
NVIDIA GH200 の機械学習ベンチマーク報告書をこちらで公開しました。報告書の中では、NVIDIA H100-PCIEと A6000 を加えた計3種のGPUで、機械学習の学習性能を比較評価しています。
スペック情報
NVIDIA GH200、NVIDIA H100-PCIE、NVIDIA A6000 のスペック比較表は次のとおりです。
| GPU型番 | NVIDIA GH200 | NVIDIA H100-PCIE | NVIDIA A6000 |
| アーキテクチャ | Hopper | Hopper | Ampere |
| GPU ベースクロック | 990 MHz | ||
| GPU Boost 時クロック | 1755 MHz | ||
| CUDA コア数 | 14592 | 10752 | |
| TensorCore 数 | 456 | 336 | |
| メモリ仕様 | HBM3e | HBM2e | GDDR6 |
| メモリインタフェース | 5120 bit | 5120 bit | 384 bit |
| メモリ帯域 | 4000 GB/sec | 2000 GB/sec | 768 GB/s |
| メモリ容量 | 96 GB | 80 GB | 48 GB |
| 最大消費電力 | 1000 W | 350 W | 300 W |
| FP64 理論性能 | 34 TFLOPS | 48 TFLOPS | 38.7 TFLOPS |
| FP32 理論性能 | 67 TFLOPS | 48 TFLOPS | 38.7 TFLOPS |
| FP16 理論性能 | 134 TFLOPS | 96 TFLOPS | 19.4 TOPS |
| TensorCore FP64 理論性能 | 67 TFLOPS | 48 TFLOPS | |
| TensorCore FP16 理論性能 (スパース性機能) |
990 TFLOPS (1979 TFLOPS) |
800 TFLOPS (1600 TFLOPS) |
154.8 TFLOPS (309.6 TFLOPS) |
| TensorCore TF32 理論性能 (スパース性機能) |
494 TFLOPS (989 TFLOPS) |
400 TFLOPS (800 TFLOPS) |
77.4 TFLOPS (154.8 TFLOPS) |
| TensorCore FP8 理論性能 (スパース性機能) |
1979 TFLOPS (3958 TFLOPS) |
1600 TFLOPS (3200 TFLOPS) |
309.7 TOPS (619.4 TOPS) |
抜粋:CNNベンチマーク結果
NVIDIA GPU Cloud(以下、NGC)よりダウンロードしたTensorFlow のDocker イメージを使用してCNNのベンチマークを取得しました。NVIDIA H100-PCIE は、nvcr.io/nvidia/tensorflow:22.09-tf1-py3 をフレームワークとして使用したデータ、NVIDIA GH200 は、nvcr.io/nvidia/tensorflow:24.03-tf1-py3 をフレームワークとしてベンチマークを取得しました。ベンチマークには、コンテナイメージに同梱のnvidia-example/cnn を用いました。その中の2条件のベンチマーク結果を示します。ベンチマークを取得した際のバッチサイズは、inception v4 はバッチサイズ256、inception_resnet v2 はバッチサイズ128 です。
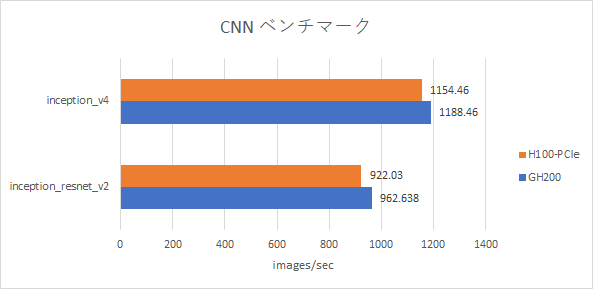
GH200 の性能が、H100-PCIE と同じ程度ということが分かりました。また、このベンチマークではCPU側のメモリを使用している様子は見られず、H100-PCIE と同程度のバッチサイズの下で、メモリエラーで落ちることを確認しました。検証した時点では、CPU メモリは何かしらの特別な方法を使用しない限り使用できないようです。
続きはベンチマーク報告書で
ベンチマーク報告書では、CNNに加えて、LoRAにおけるCPU offload有効無効の影響についてもベンチマークを取得・報告しています。
公開されている情報だけからでは、性能を予測するのは困難です。実際の性能が気になる方は、こちらのリンクからベンチマーク報告書をダウンロードしてご確認ください。
