はじめに
Kamonohashiを使用して、どのように機械学習を進めて行けばよいかを、簡単な例を通して紹介します。機械学習に関して知見が十分あり、Kamonohashiの利用方法を知りたい人は、公式チュートリアルを参照ください。
Kamonohashiユーザーのための機械学習講座カリキュラムは下記になります。Kamonohashiのアカウント、GitHub/GitLabのアカウントを有する人が対象です。
- データセットの準備と登録
- サンプルプログラムの準備
- テスト環境での実行
- Kamonohashiで学習
Kamonohashiの利用にあたって、利用端末にDockerがインストールされていること、また、KamonohashiとGitのID、パスワードを有し、利用端末とGitがSSHなどで連携していることを前提とします。説明に使用する環境は、Ubuntu16.04を想定します。Windows端末で利用する場合は、Docker for Windows や Git for Windowsをインストールして利用することになると思いますが、今回は考慮しません。
0.Kamonohashiとは
Kamonohashiとは、機械学習開発のための基盤システムです。機械学習の開発を組織で進めるために開発されたシステムツールです。
Kamonohashiの機能は大きく分けて3つで、「学習マシンリソースの管理と共有」、「学習データの管理と共有」、「学習の実行と履歴の共有」です。また、「学習プログラムの管理と共有」をGitHub/GitLabで、「学習環境の共有」をDockerHub/Docker Registryで行い、それらとKamonohashiが連携し、学習の開発基盤となります。簡単に学習のデータフローを下図に示します。
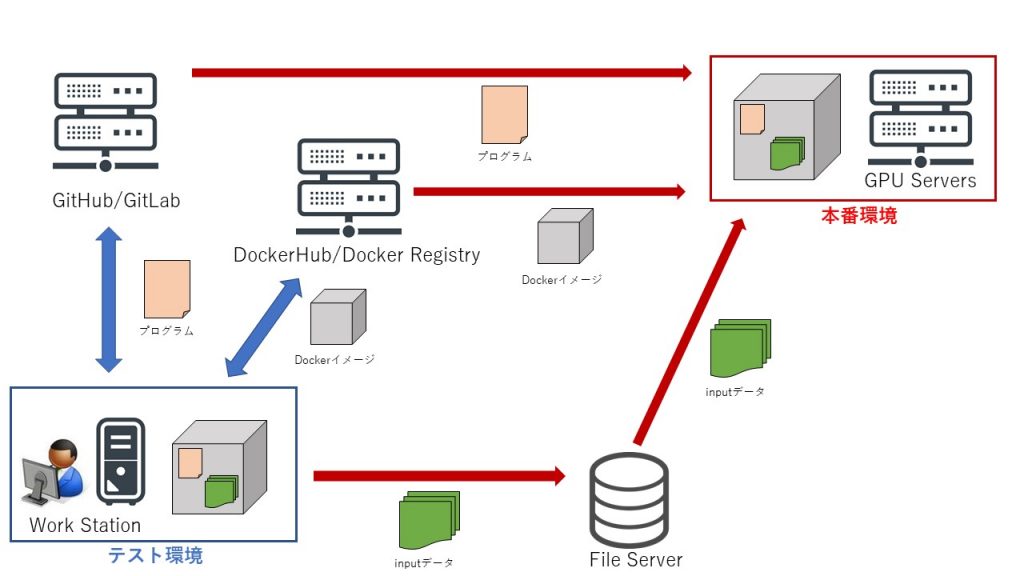
Kamonohashiの利用にあたってのデータフローです。赤矢印部分をKamonohashiで操作します。
図のような形で手元でテストした環境を、本番環境で実行していきます。本番環境で実行する過程で、学習に使用するプログラム、Dockerイメージ、インプットデータを、共有できるようなフローになっています。Kamonohashiは、図中の赤矢印で示した操作をWebブラウザを通して行うことができます。
