ベンチマーク報告書(PDF)のダウンロードはこちらからどうぞ!
概要
2022年11月10日、第4世代 AMD EPYC™ プロセッサー(開発コード名:Genoa)がリリースされました。新マイクロアーキテクチャ「Zen 4」を採用し、5nm製造プロセスにより微細化されて、1ソケットで最大96コア、2ソケットで最大192コアという多コア構成が可能になったことに加え、DDR5-4800メモリに対応してメモリチャンネルが12本に増えたことでメモリ帯域も太く構成されている点が特長です。また、AVX-512命令に対応してAI・HPCワークロード向けに機能強化された他、キャッシュ階層と分岐予測の改善によってIPC(Instruction per cycle、1サイクルあたりに実行可能な命令数)が前世代と比べて平均約14%向上しており、並列アプリケーションおよびシングルスレッドアプリケーションの両方の高速化に期待の持てる進化を遂げています。
第4世代 AMD EPYC™ プロセッサーの性能を調査するため、第4世代 AMD EPYC™ プロセッサー2ソケットマシンと、前世代のプロセッサー(開発コード名:Milan-X、Zen 3採用)を搭載した2ソケットマシン、そして第3世代インテル Xeon® スケーラブル・プロセッサー(IceLakeアーキテクチャ)とで、各種アプリケーションのベンチマークを実施して実効性能を比較しました。
ここではそのベンチマーク結果の一部をご紹介します。この他のアプリケーションのベンチマーク結果や補足情報を含む全文は、こちらからお申込みいただきますとPDFをダウンロードいただけます。
第4世代 AMD EPYC™ プロセッサーの特長
- 第4世代FinFETを用いた5nm製造プロセスにより微細化され、トップビンのSKU「EPYC 9654」では1ソケットで96コアもの多数のコアを搭載しています。また、微細化により1個のCPUパッケージあたり、最大12個のCCDを搭載可能となっています。
- ハイブリッド・マルチダイ・アーキテクチャーを採用しており、CPUコアをI/Oから切り離すことで、それぞれのコアに最適なプロセス技術を利用することが出来ています。
- AIやHPCのアクセラレーションに最適なAVX-512命令に対応しています。これにはBFloat16命令やVNNI命令が含まれています。
- L2キャッシュ、実行エンジン、分岐予測、ロード/ストア、フロントエンドに改善が重ねられた結果、前世代に比べてIPC(Instruction per cycle)が平均14%向上しています。
