
背景
これまで科学技術計算のボトルネックはCPUなどの計算そのものによるものでした。ストレージへの要求も、巨大ファイルの格納が可能な大容量、それを保存するためのスループット(帯域幅)が主要な要件だったように思います。
しかし、昨今のAI・ビッグデータのブームの到来とともに、膨大な数のデータが主役となっています。いかに多くのデータを効率的に保存し、検索可能とし、再利用ができるか?が鍵となっています。特にデータ同士の相関を取るなどの統計処理において、その傾向は顕著です。これまでデータベースのための要件であった高IOPS・低レイテンシといった応答性能の向上が、ストレージハードウエア及びファイルシステムに対して求められています。
そのための解としてオールフラッシュストレージなどが数多く市場にでていますが、HPC用途として大容量を同時に要求すると価格が高騰してしまい、なかなか選択肢としては難しい状況にあります。
そうした中、NVMe, Intel DCPMM, NVDIMM など、不揮発性のメモリデバイスも数多く出てきています。それらを直接的にデバイスとして使うケースもありますが、ここでは従来のRAIDを用いたファイルサーバーのキャッシュとして使うことで、上記のような問題の一部は解決できる可能性を検討したいと思います。
本検証では、PCI Expressスロットへ搭載できる不揮発性DRAMデバイスを用いました。これを用いた理由はいくつかあります。
- NANDフラッシュのような性能劣化要因がない。
SSDのようなNANDフラッシュベースのデバイスは、チップ単体で元来高い性能を持たないため、高速化のため内部にキャッシュを持たせていたり、並列化して見た目の性能を稼いでいます。それゆえに性能の出方にばらつきがでることがありますが、DRAMであればそもそもその問題がありません。ただし、DRAMデバイスよりはるかに大容量な製品があるため、一度に書き込むサイズが膨大な場合は選択肢となりえます。 - 他のデバイスのように搭載機材を選ばない。
NVDIMMやIntel DCPMMは搭載可能なマザーボードなどが限られるため、必要なシステムに搭載できないケースがあります。今回採用したPCI Express搭載のタイプであれば、PCやエッジコンピューターでも搭載可能な場合があります。 - 一般にはあまり知られていないが、ユーザーの問題解決につながる技術や製品をうまく使い、ソリューションとして展開を検討したい。
検証対象の構成
弊社で販売しているファイルサーバーに近い構成にキャッシュとしてデバイスを追加し、どこまで効果があるのかを見ます。用意したのは以下のとおりです。
- CPU: Intel Xeon E5-2687W v3
- メモリ: DDR4-2133 256GB
- RAID: Broadcom MegaRAID 3108
- ドライブ: WesternDigital(HGST) 4TB 60本
- RAID構成: RAID6 15D/2P x4 の RAID60
- RAIDキャッシュ: Read Ahead / Write Back
- OS: CentOS 7.5 ファイルシステムは XFS
- キャシュデバイス: NETLIST社製 ExpressVault3 16GB
- キャッシュ構成: LVM2によるWrite Back
ただし用意したJBODの関係上、RAIDカードとJBOD間はマルチパス構成ながらSAS2(6Gbps)になっています。
検証内容
生のRAID60とキャッシュを接続した状態で、同一条件のベンチマークをスループットと同期アクセス性能という2つの見地で取得しました。
