
なんかこう一昔前の動画サイトの題名みたいな感じですね。
スーパーコンピュータ「富岳」が四冠を連続達成です。四冠というと、棋士の藤井さんの方がインターネットサーチエンジンではヒットしてしまうので、勝負飯のお店で「富岳」なんてお店があったのかなんてまとめサイトに載せられそうにも思ったりしますが、まあ、勝負には違いはないので、将棋と外食メニューよりは近いお話です。
この「富岳」の四冠ですが、Linpack(HPL)はあまりに身近で実際に動かす機会も多いのですが、HPCGというのは何でしょう。

このサイトがHPCGのホームページで、現在の最新バージョンは3.1です。このHPCGには色々な特徴があって、その解説なども沢山ありますが、一番特徴的な事は何かというと、実行時間が短い!だったりします。
HPLなどを実行した経験があるとピンと来ると思いますが、科学計算のベンチマークは、兎に角、実行に時間がかかります。規模が大きくなればなるほど、この時間が凄い事になってしまいます。実際には短時間でも実行自体は可能なんですが、大抵、短時間で実行した場合、そのシステムの性能が引き出せなかったりするんですね。昔のマシンと違って、今のマシンは性能も使用可能なメモリ空間も巨大なんで、その性能をしっかりチェックしようと思うと、大規模なメモリを使用して、非常に重い計算をして、となってしまうので、どうしても実行に時間がかかってしまいます。
さらに高性能なスパコンが開発された場合、試験をするのに1ヶ月とかかかってしまうようになりそうです。そうした将来を見据えたのか、自分で作業する時、そんなのはやってられないと考えたのかは分りませんが、短時間でも十分な性能調査を、というベンチマークプログラムです。
どれくらい短時間かというと、1回の試験が60秒くらいというものです。
個人的には、それはやり過ぎじゃないかなぁと思ったりもするのですが、そういった訳で、実際に実行してみました。
実行環境は、Xeon platinum8268 2.9GHzが2CPU搭載されたノードをインフィニバンドで接続した小規模クラスター構成です。OSはCentOS 8.3で実行バイナリはoneAPI2021.2.0のmklのbenchmarkに入っているhpcg3.1のskylakeアーキテクチャ用バイナリを使用しました。
ちょっとえげつないくらいソースに手が入っている代物ですが、このバイナリを使用して実行した結果が以下のグラフです。
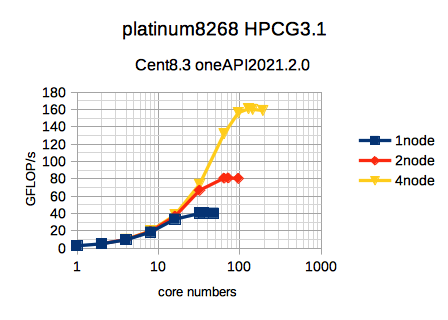
かなり綺麗に、使用したコア数に応じてGFLOP/sが出ているのが分りますね。
興味深いのは、同じ並列数でも、例えば、1node32並列と2nodeで16+16の32並列では、大きく結果が違っている事です。こうした特徴は、特に計算に必要なデータが大量にあるようなアプリで起きがちな傾向があります。
どうしてそうなるかというと、1nodeと2nodeでは、マザーボードが1つか2かという事で、単純に倍違うので、データアクセスが多くてマザーボードのパスやメモリチャンネルが一杯になってしまう場合に、大きく差が出ます。
単純にコア数が多くなれば性能が上がる訳ではない、という事で、1枚のマザーボードに乗っているコア数が多くなればなるほど、CPU以外部分の速度が必要になってくるという事です。
CPUのコア数を倍にするのは、実際は兎も角、ダイを大きくしたらいいのですが、マザーボードバスやメモリチャンネルを倍にするのは、とっても大変です。こうした傾向も、HPCGでは見えてくるようですね。ARMベースの「富岳」には向いたベンチマークではないかなと思います。
もっとも、60秒という短時間で実行した為じゃないかなとも思っていたりもします。実際にMDなどの開発を行なっている人達の間では、100秒を切ったようなベンチの数値は信頼出来ない、なんて意見もあります。
どういう事かというと、あまり短時間で終るベンチだと、プログラムやデータのロード、出力の書き出しなどの計算実行以外の部分が、総実行時間の中に占める割合が多くなってしまうので、実計算で重くて長い計算を実行してみたら傾向が違った、という事がありがちだからだったりします。先にマザーボードバスなどの性能を上げるのは大変、という話をしましたが、短時間のこうした傾向のあるベンチでチューンしたシステムを作ると、高いパーツを使用したのに、その金額の割に性能が伸びてない、と、なってしまう場合もあります。
上記のグラフから、並列のMPIスレッドのサイズが巨大な、データアクセスが多いような傾向のアプリを使用する場合などの指標に使うには十分だなといったように、そこをどう読み換えてゆくかもエンジニアの腕だったりもします。
さて、「富岳」ですが、こちらのアナウンスのように、弊社と理化学研究所は「富岳」のクラウド的利用に関する共同研究を行っており、「富岳」の使用や発展に貢献をしようとしています。また、「富岳」で実際に計算をするアプリを開発したいという場合、富士通様のFUJITSU Supercomputer PRIMEHPC FX700の販売も行なっており、現在、「富岳」四冠キャンペーンを行なっています。
ご興味がおありの場合、どうぞ弊社営業に一声おかけください。