- 前世代に比べて増大した、コアあたり1MBのL2キャッシュを搭載しています。
- CCDあたり32MBのL3キャッシュを搭載しています。
- AMD Infinity Fabricによるプロセッサー間接続は、前世代の2倍の速度に強化されています。
- PCIe Gen 5.0(4.0に比べて2倍の転送速度)のレーンを最大160本利用できます。
- CXL 1.1+、CXL 2.0メモリーデバイスをサポートしています。
- DDR5-4800メモリチャンネルを12本搭載しており、前世代と比べて最大2.3倍のメモリ帯域に強化されます。2、4、6、8、10、または12本のバスでインターリーブすることにより、メモリ構成の柔軟性を高めることができます。
- メモリは256ビットAES-XTS暗号化に対応しています。
- 新機能のAMD Infinity Guardにより、SEV-SNPゲスト数が前世代の最大2倍に向上します。
HPL
HPLはスーパーコンピュータの性能ランキング『TOP500』で用いられているベンチマークプログラムです。連立方程式の解を求めるプログラムで、浮動小数点演算の性能をFLOPS単位、つまり1秒間に処理できる浮動小数点演算命令の数で性能を評価します。HPLは演算インテンシブなベンチマークとして知られており、CPUの浮動小数点演算性能を把握するべく使用しました。
HPLのビルドおよび実行においては、AMD社のAOCL User Guideに沿って設定を行いました。ベンチマーク結果を次に示します。
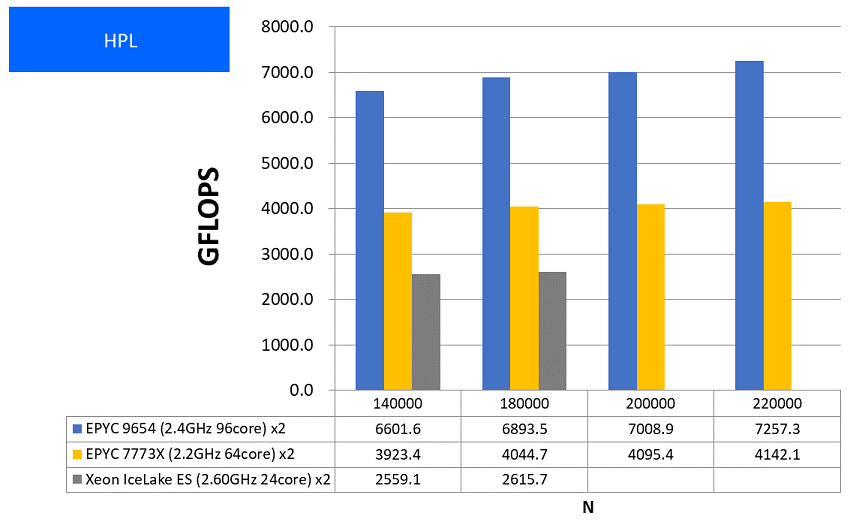
特長:前世代や他CPUと比べて段違いに高い浮動小数点演算性能を達成
1ソケットで96コアというコア数の多さが、ノードあたりの浮動小数点演算性能の高さに如実に表れました。Milan-X環境との性能比がN=220,000において1.75倍となっており、大きく性能向上したことが確認できました。演算インテンシブなプログラムにおける実効性能向上の目安として捉えていただければと思います。
STREAM (Triad)
STREAMはメモリ帯域性能の測定に多用されているベンチマークプログラムです。その中でもTriadというプログラムは巨大な一次元ベクトルの積和を行うOpenMP並列プログラムで、並列動作させてメモリ入出力のノード全体帯域を測定します。
STREAMはoneAPI 2022.2.0でAVX-512最適化オプションを有効にしてビルドしたものでベンチマークを実施しました。1ノードでのピーク時の結果は以下となりました。
