
はじめに
近年、生成AIや大規模言語モデル(LLM)の活用がビジネス・研究・開発の現場でも急速に進んでいます。しかし、「実際にどう使えばいいのか分からない」「技術的なハードルが高そう」「セキュリティ上のリスクが高い」「回答の確からしさが保証できない」と感じている方も多いのではないでしょうか。
本記事では、LLMの概要からセキュリティ・カスタマイズ性に優れたローカルLLMの実践、RAGの実装までを解説します。
大規模言語モデル(LLM)とRAG (Retrieval-Augmented Generation)とは
大規模言語モデル(LLM)は、膨大な量のテキストデータを学習することで、人間の言語を理解し生成する能力を持ったAIモデルです。
文脈を把握して自然な文章を生成することが可能で、質問応答、文章の自動要約、翻訳、創作文章の生成など、さまざまな言語処理タスクを実行できます。
この技術によって、チャットボット、検索エンジン、推薦システム、自然言語インターフェースなど、多岐にわたる分野で活用され、業務の自動化や顧客対応の効率化に役立つと期待されています。また、専門分野に特化したカスタムモデルを構築することで、特定の業界や用途に最適化された応用が可能です。
また、LLMは大量のパラメータを持つため、効率的な計算資源(GPUサーバーなど)の活用が求められます。適切なハードウェアと最適化手法を組み合わせることで、実用レベルでの高速な応答や大規模な処理が実現されています。
しかしながら、LLMは膨大なデータから言語パターンを学習する一方で、「ハルシネーション」と呼ばれる、事実に反する情報や誤った応答を生成するリスクがあります。これは、学習データの偏りや情報の更新遅れ、あるいは単純にモデルの生成アルゴリズムの特性によるものです。
こうした正確性の懸念に対処するための有力なアプローチとして、 RAG(Retrieval-Augmented Generation)という技術があります。
RAG(Retrieval-Augmented Generation)とは、大規模言語モデル(LLM)に外部の知識を組み合わせて回答を生成する技術です。ユーザーの質問に対して、まず関連する情報を事前に用意したドキュメントなどから検索(Retrieval)し、その情報をもとに自然な文章で回答を生成(Generation)します。これにより、モデルの事前学習に含まれない最新情報や社内特有のナレッジを活用した、より正確で信頼性の高い応答が可能になります。
