サイバーエージェントは5月17日、最大68億パラメータの日本語LLM(大規模言語モデル)を一般公開した。複数のモデルがあり、パラメータは1億6000万から最大68億まである。AI関連のコミュニティーWebサイト「HuggingFace」で配布しており、ライセンスはCC BY-SA-4.0で、商用・研究目的で自由に利用できる。

同社によると「このモデルは日本国内における現行の公開モデルにおいて最大級の規模(17日時点)」という。このモデルをベースに対話型AIなどの開発もできるため、同社は多くの人たちに日本語の自然言語処理に関する最先端の研究開発に取り組んでほしいとしている。
ということなので、open-calm-7b(68億パラメータ)のモデルを動かしてみました。
DGX-1に最近リリースされたDGX-OS6をクリーンインストールした環境で動かしてみます。
$ sudo apt install python3,python3-pip
$ mkdir open-calm-7b
$ cd open-calm-7b
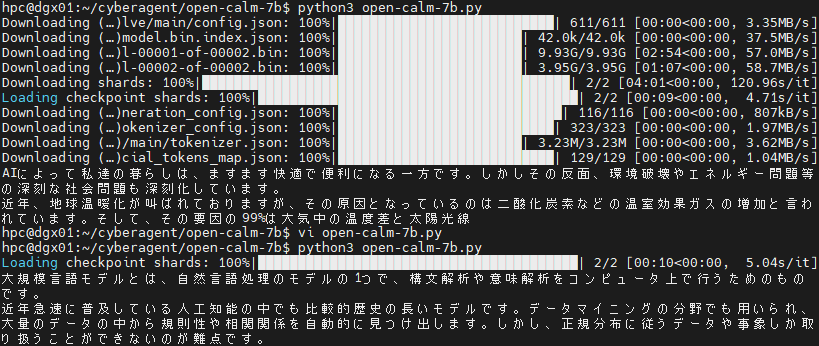
サンプルプログラムをUsageからコピペし実行。2回目は、例文を”大規模言語モデルとは、“に変更しました。
$ vi open-calm-7b.py
$ pip install torch transformers accelerate
$ python3 open-calm-7b.py
※モデルのダウンロードに時間がかかります。2回目の実行は10秒程度です。
フリーでしかも商用利用できる環境がやってきました。ChatGPTなど海外本家は日本語に弱い部分がありますが、国産モデルなら本家を超える成果を期待できるかもしれません。