
旧来の普通のLustreとクラウド上のLustreの着眼点の違い
前回はLustreファイルシステムの概要を解説をしました。Lustreがどのようなコンセプトで設計され、大容量と高性能を実現しているのかおわかりいただけたのではないでしょうか。さて、前回少し触れましたが、MDS/OSSをそれぞれ2重化して可用性を高めた「普通のLustreの構成」を図にすると、次のようになります。
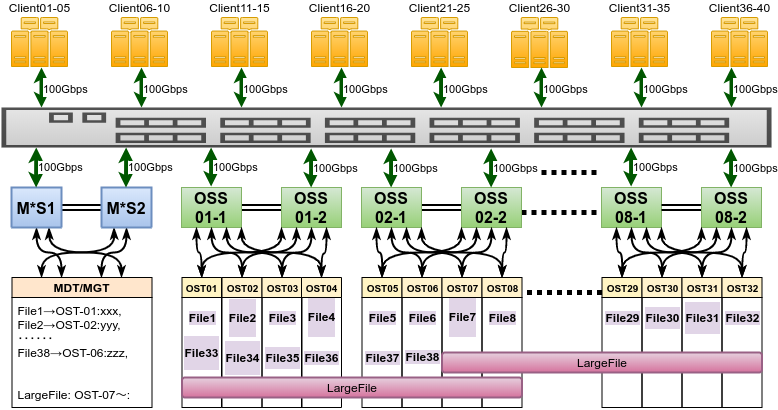
Lustreをオンプレミスで構成して安定運用しようとすれば、導入コストは数千万円〜になり、高度な技術と経験が必要です。しかし最大スループットなどについてある程度目をつむれば、AWS上でこうした構成を組むことはテンプレートを作ってしまえば難しいことではありませんし、可用性を実現するための各コンポーネントの切り替えなど、そもそもクラウドの方がずっと有利なわけです。また、長期運用を考えなければサーバーの多重化も必須ではなく、「多少遅くても長期運用できる信頼性の高いストレージ」と「ホットなデータを扱う高速ストレージ」を組み合わせればいいわけです。実際弊社でも、このコンセプトでシンプルに多重化していない安価なLustreストレージを、ChalkBoardFSという商品名でスクラッチ用途に提供していました。
さて、前回も触れたようにLustreは構成するサーバー台数とターゲット容量を要件に合わせることで性能設計するのが普通です。FSx for Lustreで一番驚いたのは、これらをユーザーに一切見せずに容量のみ指定させ、それで性能を決定する(1TBあたり200MB/sec)よう割り切っていることです。つまり小容量ハイスループットといった構成は少なくとも現時点では作れません。ただしターゲットに負荷状況でころころ性能が変わるHDDベースのRAIDなど使っていませんから、多少ワークロードが増減しても性能はブレにくく、示された性能は担保しやすいはずです。
旧来と違うHSMの使い方
Lustreは常に新しい機能を追加していますが、HSM(Hierarchical Storage Management)が2013年に搭載されてから、Lustreの使い方に幅が出てきました。他の言い方をするとTieringの機能です。つまり速いけれど小容量、遅いけれど大容量など、特性の違うターゲットを同一名前空間で貫き、必要に応じてデータを移動させて要件に合わせる運用を実現します。これは「ストレージ容量の全部を高性能にするとコストが高騰することに対する対症療法」な面が否めませんでした。一方でFSx for Lustreでは外部とデータをやり取りする仕組みとしてHSMを使い、その接続先として高信頼なS3を採用したことが大きな特徴です。そのため、運用の最中にこの仕組みを用いてデータの出し入れをすることはできません。つまり、FSx for Lustreは短期決戦に特化していて、価格設定的にも長期運用はターゲットにはなりません。
従来、S3に保管しているデータを処理をする用途では、VPCエンドポイントからS3にアクセスしてS3へ返すようなアプリ構成にするケースが多かったのではないでしょうか。しかしデータ同士の相関をとるなどのケースにおいて、多数のインスタンス上からこれを行うことは、特にデータの再利用が多いケースでは得策ではありません。共有ファイルシステムとしてはEFSが既にありますが、データの取り込みは透過的ではありませんし、NFSは決して高速には動作しません。
そのようなユースケースにおいて、I/Oが高速に動作することは、多数の計算用インスタンスの稼働時間の短縮に寄与します。このことを念頭において使います。
S3にあるデータはLustreをマウントすれば、メタデータだけがコピーされます。そのため、既に取り込みが終わっているように見えますが、実際にはデータはまだS3にあります。初回アクセス時にデータのコピーが実施され、次からはLustreネイティブの速度でアクセスできます。つまり、一回読んで書いて終わりという処理が延々と続くケースや、計算用のインスタンスがごく少数なケースでは、手でコピーしなくて良い利便性があるだけで、速度のアドバンテージはそれほど効いてきません。ましてデータサイズがそれほど大きくなく、計算を1インスタンスで行うなら、エフェメラルディスクの付いているインスタンスを使う方がベストプラクティスになるはずです。
次回は実際にFSx for Lustreを使って、その上手な利用法を探ってみましょう。
-3- に続く。
