
概要
深層学習にGPUが好適とよく言われていますが、比較的安価なGPUからハイエンドのものまで様々なGPUがある中で、深層学習計算の高速化にどのようなハードウェア構成が適しているのでしょうか。GPUのスペックを見ると、理論性能値に加えてGPUメモリ容量、GPUメモリ帯域幅も様々ですし、複数GPU間の高速通信を可能とするNVLinkもあります。これらの選択肢がある中で、どの指標を優先的に考慮すべきなのでしょうか。
本稿では、DNNの学習計算について、ベンチマーク結果からその答えを導いてみます。
ベンチマーク環境
本稿で用いるデータは弊社内で過去に取得したベンチマークからとなりますため、2024年現在の現行世代からは古くなっております。NVIDIA社Tesla V100 PCIe、TITAN RTX、GeForce RTX 2080 Tiを使用したデータとなります。しかしながら、GPUやチップセットのアーキテクチャが根本的に変わらない限り、本稿の結論が比較的新しい環境においてもおおよそ当てはまると考えています。
表 1 GPUスペック比較表
| GPU | Tesla V100 PCIe | TITAN RTX | RTX 2080 Ti |
| アーキテクチャ | Volta | Turing | Turing |
| GPUベース クロック | 1245 MHz | 1350 MHz | 1350 MHz |
| GPU boost時 クロック | 1370 MHz | 1770 MHz | 1545 MHz |
| CUDAコア | 5120 | 4608 | 4352 |
| TensorCore | 640 | 576 | 544 |
| メモリ仕様 | HBM2 | GDDR6 | GDDR6 |
| メモリインターフェース | 4096 bit | 384 bit | 352 bit |
| メモリ帯域幅 | 900 GB/sec | 672 GB/sec | 616 GB/sec |
| メモリ容量 | 16 GB | 24 GB | 11 GB |
| 最大消費電力 | 250 W | 280 W | 250 W |
| 倍精度理論性能 | 7.0 TFLOPS | ||
| 単精度理論性能 | 14.0 TFLOPS | 16.3 TFLOPS | 13.4 TFLOPS |
| TensorCore理論性能 | 112.0 TFLOPS | 130.5 TFLOPS | 107.2 TFLOPS |
