF32を使用するため)となります。ソフトウェアが大きく異なるため、理論性能通りにはならないですが、NVIDIA A100に対して、健闘しているように感じます。特に単精度においては、NVIDIA A100と遜色ないところまで来ています。NVIDIAには、cuDNNという深層学習用のライブラリがあり、ハードウェアに対しての最適化に注力してきた積み上げがありますが、AMDは、HIPというCUDAのAPI互換のライブラリがありますが、深層学習特化のものはなく、深層学習に対して注力してきた実績は特にはありません。こういった背景からも、ハードウェアで少し理論性能を上回っていても、深層学習でNVIDIA GPU以上の実効性能を出す のは、現状では難しいと考えられます。
次に、複数GPUの性能を比較します。それぞれのモデルにおいて、4GPUまで並列でベンチマークしました。
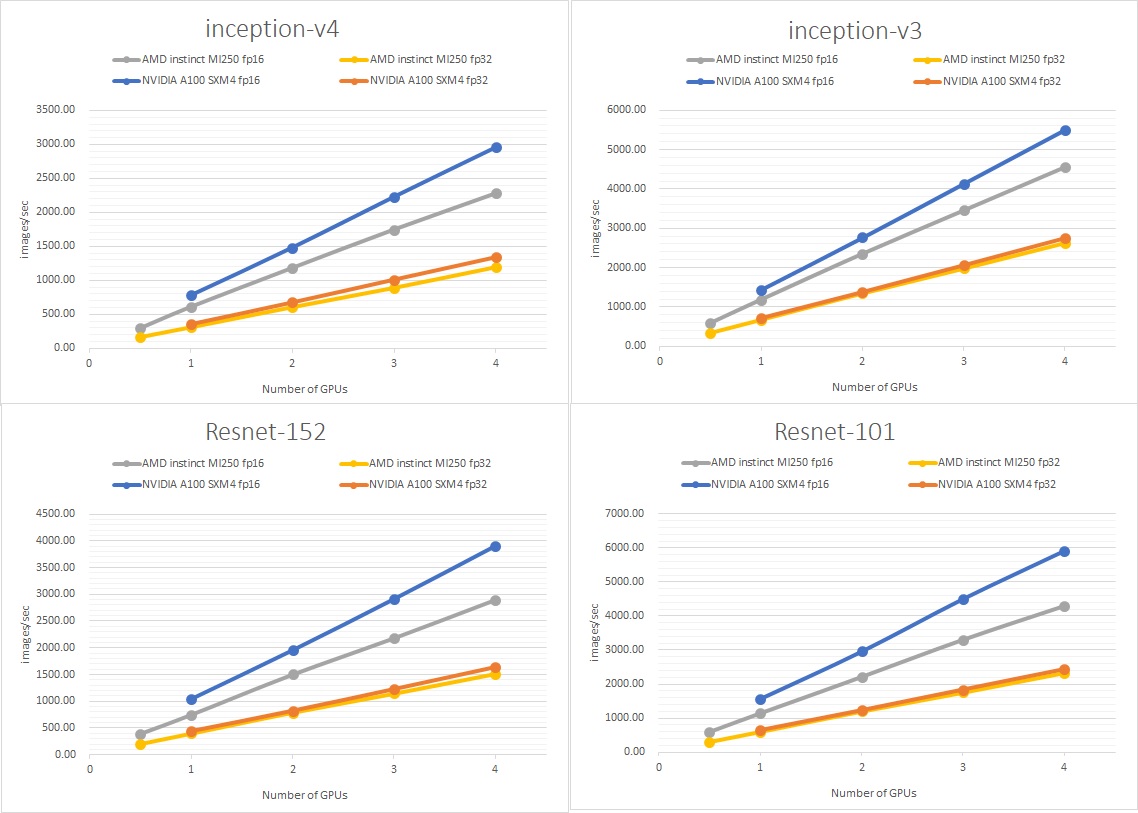
これらの結果を1GPUで規格化してみたのが下のグラフです。すべての系で4GPUまでは順調に伸びています。