RAG環境の構築に必要な要素
RAG環境を構築するためには、以下の3つの要素が必要です。
LLMモデル
LLMは、大規模言語モデルとして自然な文章の生成を担います。ユーザーの入力に基づいて適切な回答を生成する主要な役割を持ち、RAG全体の「Generation」部分を担います。
embeddedモデル
文書やテキストデータを数値ベクトルに変換する役割を果たします。これにより、テキスト間の類似性を計算しやすくなり、検索(Retrieval)工程で関連性の高い情報を抽出するための基盤となります。
reranking
検索された候補データの中から、最も適切かつ関連性の高いものを再評価・順位付けするプロセスです。これにより、LLMに渡す情報の品質と精度が向上し、より正確な回答生成につながります。
これらの要素を組み合わせることで、効率的かつ正確なRAG環境が実現され、利用者のニーズに合った高品質なチャットボットやAIシステムが構築可能になります。
Difyでチャットボット作成に挑戦
それでは、実際にRAG環境を作ってみましょう。
今回は、弊社の新人営業・森田が、技術・坂本のサポートを受けながら、チャットボット作成に挑戦します。
坂本
よろしくお願いします。今回はチャットボットを作って公開するところまで、一通り体験いただこうと思います。
森田
よろしくお願いします!右も左もわかりませんが、業務に役立つチャットボットが作れたらいいなあと思います。
坂本
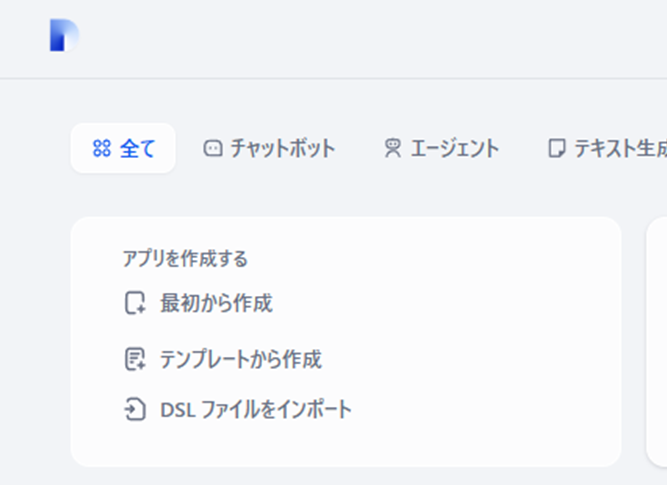
チャットボット開発ツールは様々なものがありますが、今回はDifyというアプリを使うことにします。あらかじめ、DifyからローカルLLMが利用できるところまでは設定しておきました。 早速ですが、左上の「アプリを作成する:最初から作成」を選択してみてください。
Difyとは:
初心者から上級者まで誰でも簡単にチャットボットやAIアプリケーションを開発できる、オープンソースのLLMアプリ開発プラットフォーム です。
直感的な操作性と、設定画面とプレビュー画面が連動するインターフェースにより、変更内容をリアルタイムで確認しながら開発を進められます。
また、自動プロンプト生成やRAG(Retrieval Augmented Generation)機能が搭載されており、効率的かつ高品質なシステム構築が可能です。