DNNのベンチマークには、V100のみTensorFlowのバージョン18.07、それ以外はバージョン18.09を用いました。この環境ではfp16(半精度)の計算においてTensorCoreが自動的に使用されるようになっています。また、学習におけるバッチサイズは、GPUメモリ容量に応じてバッチサイズを変更して、できるだけ学習性能が高い結果を採用しました。
表 2 Tesla V100 PCIe (16GB)、TITAN RTX (24GB)のバッチサイズ
| inception-resnet-v2 | inception-v3 | inception-v4 | resnet-101 | resnet-152 | |
| fp16 | 128 | 256 | 128 | 200 | 128 |
| fp32 | 64 | 128 | 64 | 100 | 64 |
表 3 RTX 2080 Ti (11GB)のバッチサイズ
| inception-resnet-v2 | inception-v3 | inception-v4 | resnet-101 | resnet-152 | |
| fp16 | 64 | 128 | 64 | 96 | 64 |
| fp32 | 32 | 64 | 32 | 48 | 32 |
TensorFlow学習性能(GPU1枚使用時)
モデル別の学習性能ベンチマーク結果を次図に示します。
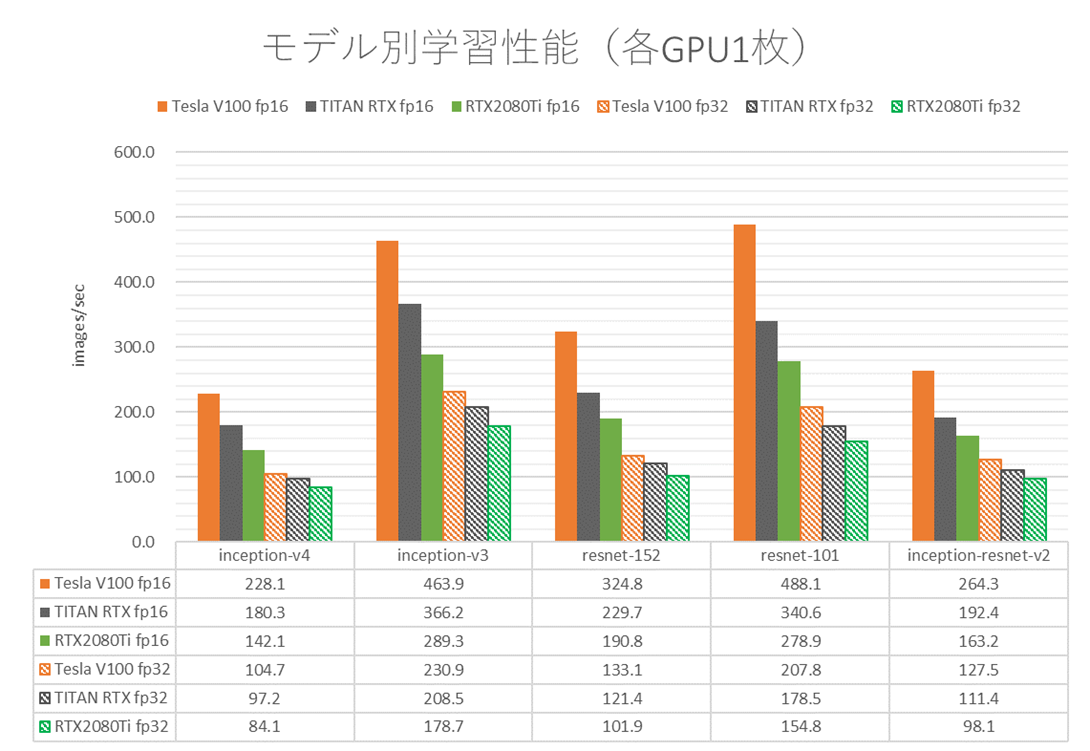
図 1 モデル別学習性能(各GPU1枚)
いずれのモデルにおいても、fp16・fp32とも、Tesla V100 PCIe > TITAN RTX > RTX 2080 Tiという学習性能となりました。
上述の表1のスペックを見てみましょう。fp16で使われるTensorCoreの理論性能や、fp32(単精度)の理論性能はいかがでしょうか?TITAN RTXが一番高くなっていますね。それに対し、DNN学習計算のベンチマーク結果では、TITAN RTXをTesla V100 PCIeが凌駕しています。
このような結果になった大きな理由は、DNNの学習計算がメモリ帯域で支配される(memory-boundな)ワークロードであるためです。表1をメモリ帯域の視点で見ると、Tesla V100 PCIeがHBM2を採用しており、メモリ帯域幅が900 GB/secと断トツに高くなっています。一方、TITAN RTXやRTX 2080 TiはGDDR6を採用しており、メモリ帯域幅はそれぞれ672 GB/sec、616 GB/secと、Tesla V100 PCIeに比べると細いです。いかにCUDAコアやTensorCoreの演算性能が高くとも、演算に必要なデータをGPU上のメモリから供給する速度が遅ければ、全体としてDNN学習計算が遅くなってしまうことが読み取れます。
