
今回、倍精度浮動小数点演算時に発生する丸め誤差についてご報告します。みなさんには当たり前のこととおもいますが、HPC界は新参者の私には新たな発見の連続でした。
ある件で、線形代数演算ライブラリBLAS,LAPACKのことを調べているときに、理化学研究所計算科学研究センタ中田さんが公開されている資料「線形代数演算ライブラリBLAS とLAPACKの基礎と実践 (I) BLAS, LAPACK入門編 」を拝見していました。

この資料の中で、計算機の計算結果が、数学上の計算式と違うことがあるよ、こんなソースだよ、と教えてもらいました。
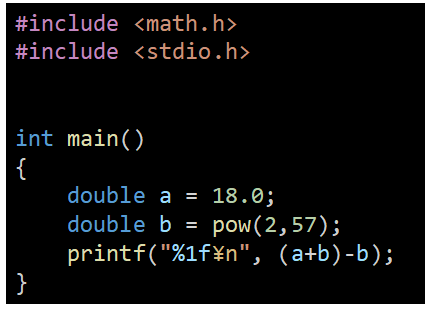
ある数aにある数bを足して、ある数bを減らす計算。数式で表現すると(a+b)-b。数学として考えれば、答えはa、ですよね。ところが、このプログラムで計算させると、結果はaにならないそうなのです。
そんな馬鹿な!?教えていただいたソースコードを社内にあるIntel Xeon SapphireRapids サーバ上でgccを用い、コンパイルし実行してみました。確かに、計算結果が数学上の結果とずれています。このソースコードの場合、a=18を期待したのですが、a=32が返ってきました。期待した値18と、32-18=14ずれています。

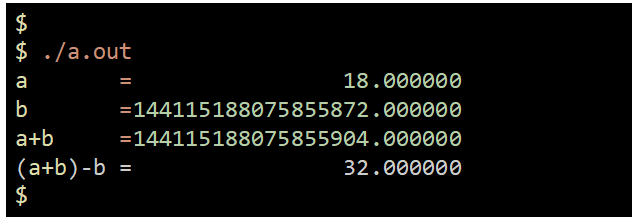
なぜなのでしょう?Google検索でIEEE754上の倍精度浮動小数点に関する標準規格に行きつきました。倍精度浮動小数点doubleはIEEE仕様上、指数部が11桁、可数部が53桁、符号部が1桁だそうです。可数部53桁に2の57乗という数bを入力することになるので、4ビットつまり10進で16が丸められ、切り上げされるようです。
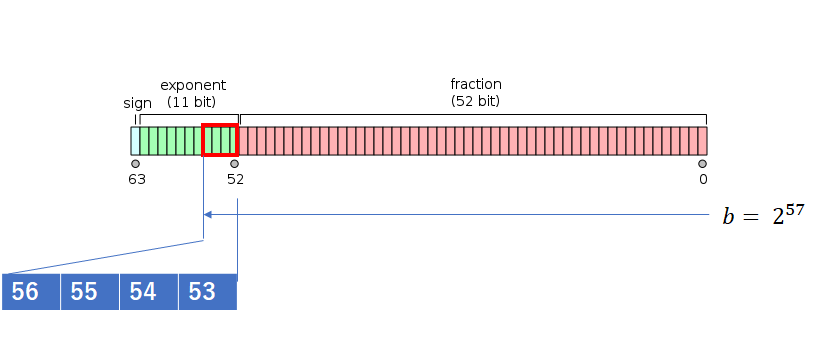
本当なのでしょうか?なにをもって、本当というかは、人それぞれでしょう。C言語のソースコードがIEEE仕様通りであればOK!という方もいるでしょう。私の場合、なるべく現地、現実、現物に近いモノを見ないと腹落ちしません。そこで、CPU上のレジスタの挙動をみてやれとおもい、objdumpコマンドをつかって、コンパイルしたオブジェクトを、該当するソース付で、逆アセンブルしてみました。

