Ada Lovelace アーキテクチャ
Geforce RTX 4090は、新型GPUアーキテクチャ「Ada Lovelace」を採用する初めてのGPUです。製造プロセスが4nmになり微細化が進み、GPUコア数、周波数が劇的に伸びました。また、Tensorコアは第4世代となり、FP8演算エンジンも搭載されました。
RTX4090スペック
今回、比較したGeforce RTX3090と、Geforce RTX4090のスペックを下表にまとめました。
| Geforce RTX 4090 | Geforce RTX 3090 | |
| アーキテクチャ | Ada Lovelace AD102 | Ampere GA102 |
| GPU Boost時クロック | 2520 MHz |
1695 MHz |
| CUDAコア | 16384 | 10496 |
| TensorCore数 | 512 | 328 |
| メモリ仕様 | GDDR6X | GDDR6X |
| メモリ帯域 | 1008 GB/sec | 936 GB/sec |
| メモリ容量 | 24 GB | 24 GB |
| 最大消費電力 | 450W | 350W |
| FP32理論性能 | 82.6 TFLOPS | 35.6 TFLOPS |
| FP16理論性能 | 82.6 TFLOPS | 35.6 TFLOPS |
|
TensorCore FP16 理論性能 |
330.3 / 660.6 TFLOPS |
142 / 284 TFLOPS |
|
TensorCore TF32 理論性能 |
82.6 / 165.2 TFLOPS |
35.6 / 71 TFLOPS |
|
TensorCore FP8 理論性能 |
660 / 1321.2 TFLOPS |
TensorCore理論性能は、通常時/スパース機能時で表示しています。
スペック上はRTX 4090の方が、RTX3090と比べて、2.3倍の性能となります。
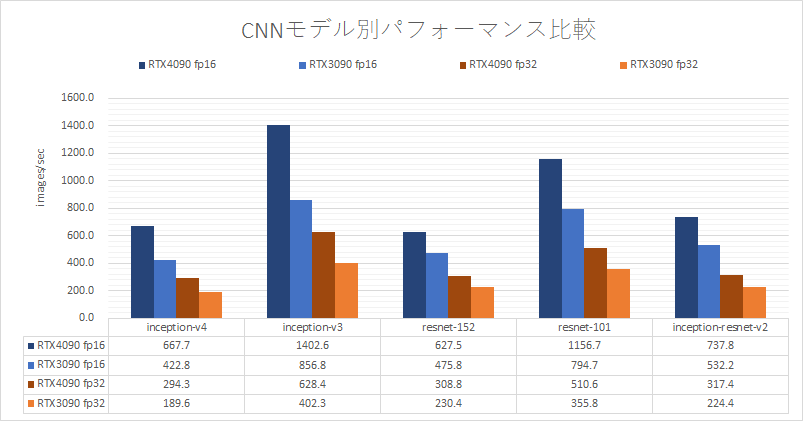
CNNベンチマーク(1GPUどうしの比較)
RTX4090とRTX3090の速度を、画像認識のモデルで比較しました。FP16、FP32ともに、1.3~1.6倍 RTX4090の方が速い結果となりました。理論性能に届かないのは、スペック上微増に留まったGPUメモリ帯域幅が足を引っ張ている可能性があります。
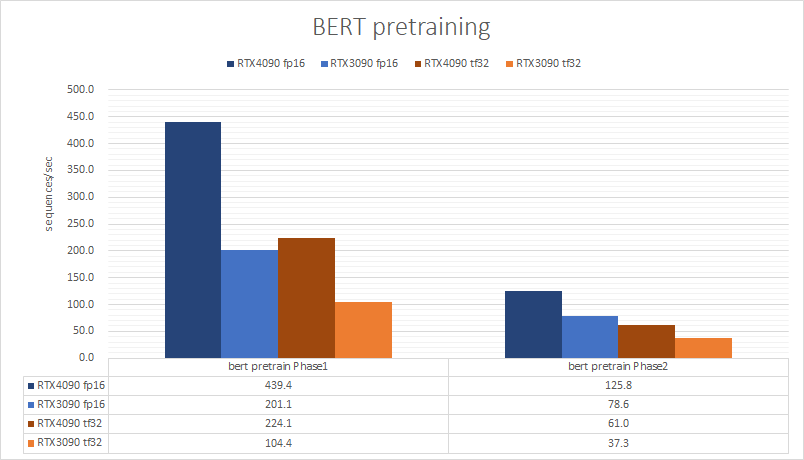
BERT pretraining ベンチマーク(1GPUどうしの比較)
次に、自然言語処理のBERTのpretrainingで、RTX4090とRTX3090の速度を比較しました。phase1で、2.1倍、phase2で、1.6倍という結果になりました。phase1は、ほぼ理論性能通りとなりました。phase2は、CNNベンチマーク同様に、GPUメモリ帯域幅で律速していると思われます。
Transformer Engine?
RTX4090に、FP8演算が搭載されたことにより、Transfer Engineも搭載されているのではないか、という憶測があり、こちらでも試みてみました。
https://docs.nvidia.com/deeplearning/transformer-engine/user-guide/examples/quickstart.html などを参考にBERTベンチマークで使用したコードを変更していきます。まだ、pytorchの関数を完全に置き換えるまでには対応してない部分もありましたが、なんとか実行するところまで進みましたが、下記のようなエラーに終わりました。
AssertionError: Device compute capability 9.x required for FP8 execution.
RTX4090のComupteCapabilityは、8.9なので、FP8を使用したTransformer Engineは利用できませんでした。
規格外(物理)
今回は、RTX4090のベンチマークを行いました。BERTのpretrainingで、RTX3090の2倍の性能を示すなど、規格外の性能と言えます。まずは、RTX4090が収まる筐体から探すので、暫くお待ちください。(液冷でない、3連Fanモデルなどもありますが、それでも高さがオーバーして蓋が閉まらない見込みです。)


