※2023年5月17日に改めて公開いたしました。
ベンチマーク報告書(PDF)のダウンロードはこちらからどうぞ!
概要
2023年1月10日(日本時間11日)、第4世代 インテル🄬 Xeon🄬 スケーラブル・プロセッサー(開発コード名:Sapphire Rapids)がリリースされました。「Intel 7」製造プロセスにより微細化され、1ソケットに最大56コアを搭載可能になったことに加え、CPU間のUPI接続がCPUあたり最大4本に増加し、その速度が16 GT/sに向上しました。また、新たにDDR5-4800のメモリに対応して、より太いメモリ帯域に進化しました。さらに、データ移動のための専用アクセラレータData Streaming Accelerator(DSA)や、DL推論の速度向上に寄与するAdvanced Matrix Extensions(AMX)命令、AVX-512命令に半精度(FP16)に対応した命令が新たに追加された他、Gen 5.0に対応したPCIeレーンが80本搭載される等、AI・HPCワークロード向けに大きく機能強化されています。
第4世代 インテル🄬 Xeon🄬 スケーラブル・プロセッサーの性能を調査するため、第4世代 インテル🄬 Xeon🄬 スケーラブル・プロセッサーの2ソケットマシンと、第3世代 インテル🄬 Xeon® スケーラブル・プロセッサー(Ice Lakeアーキテクチャ)の2ソケットマシンとで、各種アプリケーションのベンチマークを実施して実効性能を比較しました。
ここではそのベンチマーク結果の一部をご紹介します。この他のアプリケーションのベンチマーク結果や補足情報を含む全文は、こちらからお申込みいただきますとPDFをダウンロードいただけます。
第4世代 インテル🄬 Xeon🄬 スケーラブル・プロセッサーの特長

- 「Intel 7」製造プロセスにより微細化され、トップビンのSKU「Xeon Platinum 8480+」では1ソケットに56コアを搭載しています。これは前世代(最大40コア)の1.4倍です。
