
深層学習の学習ベンチマーク
今回、私は2回目の投稿なのですが、もう書くことがなくなってきました。今回は深層学習のベンチマークの結果ではなく、うんちくを書いていきます。うんちくと言っても、私が持っているものは、正答率に関してではなく、学習速度に関するものとなります。
学習速度について
学習速度は、主に演算デバイス(CPU、GPU)の処理速度、演算デバイスのメモリ速度、学習モデル、フレームワーク、バッチサイズ、演算デバイスのメモリ容量、演算デバイス間通信の速度、データアクセス速度などで変動します。ハードウェアは簡単に変更できないですが、ソフトウェアは比較的容易に変更が可能なので、もしかしたら役に立つことが全くない、ということも無かったり有ったりするかもしれません。
NVIDIA® Tensor Core GPUを搭載しているマシンを、GTXを搭載しているマシンと比べて遅いという問い合わせが来ることがあるのですが、学習モデルが小さいケースがだいたいです。3層の全結合のMNISTなどを使用したりすると、GPUの演算よりもCPUの演算の方が長くなり、GPUよりもCPUの演算速度で、学習速度が決まってしまいます。
フレームワークは、最近は、mxnetが速いようです。ここら辺はアップデートが激しいので、その時々で速い遅いは変わります。速度を気にしないで使いやすいのを使うのが、ほとんどだと思いますが。
バッチサイズは、小規模では、とにかく上げれば速度が向上します。バッチサイズを上げるとGPUメモリを多く消費して、GPUメモリを消費しつくすとプログラムが落ちますが、ギリギリを狙ってベンチマークをします。バッチサイズは学習において、正答率を左右してしまうハイパーパラメーターなので、上げることが正答率に悪影響が出る場合もありますが、ベンチマークは高い速度さえ示せれば良いので、関係ありません。
ベンチマーク概論
学習速度とバッチサイズの関係は、簡単に定式化できます。
まず、バッチ毎の計算時間を、2種類の計算処理の計算時間に分けます。
- バッチサイズに比例して、計算量が多くなる処理の計算時間。主に順伝播の計算。
- バッチサイズに対して、一定の計算量の処理の計算時間。主に逆伝播の計算。GPU間の勾配平均計算、モデルの更新。
Deep Learning の学習は、バッチサイズ分のデータをモデルに適応していきます。その時の処理の計算量は、バッチサイズに比例し、複数のGPUを使用する場合は、この部分だけ並列されます。その後、モデルすべてのパラメーターに対して勾配を計算します。複数GPUで計算する場合は、その勾配をGPU間で通信し、平均を計算し、最後にモデルを更新します。この時の処理の計算量は、モデルのパラメーターの数で決まり、バッチサイズは関係ないです。これらの時間をそれぞれ、t1, t2 とします。
t1は、バッチサイズに比例するので、下記のように表すことができます。
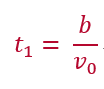
ここで、bはバッチサイズです。v0は、理想学習速度と名付けます(決して、一般的な呼び名ではありません)。理想学習速度は、バッチサイズに比例する計算処理部分の処理速度を表しています。
これらを使用して、全体の学習速度v を求めると、
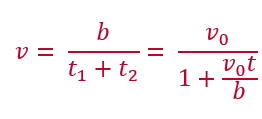
ここで、t = t2 としました。t は、コスト時間と名付けます(これも私が勝手に呼んでるだけです)。コスト時間は、バッチサイズによらず一定です。b → ∞ のとき、v → v0 となり、理想学習速度に近づくことが分かります。
この導出した理論モデルを実際のベンチマークに適用してみたのが、下のグラフです。下のグラフは、あるGPU、あるモデル、あるデータセットにおいて、GPUが1つの時と、2つの時に、様々なバッチサイズでベンチマークした結果と、その結果を上記の式に適用したものです。
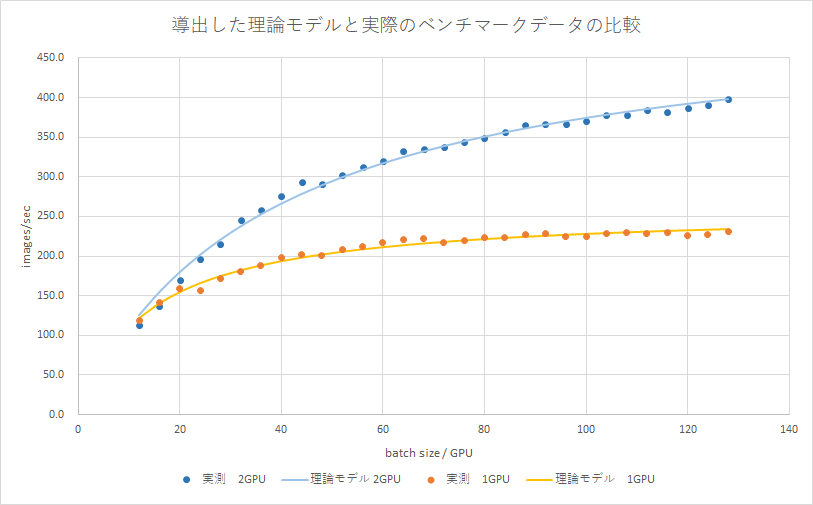
実測値と、よく合ってることが分かります。実は、この2GPUは、P2P通信ができない状態でベンチマークしています。その影響でコスト時間が2GPUの時は、1GPUの時の約3倍になっています(1GPU時、0.054秒、2GPU時、0.15秒でした)。これによりバッチサイズを上げても、学習速度が1GPUの時に比べて飽和しにくいことが分かります。GPU間の通信速度が、学習速度に対して、どのように影響が出るかが分かると思います。ちなみに、1GPU、2GPU時の理想学習速度は、それぞれ、258.1、513.8 images/sec でした。
導出した式は、学習時間がバッチサイズの一次関数である条件下で成り立ちます。また、学習に関してと書きましたが、基本的には推論でも同じことが言えて、推論の場合、逆伝播処理が無い分、コスト時間が下がり、飽和するバッチサイズが小さくなります。
あとがき
今回は、学習速度とバッチサイズの関係を中心に書きました。もしかしたら、ハードウェアを買う時に参考になることもあるかもしれません。