1. データセットの準備と登録
今回のカリキュラムの前提知識は、Linuxにおいてファイル操作ができること、Kamonohashiにログインできることです。cifar10のデータセット自体は、容易に手に入れることは可能ですが、自前のデータに応用できるように、あえて画像ファイルの状態でデータを準備します。
まず、データセットを準備します。下記コマンドでCifar10のデータセットをダウンロードします。(かなり複雑なコマンドになってしまいましたが、展開されたイメージデータセットを簡単にダウンロードするため編み出された方法です。コマンドの詳細には触れません)
$ docker run --rm -v ./cifar10:/work --entrypoint="" nvidia/digits:6.0 /bin/bash -c 'python -m digits.download_data cifar10 /work'
コマンド実行後、ディレクトリ ./cifar10/train に、airplane、automobile、bird、cat、deer、dog、frog、horse、ship、truckというディレクトリがあり、その中にそれぞれ分類された画像が入っています。下図のような構成になっていることを確認してください。
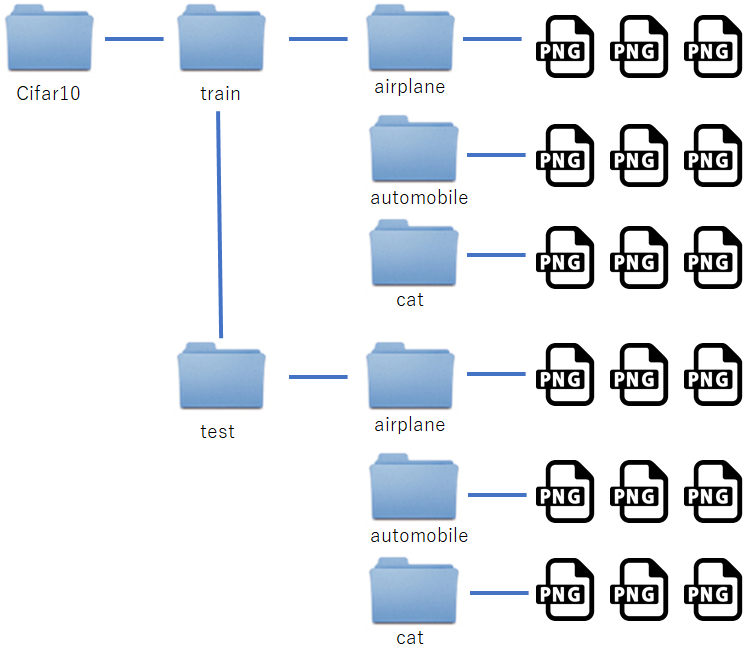
次に、これらのファイルをKamonohashiのデータとして登録します。trainとtestの分類毎にデータ登録していきます。
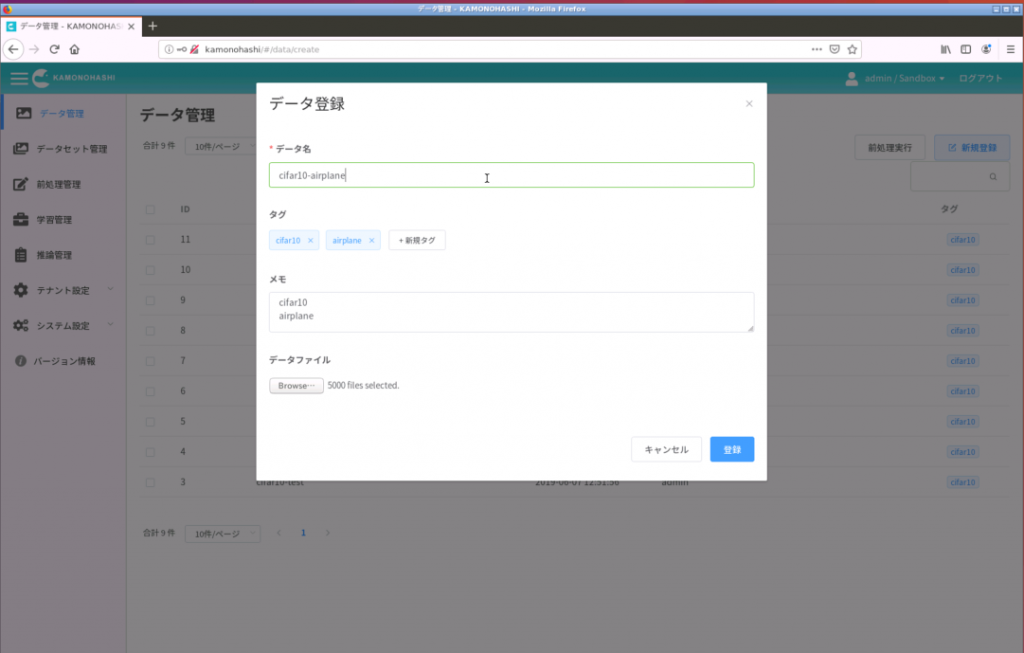
この登録の時に、注意する点があります。Kamonohashiで学習する場合、データのラベルを連携する機能が現在(v1.0.2)ありません。そこで、登録する時に、決められたファイル名のテキストファイル(例えば、label.txt)に、ラベル名を入れて、データとして登録することにします。学習実行する前にデータIDのディレクトリを、ラベルに変更して、学習を実行するようにします。(詳しくは、3.テスト環境での実行 で説明します)
データ登録が終わったら、データセットを作成します。trainのデータをtraining、testのデータをvalidationに登録します。
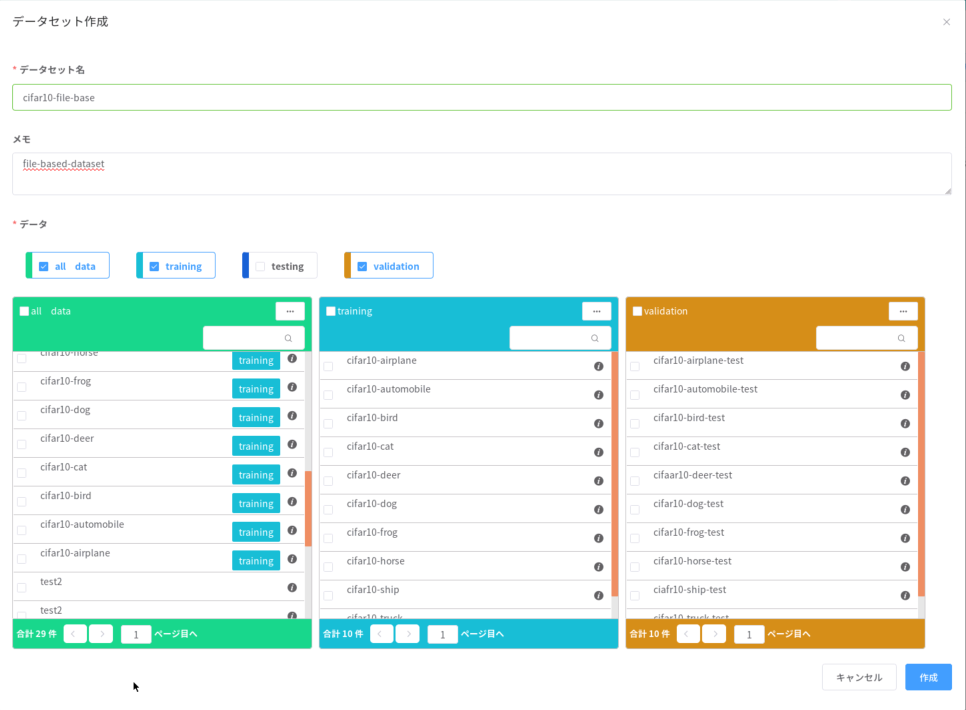
