ベンチマーク報告書(PDF)のダウンロードはこちらからどうぞ!
概要
2023年12月14日(日本時間15日)、第5世代 インテル🄬 Xeon🄬 スケーラブル・プロセッサー(開発コード名:Emerald Rapids)がリリースされました。「Intel 7」製造プロセスにより微細化されており、1ソケットに最大64コアを搭載可能になったことに加え、CPU間のUPI接続速度が20 GT/sに向上しました。また、コア間で共有されるLast Level Cacheの容量が320MBに拡大し、メモリアクセスを多用するAI・HPCワークロード向けに機能強化されています。さらに、新たにDDR5-5600のメモリに対応し、より太いメモリ帯域に進化しました。着実に機能強化を継続しているインテル社の姿勢がうかがえます。
第5世代 インテル🄬 Xeon🄬 スケーラブル・プロセッサーの性能を調査するため、第5世代 インテル🄬 Xeon🄬 スケーラブル・プロセッサーの2ソケットマシンと、第4世代 インテル Xeon® スケーラブル・プロセッサーの2ソケットマシンとで、各種アプリケーションのベンチマークを実施して実効性能を比較しました。
ここではそのベンチマーク結果の一部をご紹介します。この他のアプリケーションのベンチマーク結果や補足情報を含む全文は、こちらからお申込みいただきますとPDFをダウンロードいただけます。
第5世代 インテル🄬 Xeon🄬 スケーラブル・プロセッサーの特長

- 「Intel 7」製造プロセスにより微細化され、トップビンのSKU「Xeon Platinum 8593Q」では1ソケットに64コアを搭載しています。前世代は最大60コアでした。
- CPUソケット間の接続に用いられるUPIが、CPUあたり最大4本である点は前世代と同一ですが、UPI 速度が最大20 GT/sに向上しました(前世代は16 GT/s)。
- 前世代で組み込まれたアクセラレータ群である、AI系ワークロードの加速に有益なAdvanced Matrix Extensions(AMX)命令、ストリーミング型データ移動のためのアクセラレータData Streaming Accelerator(DSA)、Accelerator Interfacing Architecture(AiA)、暗号化やデータの圧縮/解凍のためのIntel Quick Assist Technologyは継続提供されています。
- コア間で共有される、最大320MBのLast Level Cacheが搭載されます。
- 本世代では、1ソケット、2ソケットのみ構成可能です。前世代は1ソケット、2ソケット、4ソケット、8ソケットの構成に対応していました。
- CPUあたりのメモリチャンネル数は前世代と同じ8本ですが、新たにDDR5-5200 MT/s、DDR5-5600 MT/sのメモリに対応しました(それぞれ、前世代DDR5-4800 MT/sの1.08倍、1.17倍)。
- Gen 5.0に対応したPCIeレーンが80本の搭載は前世代同様です。
- Compute Express Link(CXL)1.1 に対応し、ソケットあたり4つのCXLデバイスに対応しています。本世代より、CXL1.1 Type3に対応しました。これにより、CXLメモリから4チャンネルを、メインメモリから8チャンネルを、合計12チャンネルを確保し、帯域幅を重視したメモリ構成が可能になりました。
Gaussian
量子化学計算のデファクトスタンダードであるGaussianでのベンチマークを行いました。AVX2に最適化されたGaussian社標準のBinary版パッケージを用いました(AVX-512には未対応)。
Gaussianパッケージに付属のtest0397インプット(Valinomycin分子C54H90N6O18、RB3LYP/3-21GでのForce計算)で経過時間を取得しました。さらに、基底関数系を6-31G(d,p)に変えたインプット(rkest0397と呼んでいます)についても経過時間を取得しました。Linux付属のperfコマンドを用いた平均実効動作クロックもグラフ中に併せて記載しています。
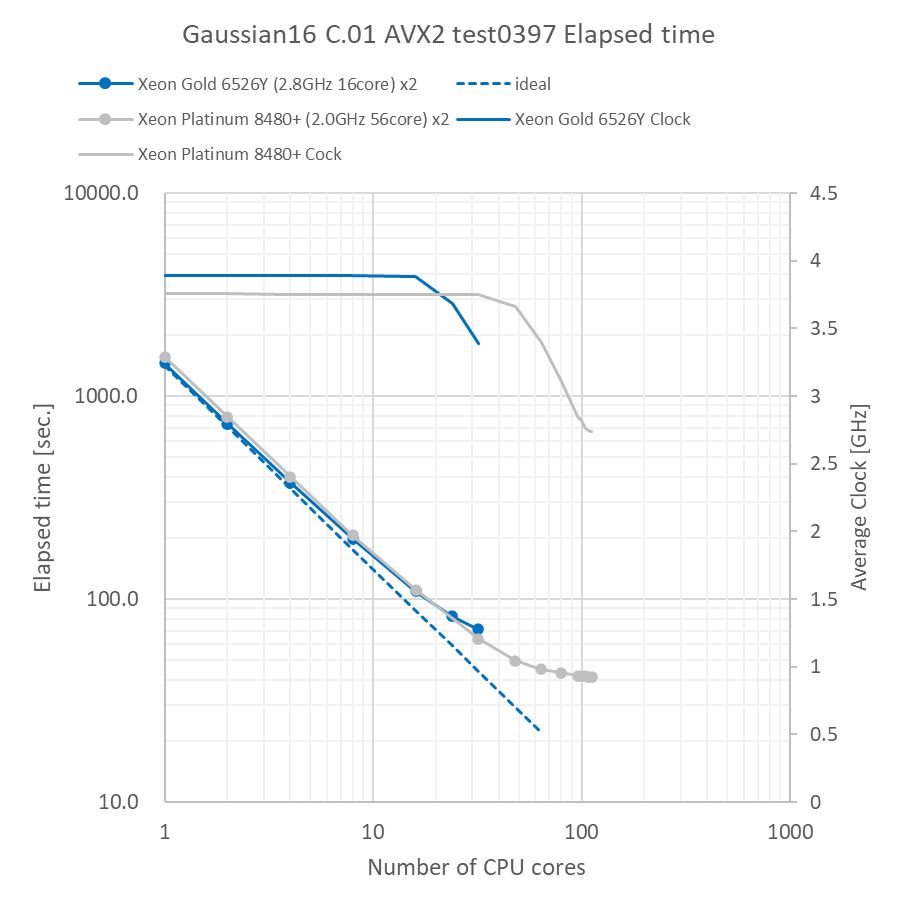
特長:前世代と同等の実効性能を達成
CPU動作クロック差で換算して、前世代と同等の実効性能がEmerald Rapids環境で得られました。前世代と比べてCPUやコアのアーキテクチャに大きな差が無いため、ほぼ同じ実効性能となるのは妥当と考えられます。