
はじめに
この記事では、DGX H100について、背面図とブロックダイアグラムに着目した解説を行います。DGX A100と比較すると、DGX H100では規格が変更されたポートが導入されたり、安定した通信帯域の確保や高速なGPU間通信を実現するための工夫が凝らされています。DGX H100導入にあたっての参考にしていただけると幸いです。
背面図
まずは、サーバーの背面について、DGX A100とDGX H100を比較し、これまでの構成とどう変わったかを見ていきましょう。
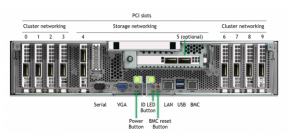
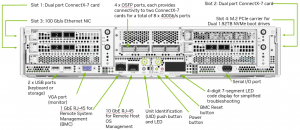
上の図はDGX A100、下の図はDGX H100です。DGX製品に限らず、大規模な深層学習を実施するためのサーバーでは、用途に応じて通信ポートを分けることが主流となっており、そのために様々な通信ポートが背面に集約されています。DGX製品では、主に以下の5種類のネットワーク用にポートがそれぞれ用意されています。
| ネットワーク | 用途 |
|---|---|
| cluster network | GPU間の通信 |
| storage network | ストレージサーバーとの通信 |
| management network | 管理サーバーとの通信 |
| out-of-bound network | 各サーバにリモートアクセスする用途 |
| BMC | 各サーバーをリモートで監視・制御する用途 |
以下では、cluster/storage/management networkがDGX A100とDGX H100でどのような仕様となっているか解説していきます。ちなみに、DGX H100の左上にあるdual port NICは当初、オプションとして50GbEで通信するNICが想定されていましたが、最終的に標準搭載扱いとなり、通信帯域も100GbEとなりました。また、Storage/Management用のNICとして当初Bluefield-3 DPUが搭載される予定でしたが、こちらも最終的にConnectX-7のdual port NICに変更されています。一部、マニュアル等で過去の仕様のまま記載されているものがありますのでご注意ください。
左上の100GbEのカードに関しては、汎用的に使えるポートとなりますので、今回の説明では省略いたします。
Cluster network
Cluster networrkはDGXサーバ間のGPU-GPU通信を担っており、8基のGPUに対して8ポート用意されています。DGX H100とDGX A100では、このcluster network部分に以下の違いがあります。
| 製品 | ケージ数 | ポート数 | トランシーバ規格 | 世代 |
|---|---|---|---|---|
| DGX A100 | 8 | 8 | QSFP56 | ConnectX-6 |
| DGX H100 | 4 | 8 | twin port OSFP (flat top) *1 | ConnextX-7 |
上記の表の「ケージ数」とは、背面にあるcluster network用の通信ポートの口数を表しています。
DGX H100で採用されたtwin port OSFPは、筐体内部で2つのConnectX-7(400Gbps)に接続する構造となっており、1つのトランシーバに2本のケーブルを挿して運用します。そのため、ポート数はケージ数の2倍となります。twin port OSFPを採用したことで、DGX A100ではサーバー背面の約半分を占めていたcluster network部分が、DGX H100ではサーバー背面の中心部分に収まるようになりました。
しばしば、「1つのOSFPトランシーバを使って800Gbpsで通信できる」という記述がされますが、これは単に通信帯域を足し合わせた数値に過ぎず、DGXサーバー間のGPU通信が800Gbpsで行えるという意味ではありませんので注意してください。
cluster networkに関して、トランシーバの規格や世代だけでなくサーバーの内部構造も変更があります。この変更は、DGXクラスターシステムで推奨されるネットワーク構成にも影響があるので注意してください。少しマニアックな部分になりますが、以下で、ブロックダイアグラムを参照しながら順を追って説明します。
- DGX A100のブロックダイアグラム
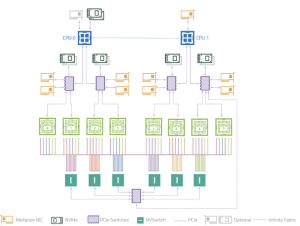
中段にある8つの黄色いNICがcluster networkを担うポートです。DGX A100では、「2つのポートが一度PCIeスイッチを経由して2つのGPUとつながる」という構造をしていました。この2つのポートは、内部的に全く同じ経路を通ってGPUとの通信を行っています。そのためbase pod構成(半分の通信帯域を使ったネットワーク構成)の場合、2つのポートのうちの1つを使って構築します。物理的には、背面にある8つのケージの半分だけにケーブルを挿してネットワークを構成します。 - DGX H100のブロックダイアグラム
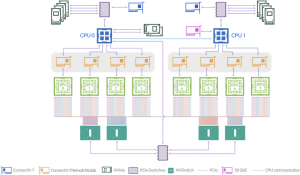
一方、DGX H100ではPCIeスイッチを経由せず、1つのポートが1つのGPUにダイレクトに接続する構成に変更され、DGXサーバー間のGPU通信の最適化が行われています(図の中段にある8つの黄色いNIC)。内部構造が変わったことにより、base pod構成であっても全てのポートを使用しなければいけません。物理的にケーブル配線を行う際は、ケーブルの本数を半分にするのではなく、スプリッターケーブルを使用して、全ての物理ポートに結線する必要があります。