TensorFlow学習性能(GPU2枚使用時)
PCIe接続(単方向16 GB/sec)でGPU 2枚並列実行した際の学習性能を比較してみます。Resnet-152モデルでfp16の結果を抜粋して掲載します。図2には絶対性能を、図3には各GPUの1枚を用いたときの学習性能を1としたときの性能向上率を示しています。
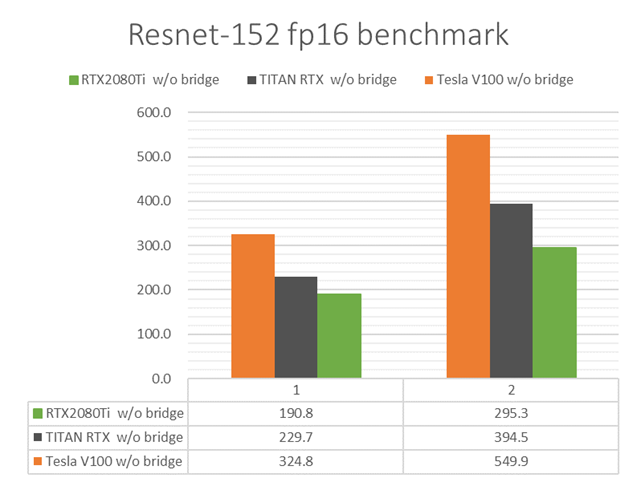
図 2 PCIe接続GPU複数枚でのResnet-152学習性能
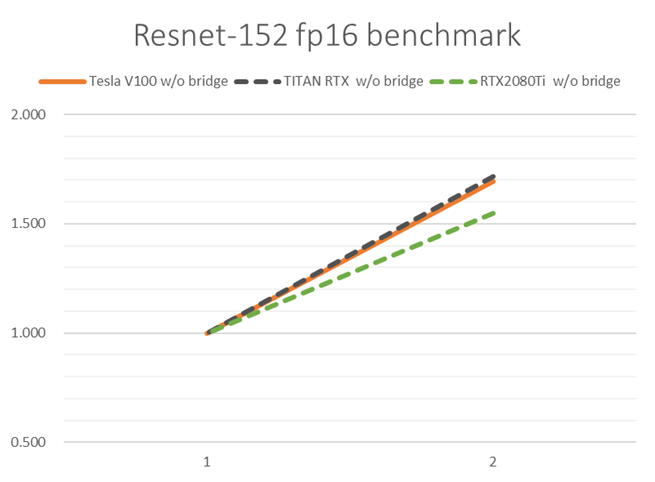
図 3 PCIe接続GPU複数枚でのResnet-152性能向上率
いずれのGPUにおいても2枚使用によってDNN学習計算が高速化されています。ただし、図3を見ると、Tesla V100 PCIe・TITAN RTXに比べて、RTX 2080 Tiにおいて2枚使用時の性能向上率が低いことがわかります。どのGPUも同じ速度のPCIeで繋いでいるのに、なぜ性能向上率に差異が出るのでしょうか。
この差は、DNN学習計算の際に用いたバッチサイズに原因があります。同じ学習データ・同じモデルにおいて、バッチサイズが小さくなると、DNN学習計算中の誤差逆伝播の回数が多くなります。全GPUに誤差を逆伝播させる回数が多くなるということは、GPU間の通信回数(通信量のオーダーは数百MBになりえます)が増えることになりますので、その通信時間が多く掛かることになって、全体の学習速度は低下します。
RTX 2080 Tiでのバッチサイズが小さかった理由は、RTX 2080 Ti の搭載メモリ量が他GPUに比べて小さかったため、GPU1枚あたりのバッチサイズを大きくできなかったためです(表2・表3)。すなわち、複数GPU並列でDNN学習計算を速めたいときは、なるべくGPU1枚あたりのバッチサイズを大きくできるように、搭載メモリ量の大きいGPUを選ぶことが効果的です。
※バッチサイズは学習において正答率を左右してしまうハイパーパラメータです。大きくすることが正答率に悪影響が出る場合もありますので使用にはご注意ください。
NVLink Bridgeの活用
 物理的に隣接するGPU間で高速なNVLink接続を可能とするNVLink Bridge(最大100 GB/sec)を追加して、上述のGPU2枚使用時のDNN学習性能が速くなることを確認してみました。
物理的に隣接するGPU間で高速なNVLink接続を可能とするNVLink Bridge(最大100 GB/sec)を追加して、上述のGPU2枚使用時のDNN学習性能が速くなることを確認してみました。
