
はじめに
HPCとはHigh Performance Computingの略で、一般には科学技術計算を意味すると認識されています。ところが、この中にどこにも「科学」とか「技術」とかの単語はありません。HPCの定義として高速にデータ処理をするもの全般として広くとらえた方が良いと、ずっと個人的には考えていますが、まだまだ一般的な考え方とは言えないのが現状です。
さて、最初にAWSがLustreをやると聞いた時は、旧来のHPC以外の人はそもそもLustreなんて知らないし、使う理由もないのでは?と思っていました。実際、Lustreをメインのストレージとして使うには初期投資が大きくなりがちで、性能要件から構成を決定する必要もあり、大容量(数百TB〜数PB)が前提となるため、クラウドに組み込むには面倒なわりに、多くのケースにフィットしないように思えます。実際、かなり以前からMarketPlaceにAMIが用意こそされていたものの、実際に使っている人をほとんど見かけません。しかしFSx for Lustreについては、いわゆる旧来のHPCとは違う分野でこそ、うまく使いこなさないともったいないサービスだということに気づきました。
そこで、Lustreはどのようなストレージを実現するのか、その背景からざっくり説明していきたいと思います。
Lustre File Systemとは
主にスパコン等のHPC分野で使うことを想定して開発されてきた並列分散ファイルシステムです。複数のクライアントで同一の名前空間をもつ共有ファイルシステムであるにもかかわらず、NFSのような疑似ファイルシステムではなく、ネイティブのファイルシステムとして実装されていて、世界中のスパコンで大規模かつハイパフォーマンスなストレージとして使われています。開発主体は現在はDDN社が持っているものの、GPLv2なオープンソースなので、誰でも自由に使うことができます。
実稼働しているものだけを見ても、数十PBの容量に数十億個以上のファイルを保持、それを数万台のクライアント間で同一ネームスペースで共有、トータルスループット数TB/秒など、驚異的なストレージが実現できています。
こんなストレージは当然ながら1台のサーバーでできているはずがなく、複数のサーバーと、データを保存するためのデバイスを多数用意し、それらを束ねた上でネットワークを通じてファイルシステムとして提供します。これにより、
- 複数のサーバーのネットワークを分散利用することで、理論上スループットをサーバーの台数倍にでき、ネットワークがボトルネックになることを回避できる。
- 多数のブロックデバイスに並列にアクセスすることで、理論上スループットをその数だけ倍増でき、ブロックデバイスがボトルネックになることを回避できる。
- スループットとキャパシティを重視したい実データ(オブジェクト)と、レスポンスを重視したいiノード情報(メタデータ)を、それぞれに最適化した個別デバイスに保存することで、他の要素への負荷に足を引っ張られにくい構造にできる。
この、オブジェクト(実データ)を扱うサーバーをObject Storage Server(OSS)と呼び、実際にデータを蓄積するデバイスをObject Storage Target(OST)と呼びます。OSTとしては、通常のRAID6等の大容量ブロックデバイスが用いられます。メタデータについてもMeta Data Server/Target (MDS/MDT)を用意し、MDTとしては低レイテンシ重視でSSDのRAID10を採用したりします。さらにファイルシステム毎に一つ、管理用のサービスと構成情報の領域が必要で、Mamagement Service/Target(MGS/MGT)といいます。MGS/MGTはパフォーマンスもサイズもほとんど要らないので、小さめのシステムではMDS/MDTにまとめてしまうケースもあります。後の節に概念図を載せましたので参考にしてください。
これらを束ねるネットワークには、HPCで標準的に使われる高速インターコネクタInfinibandによるRDMA接続や、Ethernetを使ったTCP/IP接続を用い、その上でLNETという仮想ネットワークを構成します。現在主流なのはInfiniband/Ethernet共に100Gbpsネットワークなので、例えばOSSを8台束ねたLustreを構築すれば、ネットワークの帯域幅は800Gbps=100GB/秒になるわけです。ただし、ターゲットデバイスがそれだけの性能を出さなければ、そちらが性能ボトルネックとなります。例えばHDD10本のRAID6をターゲットとした場合、そのスループットは1GB/sec程度なので、このRAIDが8~10個、即ちHDD100本程度が繋がったサーバーを100Gbpsで接続すると性能的にはバランスします。