スループット測定にはIORを用いました。HPCユーザーにはおなじみのMPIを使って複数プロセスからの多重I/Oでのベンチマークを行います。MPI-IOやHDFでのアクセスも可能ですが今回は使いません。同期アクセスの検証にはfioを用います。スレッド並列で多様なI/Oを発生させ、IOPSやレイテンシについての詳細な検証が可能です。デバイスの対応範囲が広く、アクセス手法を豊富に持つため最新デバイスの性能傾向を見るのに良く使われています。
どちらもI/Oは32並列で、1プロセスないし1スレッドについて1ファイル、個々のファイルサイズとして128MB,256MB,512MB,1GBとしています。1GBのケースではキャッシュサイズを超えていることにご注意ください。アクセス単位は4KB,64KB,256KB,1MBとしています。また、同一のベンチマークを5回繰り返して平均の成績を見ています。
アクセス内容としては、IORではPOSIXでのシーケンシャル、fioではpsyncモードでランダムリードライト、としています。
検証結果
スループット
OSが管理するメインメモリのキャッシュの効果のために、リード性能は極端に高い数値が出ます。そこで書き込み性能のみを抽出してみています。
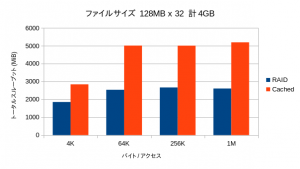
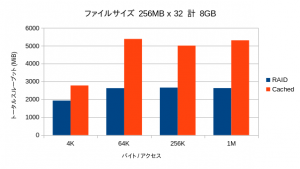
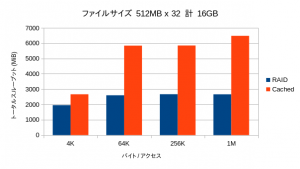
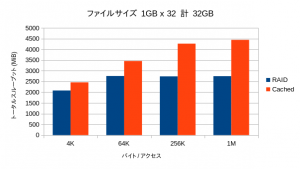
全領域に渡って大幅な性能向上が見られています。特にキャッシュ容量を超えた領域でも劣化が少なく、オーバーヘッドが小さいことを物語っています。
同期書き込み
OSによるメインメモリ上のキャッシュの効果がなくなるため、リードライト共にほぼ同一の性能が表示されていました。IOPSに関しては縦軸がログスケールであることにご注意ください。性能が良い方向のベンチマークは一瞬で終わってしまうのに対し、劣化するモードでは長時間を要し、数値自体も取得する度にぶれます。特にディスクへのアクセスが入るリードのレイテンシ(ここではデータを開示していませんが)に関しては5桁くらい偏差します。
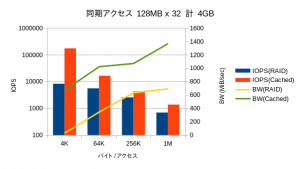
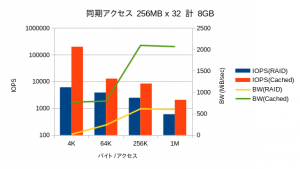
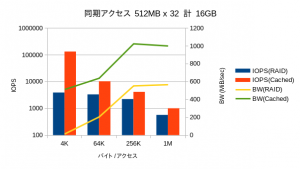
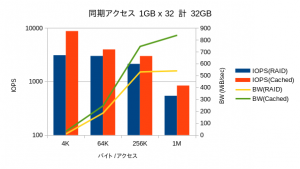
4KBのアクセスではRAID60では帯域がゼロに近く、ほとんどデータを書き込めていないことが分かります。そうしたファイルアクセスが必要となる用途では、HDDベースのファイルストレージはほぼ役に立たなくなることが予想されます。
キャッシュサイズを超える32GBが対象になった場合では、当然ながら性能が下がるものの、オーバーヘッドがほとんど見られず、依然として高い性能を示しています。
結論
不揮発性DRAMデバイスを用いたキャッシュ追加は、小サイズ多ファイルという、HPCユーザーの昨今のI/O要求の変化に対し、有効な対応策であると言えます。
HDD 60本という構成なら、特にシーケンシャル性能はなんとかなるだろうという予想を覆し、キャッシュが全方位的に有効であることが分かりました。逆にディスクの搭載本数が限られるケースなどでは更に性能差がひらくことが予想されます。
LVM2で構成されたボリュームであれば、キャッシュの後付けや取り外しができますので、既存システムの強化や事前検証も可能です。