これでデータセットの準備が整いました。
2.サンプルプログラムの準備
次に、サンプルプログラムを用意するカリキュラムに移ります。前提として、gitコマンドの使用方法、ファイルの編集方法を知っていて、GitHubもしくはGitLabにアカウント、レポジトリを有していることとします。
今回は、pytorchのtutorialのプログラムを使用します。このプログラム自体の解説はこちらを参照ください。プログラムはpythonファイル1つなので、コピー&ペーストで持ってくるのが速いです。(もちろん、git clone しても問題はないです)
このプログラムは、pytorchの組み込みのcifar10を用意するクラス、torchvision.datasets.CIFAR10を使用しているので、この部分をファイルベースのデータローダ torchvision.datasets.ImageFolder に変更する必要があります。
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
の部分を、
trainset = torchvision.datasets.ImageFolder(root=train_path, transform=transform)
と変更します。train_pathは、ダウンロードしてきたデータ構造では、cifar10/train にあたり、フォルダ構造によって変更してプログラムを実行します。次節のテストでは、/work/cifar10/trainを指定することになります。testsetに関しても同様の変更を行います。
このプログラムはCPU版です。GPUを使用するには、こちらを参考にしてください。
3.テスト環境での実行
データセットとプログラムが用意できたので、一度、手元の環境で試してみましょう。今回はpytorchのプログラムなので、公式のpytorchのDockerイメージを使用します。まずはDockerコンテナにログインして、変更したコマンドの実行など試してみましょう。
下記コマンドで、ホストのカレントディレクトリ($PWD)を、コンテナ内の/workにマウントした、pytorch/pytorch:0.4.1-cuda9-cudnn7-runtime コンテナに、ログインできます。