- CPUソケット間の接続に用いられるUPIが、CPUあたり最大4本に増加しました(前世代は最大3本)。また、UPI 2.0となり、速度が16 GT/sに向上しました(前世代は11.2 GT/s)。
- AI系ワークロードの加速に有益なAdvanced Matrix Extensions(AMX)命令が搭載されました。これにより前世代の2倍以上のDL推論性能が実現されると期待されます。
- ストリーミング型データ移動のためのアクセラレータData Streaming Accelerator(DSA)が組み込まれ、CPUからDSAへメモリ間データ移動をオフロードする機能が搭載されました。この機能を用いた場合は、データ移動に要していたCPUサイクルが解放され、優先度の高い作業にその空いたCPUサイクルを割り当てることが可能となります。DSAには高性能ストレージ等の用途が見込まれます。
- ソフトウェアとアクセラレータの間でユーザー空間での低レイテンシなディスパッチ・同期を行えるようにするためのAccelerator Interfacing Architecture(AiA)が採用されています。
- AVX-512命令に半精度(FP16)に対応した命令が新たに追加されました。
- 暗号化やデータの圧縮/解凍のためのIntel QuickAssist Technologyが搭載されました。
- コア間で共有される、最大100MB以上のLast Level Cacheが搭載されます。
- Intel EMIB(Embedded Multi-die Interconnect Bridge)シリコンブリッジ技術を用いて作られた初めての製品です。これにより高スループットと広帯域を実現します。
- 1ソケット、2ソケット、4ソケット、8ソケット構成が可能なSKUがラインアップされています。ちなみに前世代は1ソケットと2ソケット構成のみ対応していました。
- CPUあたりのメモリチャンネル数は前世代と同じ8本ですが、新たにDDR5-4800 MT/sのメモリに対応しました。
- メモリ帯域に敏感なワークロードのために、64GB容量で1TB/sの帯域を有するHBM2e(広帯域メモリ)を備えたものが登場する予定です。