上記の構成変更がクラスターシステムにもたらす影響については、この記事の最後に考察します。
余談ですが、先ほど「DGXサーバー間のGPUが800Gbpsで通信できるわけではない」ということを紹介しましたが、この理由に関してはブロックダイアグラムを見ていただければ明らかです。DGX H100で採用された構成は、1GPUに1つのポートが対応しているため、DGXサーバー間のGPU通信は400Gbpsとなります。
上記の説明を聞いて「DGX A100が採用している構成ならば、同じ経路上にある2ポート分の通信帯域で通信ができるのでは?」と思う方がいるかもしれませんが、こちらも不可能となります。というのも、GPUとPCIeスイッチがPCIe x16レーンでつながっているためです*1。この部分が律速となり、2ポート分の通信帯域を確保することはできません。
Storage network / Management network
storage networkは、深層学習実行時に行う訓練データの読み込みやチェックポイントファイルの書き出しのために、Lustreなどの高速ファイルシステムと通信を行うためのネットワークです。一方で、management networkは、クラスターシステム全体で動作するk8sやslurmなどの管理系ソフトウェアの通信で使います。他にもCPU間の並列計算時等にも使われますが、深層学習用途ではあまり重視されません。DGXサーバーでは、1つのデュアルポートNICにある2つのポートを、それぞれstorage用/management用として使用します。デュアルポートNICはCPU0側・CPU1側に1枚ずつ用意されており、CPU-CPU間のUPI通信部分を避けてストレージに直接アクセスできるようにネットワーク設計を行います。
以下で、DGX H100とDGX A100の違いを表にしました。
| 製品 | ポート数 | トランシーバ規格 | 世代 |
|---|---|---|---|
| DGX A100 | 4 | QSFP56 | ConnectX-6 |
| DGX H100 | 4 | QSFP112 | ConnectX-7 |
cluster networkの時とは異なり、トランシーバの規格などで大きな変更はありません。QSFP112は後方互換性があり、HDR世代のケーブルをDGX H100に利用して200Gbpsで通信できます。また、それぞれのポートをIB/Ether2つのモードに切り替えることができるため、storage networkはIB、management networkはEtherで構築することも可能です(ただしEtherの場合は200GbEとなります)。実際にDGX H100では、デュアルポートNICの向かって左側のポートがEther,右側のポートがIBで通信するような初期設定となっています。
一点注意が必要なのは、DGX H100では、PCIe Gen5 32レーン分を利用したデュアルポートNICを使用しており、2つのポートどちらも400Gbpsで通信できるように設計されていることです。PCIeカード版のConnectX-7と仕様が異なるので注意してください。
最後に
DGX H100で今回の構成が採用された理由は、LLMなどの巨大なモデルの学習に特化させるためだと考えています。モデル並列による学習を行う場合、DGXサーバー間のGPU通信がボトルネックとなるため、PCIeスイッチを排除してダイレクトに接続し、通信経路の最適化が行われています。
一方で、今回の構成変更によりキャッシュ用のNVMeストレージとGPUとの距離が遠くなりました。この変更はデータ並列で計算が済む規模のモデルを学習させる場合に不利に働いているかもしれません。特にGPUダイレクトストレージ等にどのような影響が表れているかは今後検証してみたいと考えています。
また、今回はDGXサーバー間のGPU通信について主に解説しましたが、DGXサーバー内のGPU通信はNVlinkによってつながっています。DGX H100に搭載されている第4世代のNVLinkの通信帯域は900GB/s(双方向)です。
これはGbps(単方向)に換算すると3600Gbpsとなり*3、NDRの通信帯域400Gbpsはやはり見劣りします。NVIDIAでは将来的に、外部NVSwitchを作成してサーバー間のGPUもNVLinkでつなげる計画をたてており、これが実現すれば、GPUを使った並列計算は新しいパラダイムを迎えることになるでしょう。非常に楽しみですね。
DGX H100は、単に搭載されているGPUの性能が上がっただけでなく、様々な部分にも前モデルから変更が加えられました。LLMなどの大規模学習に最適化されていることを感じていただければ幸いです。
*1 DGX H100では、OSFP (flat top)という規格が採用されており、一般的なOSFP (finned top)トランシーバからフィンが排除されたスリムな形状となっています。この2つのトランシーバは互換性がないことに注意してください。
*2 NVIDIA DGX A100 System Architectureに、下記の記述があります。
The NVIDIA A100 GPUs are connected to the PCI switch infrastructure over x16 PCI Express Gen 4 (PCIe Gen4) buses that provide 31.5 Gb/s each for a total of 252 Gb/s, doubling the bandwidth of PCIe 3.0/3.1.
*3 単位換算は、1GB/s(双方向)=4Gbps(単方向) となります。