実はターゲットデバイスはext3/4やZFSでフォーマットされた疑似ファイルシステムとなっていますが、それをLustreの一部としてマウントしているMDS/OSSからは、どんなファイルが入っているのかを見ることはできません。全体をLustreとしてフォーマットし、LNETを構成する全ての要素が揃った上で、クライアントがそれをマウントしてはじめてファイルにアクセスできます。OSS/MDSがOST/MDTをLustreの一部としてマウントするにはカーネルにパッチをあてて再ビルドする必要があります(ZFSの場合は不要)が、ビルド済みのカーネルパッケージがLustreのリポジトリから配布されています。クライアントのカーネルにはパッチを当てる必要はありませんが、カーネルモジュールが必要です。残念ながらWindowsから直接マウントすることはできません。
Lustreの動作
複数のOSSにさらに複数のOSTが接続されてデータが分散され、どこにどんなファイルが保存されているか?というiノード情報(メタデータ)はMDTで一元管理されています。ファイルを保存する時には、デフォルトではトランプのカードを配る時のように、OSTへ順番にファイル単位で保存されていきます。つまり個別のファイルに対するアクセス速度はターゲットの構成要素以上には出ません。例えば先述のようにHDD10本でRAID6を組んだOSTの場合、個別ファイルへのアクセススループットは最大1GB/sec程度となり、同じターゲット上にあるファイルに同時アクセスが入れば性能劣化します。同時にアクセスされる対象が複数ターゲットに分散しているものであれば、I/Oが衝突せず帯域が飽和しにくくなるわけです。それを合計(アグリゲート)して最大スループットとします。
下図は、40台の計算サーバーを持つクラスターに、OSTを4つずつ持ったOSSが8台で構成されるLustreを接続した例で、単一ディレクトリに38個ファイルがある場合を表しています。ファイルサイズでバランスされるわけではないので、図のように比較的大きなサイズのファイルをもつOST02は使用率が高くなってしまいます。
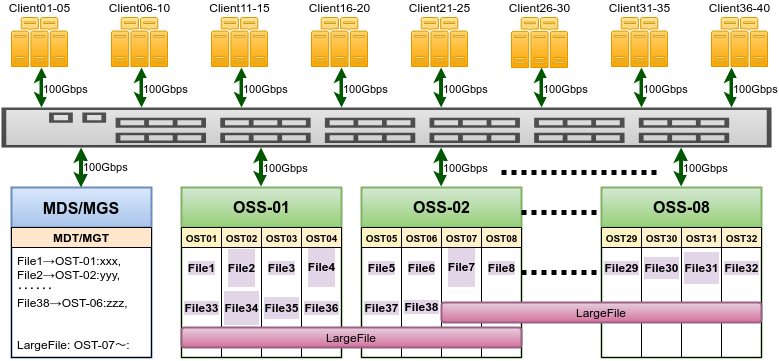
Lustreファイルシステムの概念図
そのため、巨大なファイルが生成された場合、特定のOSTだけが埋ってしまう恐れがあります。Lustreはこうしたファイルを分断し、OSTに並べて保存していくモード(ストライプ)も持っていて、図中のLargeFileのようにOSTを跨いで保存できます。ただし自動的に行われるわけではなく、ユーザーがディレクトリ毎ファイル毎に設定する必要があります。
多数のクライアントから多数のファイルへ一斉アクセスがある場合、メタデータ管理の負荷が一気に高まります。そのため最近ではMDTにNVMe等の高IOpsなデバイスを用いてこれに対応します。1TB程度のMDTで、だいたい1億ファイルくらい管理できます。
Lustreというファイルシステム自体には、可用性を担保する機能は入っていません。そのため故障等に耐えるストレージを実現するには、各要素毎にそれを実現してやる必要があります。例えば、MDS/OSSについてHA構成にするのにそれぞれ2台構成にすれば、OSS8台で性能を満たせるのにOSSとして16台必要になります。また、ターゲット接続をSANにして可用性を担保してきました。そうした結果Lustreを使うのに大掛かりで複雑なシステムが必要になって初期投資が大きくなる上、安定運用には多彩なノウハウが必要になるわけです。
おまけーHPCでLustreが必要な別の理由
上記のとおり、ブロックデバイスのサイズ制限やネットワーク帯域の制限を、機材を分散することで大幅に引き上げ、単一のファイルサーバーでは実現できない大容量・広帯域をLustreは実現しています。しかしそれだけではありません。
HPCでは大規模な計算を行うにあたり、巨大なメモリ空間が必要だったり、単独で計算するには時間が掛りすぎるケースがあります。そこで、計算しなければならないデータを分割して個別に計算を進め、最後に集計するということを行います。例えば10000枚のシートを持つエクセル上でデータ処理をして最後に集計するということを考えます。この時、100シートずつ100個のエクセルを起動して並列に処理を実行し、最後に串刺しをするというイメージです。この個別のアプリケーション同士の1対1、あるいは集計のための1対多のデータ通信をするAPIと、単独の目的でアプリを番号付きで多数一斉起動する仕組みがHPCでは標準的に用意されていて、MPI(Message Passing Interface)と呼ばれています。
つまり単独の処理をするために、多数の計算サーバー上で多数のアプリを起動し、それぞれがファイルを読み書きする必要がでてきます。当然ながらOSの上ではそれらは全く別々のプロセスとして認識され、I/Oの衝突(特に書き込み)を避けるよう排他処理されます。しかし、ユーザーからすると並列処理を行っている多数のアプリケーション全体を1つのプロセスと見なしたいわけです。Lustreではこれが実現でき、別々のマシンで動く数十〜数千個のプロセスが、単一データファイルを同時にオープンして読み、計算結果を単一ファイルへ一斉書き出しをすることも実現できます。ただしそれで問題ないようアプリケーションをプログラムしておく必要はあります。
また、Lustreの持つこうした機能をラッピングして、分散アクセスを可能とするデータアクセスライブラリも存在し、スパコン上で扱われるデータ形式の標準的なフォーマットの一つとなっています。
-2- へつづく