- Gen 5.0に対応したPCIeレーンが80本搭載されました。
- Intel Optane Persistent Memory 300シリーズに対応しました。
- Compute Express Link(CXL)1.1 に対応し、ソケットあたり4つのCXLデバイスに対応しています。
- PCHには新たに1本の1GbEポートが追加されました。
HPL
HPLはスーパーコンピュータの性能ランキング『TOP500』で用いられているベンチマークプログラムです。連立方程式の解を求めるプログラムで、浮動小数点演算の性能をFLOPS単位、つまり1秒間に処理できる浮動小数点演算命令の数で性能を評価します。HPLは演算インテンシブなベンチマークとして知られており、CPUの浮動小数点演算性能を把握するべく使用しました。
HPLはIntel oneAPI Base & HPC Toolkit Classic CompilerでAVX-512とAVX2とAVXのCPU最適化オプションを有効にしてビルドしたものでベンチマークを実施しました。結果を次に示します。このHPL結果では1ノードの全コアを使用したピーク時の実効性能を記載しています。
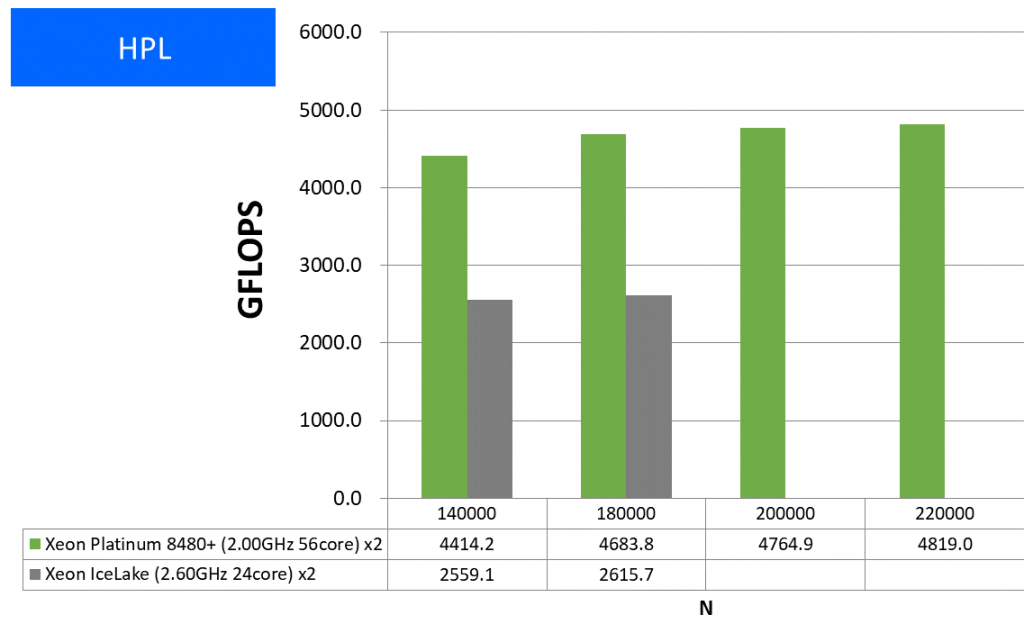
特長:コア数増大に応じた浮動小数点演算性能を達成
Ice Lake環境との性能比がN=180,000において1.79倍となっており、大きく性能向上したことが確認できました。演算インテンシブなプログラムにおける実効性能向上の目安として捉えていただければと思います。
STREAM (Triad)
STREAMはメモリ帯域性能の測定に多用されているベンチマークプログラムです。その中でもTriadというプログラムは巨大な一次元ベクトルの積和を行うOpenMP並列プログラムで、並列動作させてメモリ入出力のノード全体帯域を測定します。
STREAMはoneAPI Base & HPC Toolkit Classic CompilerでAVX-512最適化オプションを有効にしてビルドしたものでベンチマークを実施しました。1ノードでのピーク時の結果は以下となりました。