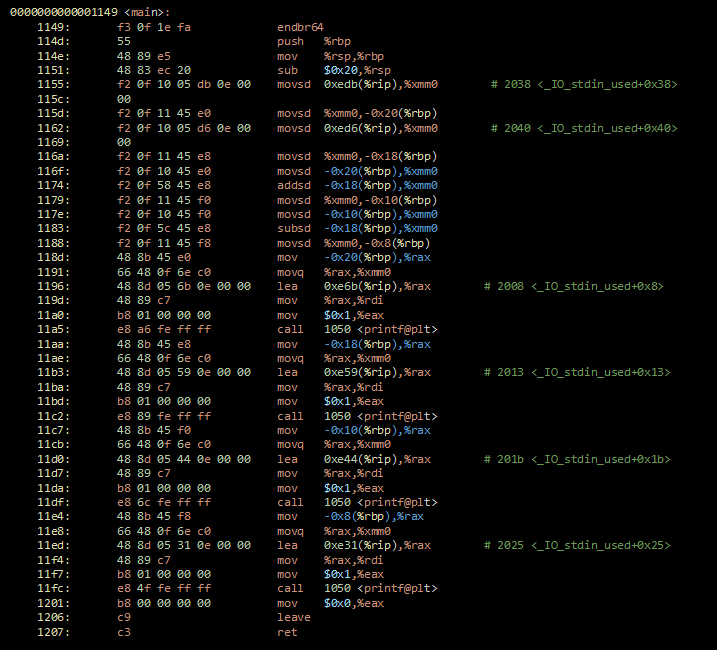
どうも、printf(“%1f\n”,(a+b)-b);の処理で、倍精度の値が出入りするxmm0レジスタへの操作が怪しいそうです。ところでxmm0レジスタってなんですかね?xmm0レジスタとは、Intel 拡張命令セットの一つとして、インテル® Pentium® III プロセッサ・ファミリで IA-32アーキテクチャに導入されたSSE(ストリーミングSIMD拡張命令)用レジスタxmmのひとつだそうです。xmmレジスタは、コア上に8つあり128ビットのビット長をもつ。浮動小数点演算や倍精度演算倍精度演算はこのxmmレジスタを使うようコンパイルされるようです。
計算中のxmm0レジスタ値を確認すれば、切り上げの事実が確認できるかもしれません?そのため、gnu製のデバッカーgdbコマンドでデバックしてみました。
xmm0レジスタ内容の変化を追跡するため、CPU命令を一命令づつ進めるstepiコマンドを使いながら1命令ずつ実行、addsd命令の前後のxmm0内部のv2_double値の変化を確認しました。
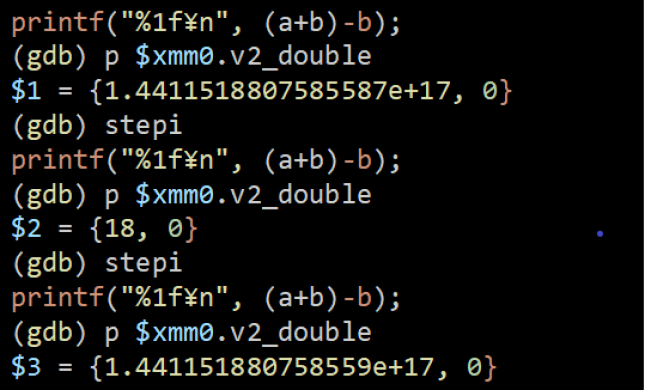
bの値、全桁表示すると、b=2^27=1.44115188075855872 × 10^17です。gdbの表示上、v2_double = {1.4411518807585587e+17, 0}がbの値のようです。一桁表示が足りないことに注意して、xmm0の値の末尾3桁の変化に注意すると、587が次の次のステップで590に変化しています。ここ、数学上では、589のはず。切り上がっています。現場を捕まえました!
インテル謹製の仕様書Intel Software Developer Manualを調べました。確かにSIMDにおける浮動小数点演算では、1バイトのみ変更されるとの記載がありました。
11.6.8 Compatibility of SIMD and x87 FPU Floating-Point Data Types SSE and SSE2 extensions
operate on the same single-precision and double-precision floating-point data types that the x87 FPU operates on. However, when operating on these data types, the SSE and SSE2 extensions operate on them in their native format (single-precision or double-precision), in contrast to the x87 FPU which extends them to double extended-precision floating-point format to perform computations and then rounds the result back to a single-precision or double-precision format before writing results to memory. Because the x87 FPU operates on a higher precision format and then rounds the result to a lower precision format, it may return a slightly different result when performing the same operation on the same single-precision or double-precision floating-point values than is returned by the SSE and SSE2 extensions. The difference occurs only in the least-significant bits of the significand.
計算機は、有限桁の数字しか取り扱えないため、非常に大きな数字に非常に小さな数字を加算すると、どうしても丸め誤差を起こすしかありません。今回のその現場を押さえることができ、腹におちました。
AIアプリケーションでよく使われているGPUでは、bfloat16(brain float point, BF16)が用いられ始めています。Bfloat16は、仮数部に7ビットを、指数部に8ビットを割り当てた数値形式です。計算速が倍精度よりも軽いため、AI系プログラムなかでも推論系処理は、計算上は十分な精度のため使われているようです。
必要なデータの精度と計算の速度に応じて、適切な演算ユニットを使い、精度と速度を確保する観点が非常に大切なことがわかりました。