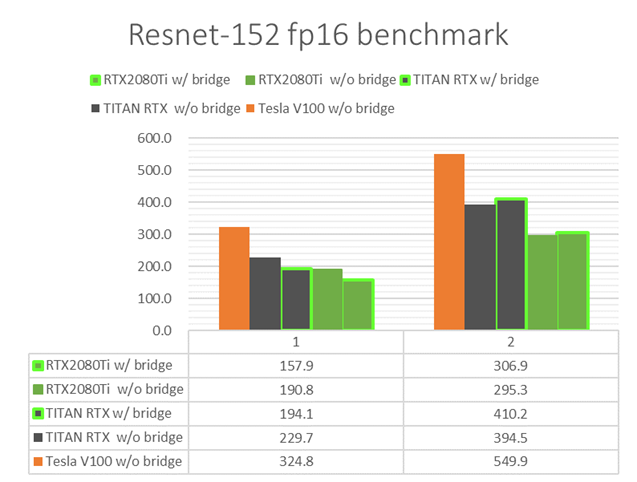
図 4 PCIe接続・NVLink接続GPU複数枚での学習性能比較
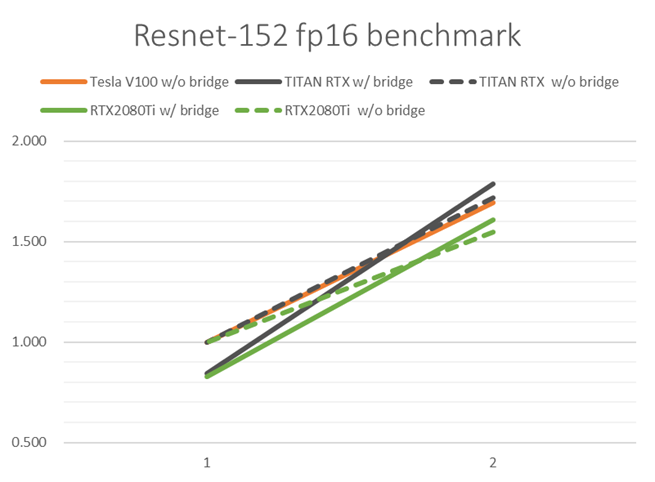 図 5 PCIe接続・NVLink接続GPU複数枚での性能向上率比較
図 5 PCIe接続・NVLink接続GPU複数枚での性能向上率比較
当時、原因を特定しきれませんでしたが、NVLink Bridgeを挿すだけで1GPU実行時のDNN学習性能が低下する現象が起きていました。とはいえ、NVLink接続したGPU 2枚を用いたDNN学習計算は確かに高速化され、性能向上率が改善したことを確認できました(図5)。PCIeに比べてNVLink接続で帯域が太くなったことで、誤差逆伝播におけるGPU間通信時間が短縮されたことによります。
余談になりますが、NVLink BridgeでGPUを繋いでも、複数のGPUが1GPUにはなりません。GPU間の通信速度は向上しますが、GPU間の通信が無くなるわけではありません。これについては以前の投稿で詳しく解説していますので、興味があればご一読ください。
Takeaway
以上から、高速なDNN学習計算のためのハードウェア構成ポイントをまとめます。以下昇順で、優先的に考慮してください。
1.GPU単体性能を向上させるため、GPUのコア・TensorCoreの性能をしっかりと発揮させられるように、GPU上に太いメモリ帯域幅が備わっていることが重要です。GPUスペック表を見て、メモリ帯域幅が太いGPUを選びましょう。わかりやすい見方を挙げると、メモリ仕様に「HBM〇〇」と書かれていれば、そのGPUはHigh Bandwidth Memoryを採用していますので、メモリ帯域幅が太いです。
2.複数枚GPU並列を行う場合には、時間の掛かるGPU間通信の回数をなるべく減らすため、バッチサイズを大きくできるように、GPU1枚あたりのメモリ搭載量が大きいGPUを選びましょう。
3.複数枚GPU並列時に発生するGPU間通信の時間を短縮させるため、GPU間の通信帯域を太くするためにGPU間をNVLink接続することを検討しましょう。GPUによっては、NVLink Bridgeという、GPUの間に「橋」を掛けるようにNVLink接続を可能とする部品を取り付け可能なものがあります。このNVLink Bridgeの装着可否は、計算機筐体の空間的余裕も鑑みて判断する必要がありますので、弊社計算機へのNVLink Bridge装着可否は弊社営業までお問い合わせください。