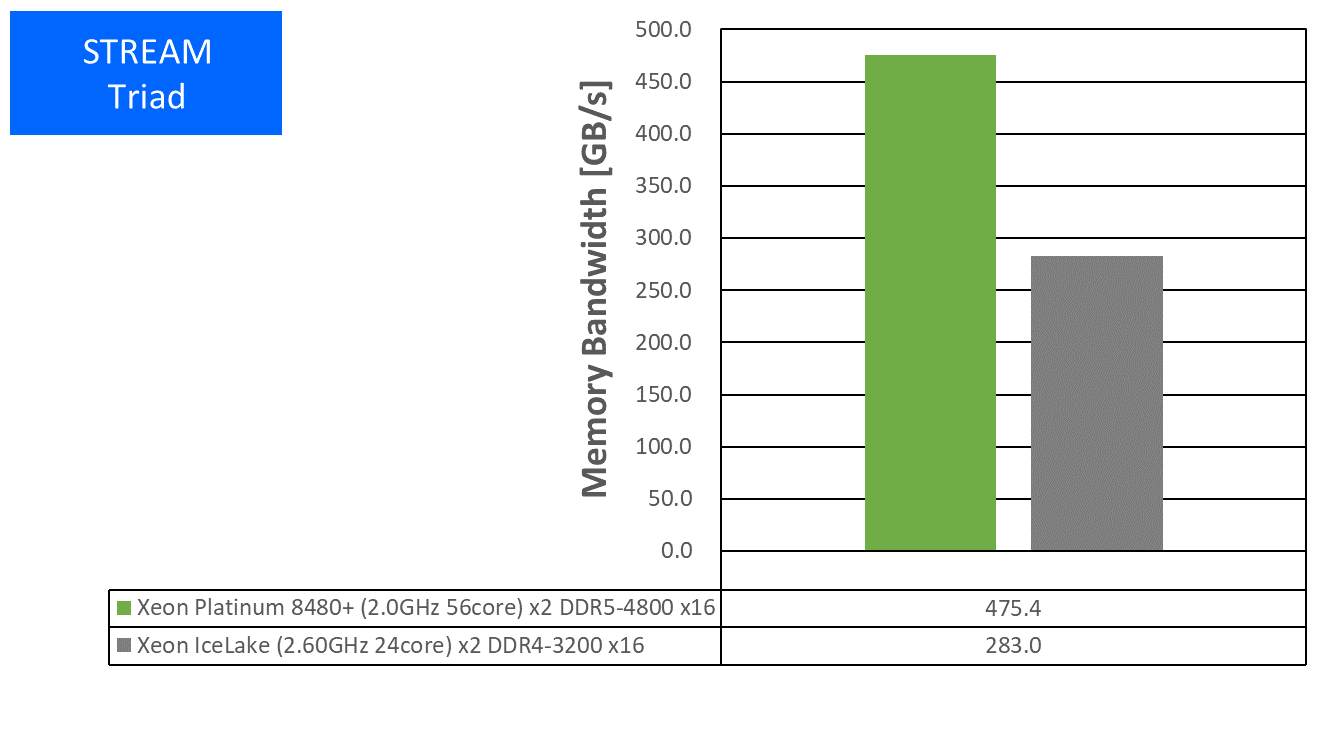
特長:前世代の1.68倍の実効メモリ帯域を達成
Sapphire Rapids環境では新たにDDR5-4800に対応し、前世代の1.68倍のメモリ帯域性能を達成しました。ステンシル計算やFFTなどメモリ帯域により律速しがちな計算のユーザーにとって、期待の持てる結果と言えるでしょう。
Gaussian
量子化学計算のデファクトスタンダードであるGaussianでのベンチマークを行いました。AVX2に最適化されたGaussian社標準のBinary版パッケージを用いました(AVX-512には未対応)。
Gaussianパッケージに付属のtest0397インプット(Valinomycin分子C54H90N6O18、RB3LYP/3-21GでのForce計算)で経過時間を取得しました。さらに、基底関数系を6-31G(d,p)に変えたインプット(rkest0397と呼んでいます)についても経過時間を取得しました。Linux付属のperfコマンドを用いた平均実効動作クロックもグラフ中に併せて記載しています。
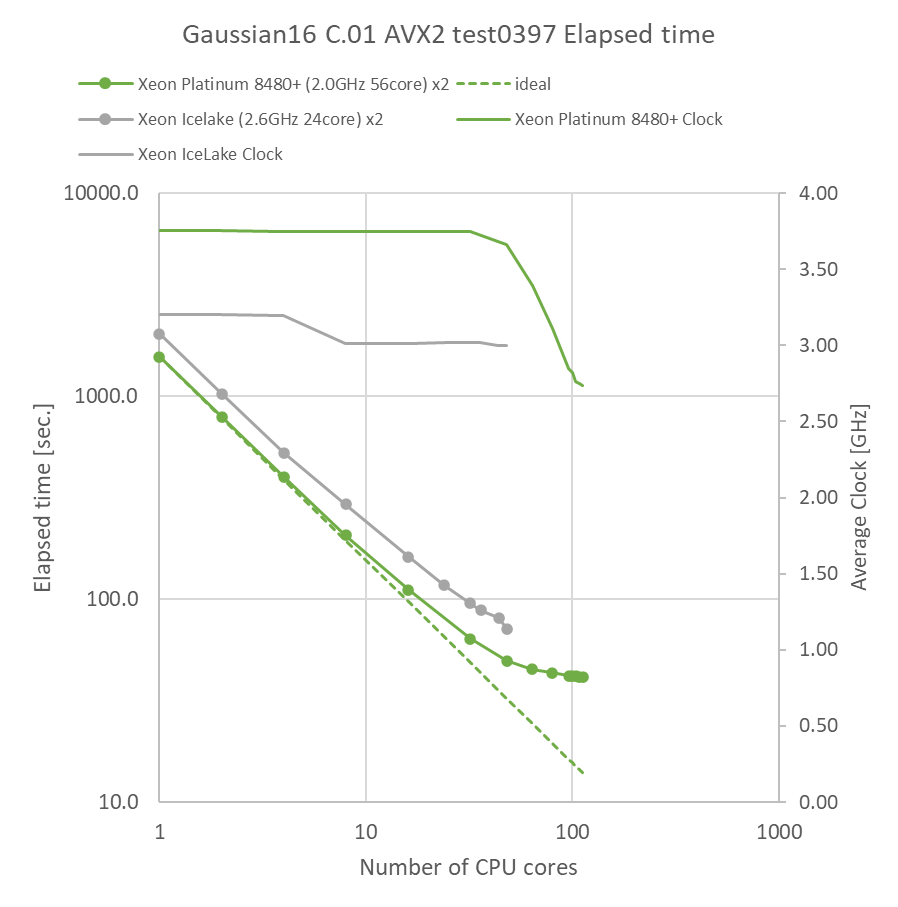
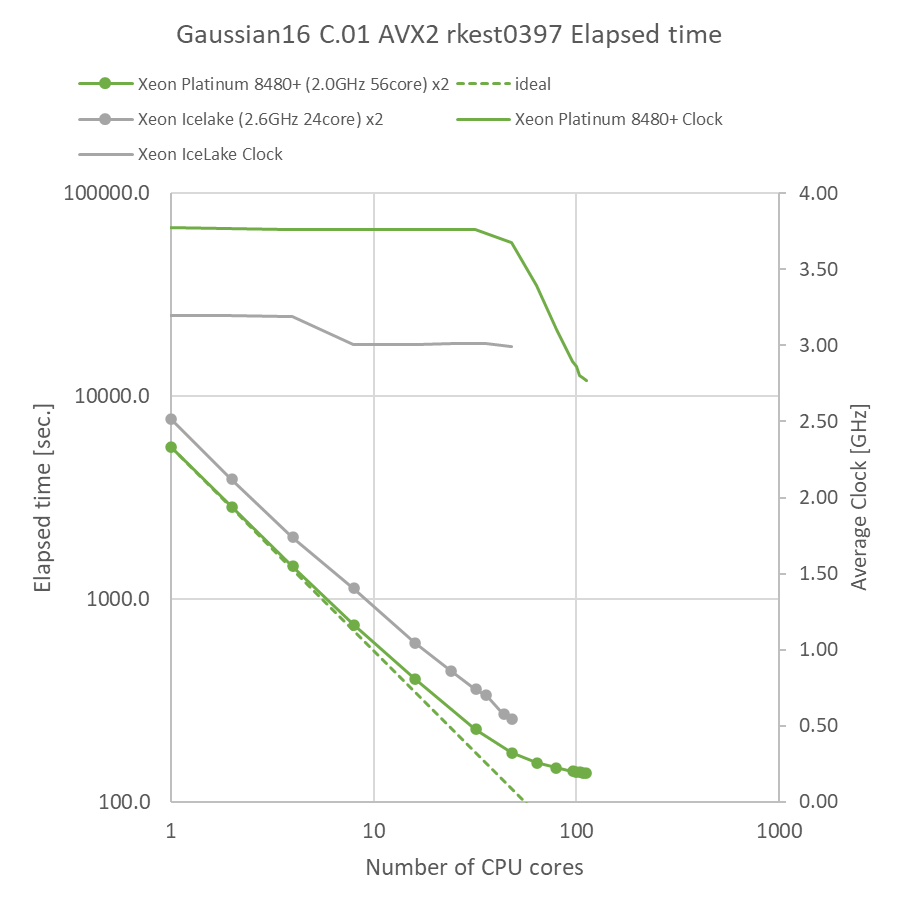
特長:前世代と比べて全ての並列数で大きく高速化、48並列まで高い動作クロックを維持
Ice Lake環境と比べて、同一並列数で1.44~1.57倍の速度向上が得られ、全体的に計算時間が短縮されました。動作クロックは48並列時に1.23倍の差であったため、動作クロック以上の速度向上がSapphire Rapids環境で得られていることがわかります。ベンチマーク時に併せて実施したperfコマンドによるプロファイリング結果では、Sapphire Rapids環境において、Ice Lake環境に比べてInstruction per cycle(IPC)が10%向上し、分岐ミス率が0.07%低減していることがわかりました。これらが総合的に速度向上に寄与したと考えられます。