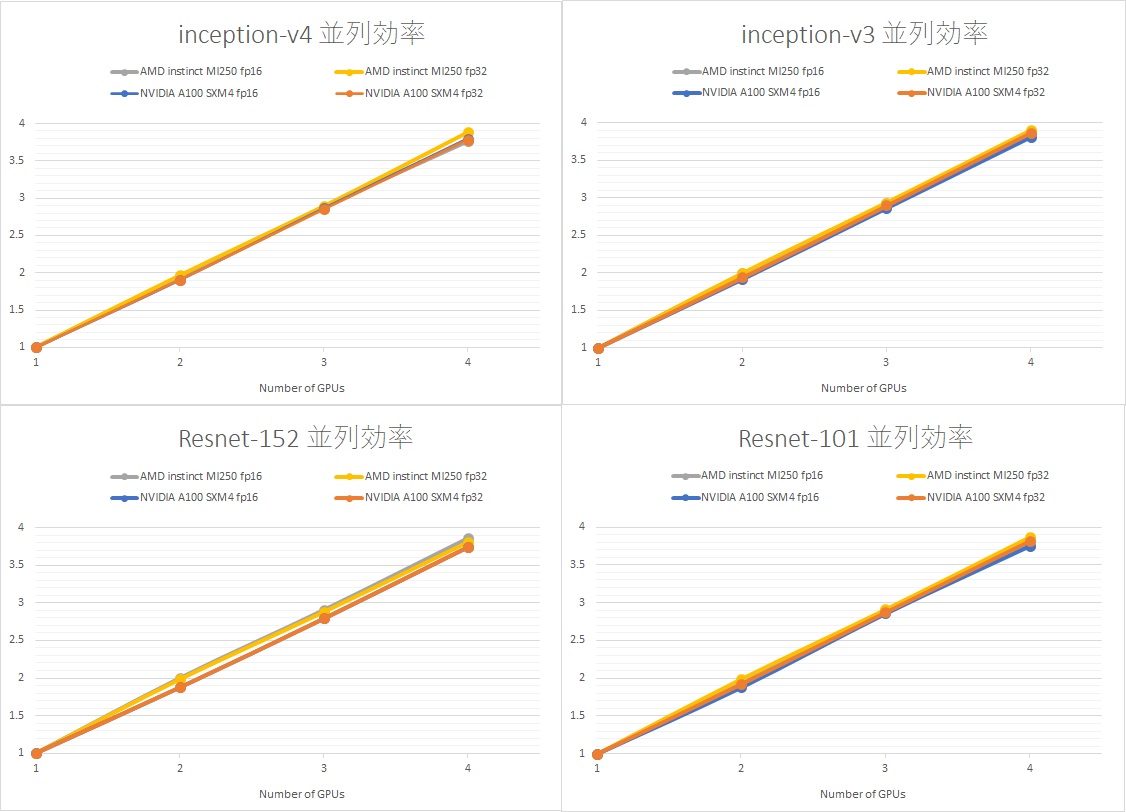
NVIDIA A100と比べて、AMD Instinct MI250のGPU間の帯域幅も遜色ないことが分かります。AMD Instinct MI250のGPU間は、Infinity Fabric Linkで、NVIDIA A100はNVLINKとなっています。NVLINKは、NVSWITCHにより、GPU間は均一な帯域幅が確保されていますが、Infinity Fabric Linkは、スイッチは無く、不均一な帯域幅となります。スイッチを介さない分、帯域幅はNVLinkに劣りますが、4GPUまででは、そこまでの劣化は見られませんでした。
まとめ
史上初エクサスケールシステム、Frontierに搭載されているAMD Instinct MI250Xの下位モデルAMD Instinct MI250 を、CNNベンチマークをしました。理論性能は、NVIDIA A100を上回るものの、実際の深層学習の計算では、NVIDIA A100には敵わないという結果となりました。