$ docker run -it -v $PWD:/work pytorch/pytorch:0.4.1-cuda9-cudnn7-runtime /bin/bash
コンテナ内にログインできたら、下記コマンドで実行します。
# python /work/cifar10_tutorial.py
ここで、cifar10_tutorial.pyが用意したプログラムになります。もし実行でエラーになったら、サンプルプログラムを見直して修正することになります。Dockerの扱い方などは、弊社のマニュアルなどを参照ください。
正常に実行できたら、プログラムをGitHub/GitLabに登録するのですが、その前にもう少しするべきことがあります。Kamonohashiで実行する場合、フォルダ構造が変わります。学習時の詳しいフォルダ構造を公式サイトから転載します。
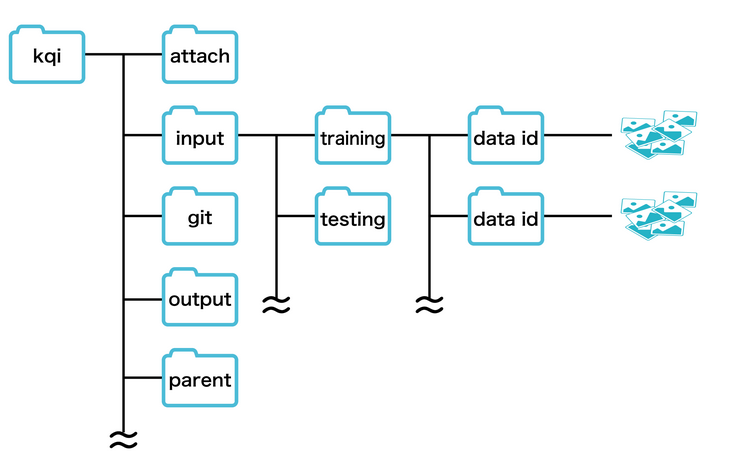
データセットの準備でも触れましたが、Kamonohashiにはデータのラベルを連携する機能がありません。そこで、「label.txt」というテキストファイルにラベル名を書いて、データに保存します。その後、プログラム側で、「label.txt」のラベル名を抽出して、データIDディレクトリをラベル名に変更します。その実行のためのコードを下記します。
import os
import re
inputdir = '/kqi/input/'
datasets = ['training','validation']
for dataset in datasets:
d = inputdir + dataset + '/'
for i in os.listdir(d):
di = d + i
txt = di + '/label.txt'
f = open(txt,'r')
label = f.readline()
label = re.sub('\W','',label)
f.close
os.rename( di , d + label )
このコードを実行するプログラムの先頭に付けます。また、前節のtrainsetとtestsetの、train_pathの部分を、/kqi/input/trainingに変更して、GitHub/GitLabに登録します。
これにより学習の準備が整いました。次は、Kamonohahshiでの学習を行います。