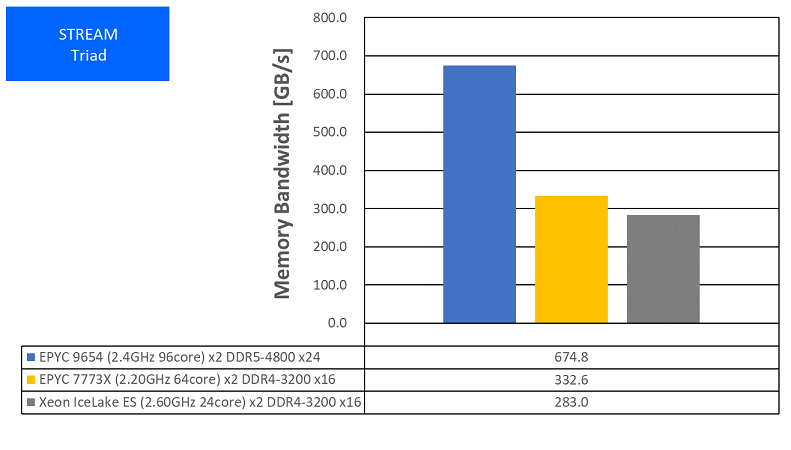
特長:前世代の2倍の実効メモリ帯域を達成
CPUあたりのメモリチャンネル数が8から12に増加し、さらにDDR5-4800に対応したことで、前世代の2.03倍のメモリ帯域性能を達成しました。ステンシル計算やFFTなどメモリ帯域により律速しがちな計算のユーザーにとって、非常に期待の持てる結果と言えるでしょう。
Gaussian
量子化学計算のデファクトスタンダードであるGaussianでのベンチマークを行いました。AVX2に最適化されたGaussian社標準のBinary版パッケージを用いました(AVX-512には未対応)。
Gaussianパッケージに付属のtest0397インプット(Valinomycin分子C54H90N6O18、RB3LYP/3-21GでのForce計算)で経過時間を取得しました。さらに、基底関数系を6-31G(d,p)に変えたインプット(rkest0397と呼んでいます)についても経過時間を取得しました。
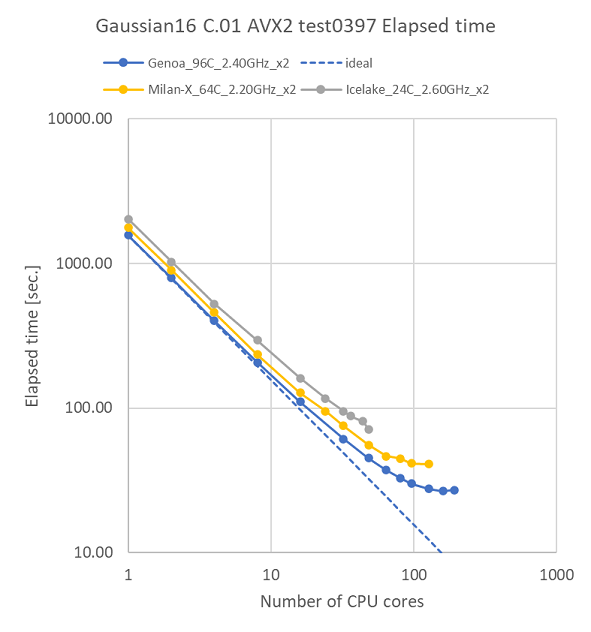
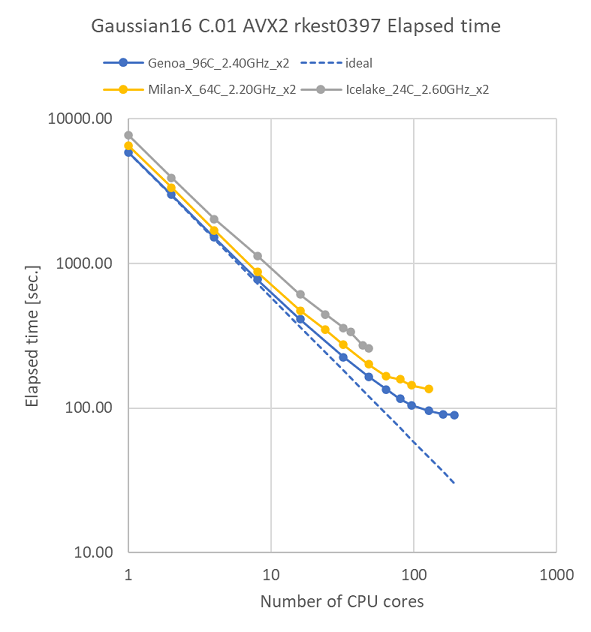
特長:前世代と比べて全ての並列数で高速化を達成
96コア程度までの並列スケーラビリティは前世代Milan-X環境と同様で、全体的に計算時間が短縮されました。rkest0397の48並列どうしの比較では、Genoa環境は、Milan-X環境の1.22倍、IceLake環境の1.57倍の計算速度となっています。この速度向上には、AMD Turbo CoreテクノロジーによりAVX2動作中もCPUクロックがブーストしたことに加えて、IPCが向上したことが作用しています 。
Genoa環境の並列スケーラビリティについては、IceLake環境の並列数では見えてこなかった、128並列以上での伸び悩みが観測されました。Gaussianの演算インテンシブの傾向を考慮すると、並列数に対して今回のベンチマーク計算の規模が小さいことに起因すると考えられます。
Gaussianの演算インテンシブな傾向と96コア程度までの並列スケーラビリティを鑑みると、Gaussianには基本的にCPUコアの多い構成が望ましいと言えます。それより大きな並列数では、今回のように計算規模に対して並列数が大きすぎて伸び悩む状況も起こりえるため、その場合には、複数の計算ジョブを同時並行で流すことでCPUコアをフル活用するなど、運用時に工夫を行うことで、Genoa環境の計算パワーを余すことなく活かしきることができるでしょう。