森田
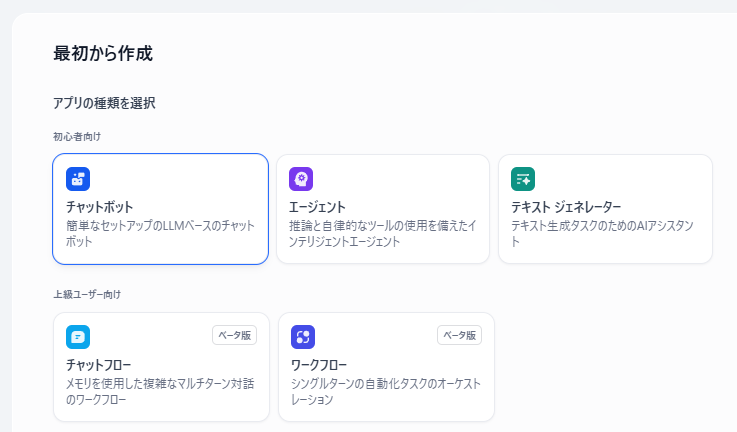
選択肢がたくさん出て来ましたね…。どれを選ぶか迷います。
坂本
今回は一番簡単な「チャットボット」を選択しましょう。
森田
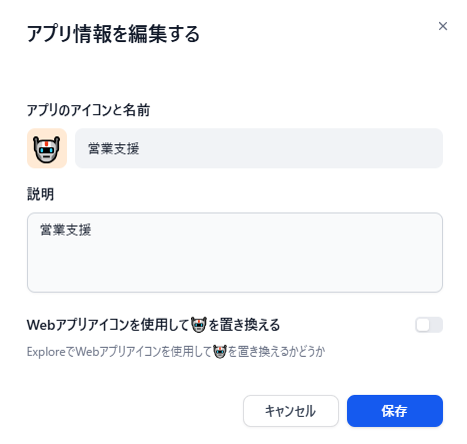
了解です!名前は『営業支援』にしました。
坂本
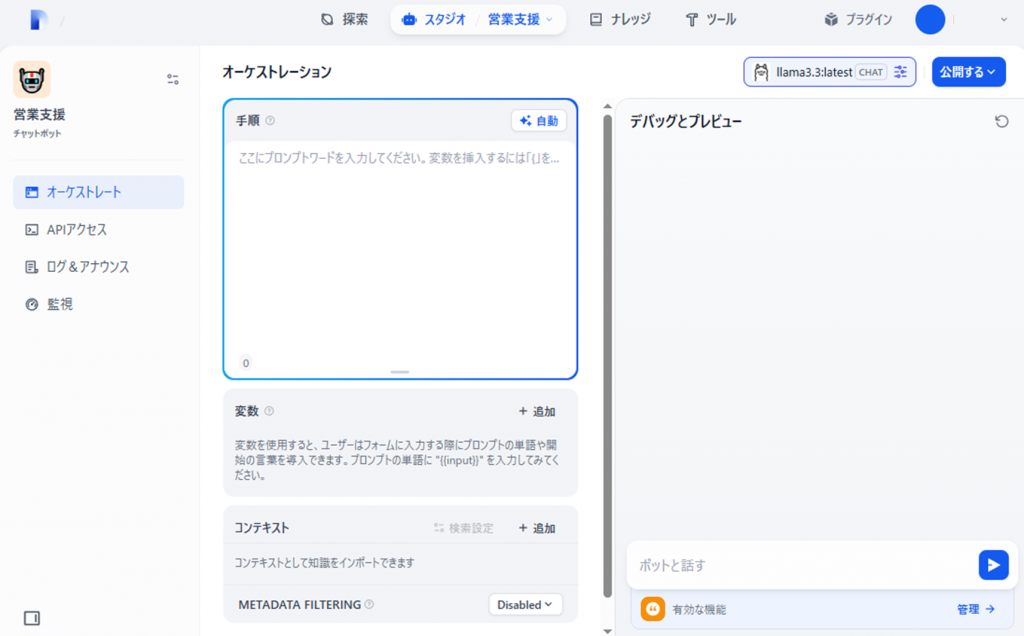
無事作成出来ていますね。画面左の「オーケストレーション」がプロンプト入力画面、画面右がプレビュー画面になっています。ここから早速、詳細を設定していきましょう!
チャットボットの詳細設定
プロンプトの入力
森田
「営業支援」と言っても、具体的にどんなプロンプトを入力したらいいのかわかりません…。
プロンプトとは:
プロンプトとは、AIに「何をしてほしいか」を伝えるための指示文や入力文のことです。
プロンプトには次のような役割があります。
-
AIの出力内容をコントロールする
(例:短く答えて、専門用語を使わないで、など細かい指定も可能) -
会話の流れや文脈を設定する
(例:「あなたはITエンジニアです。質問に専門的に答えてください」など) -
タスクを明確に伝える
(例:「次のテキストを英語に翻訳してください」など)
プロンプトの工夫次第で、AIの出力結果は大きく変わります。
特に最近では「プロンプトエンジニアリング」と呼ばれる、より良いプロンプトを設計する技術も注目されています。
坂本
そういう時は、右上の「自動」ボタンを押してください。やりたいことを入力すると、それに適したプロンプトを生成できます。上手いものが出来るかは性能次第、というところもありますが…。
ありがとうございます。雛形を生成してもらって、自分で手直しするのもよさそうですね。
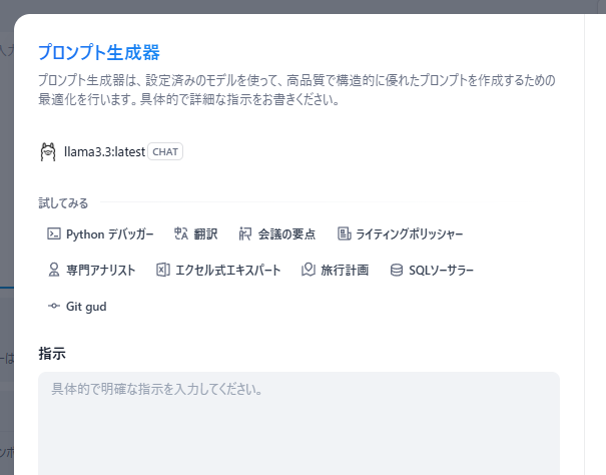
モデルの選択
森田
この「llama3.2-vision」というのは何ですか?
坂本
チャットボットのエンジンをどのモデルにするかを選択可能なんです。例えば、DeepSeekに切り替えることもできますよ。用途に応じて、その分野が得意なモデルを選ぶのもアリですね。各モデルのインストールにはOllama(オラマ)を利用しています。
Ollamaとは:
Ollamaは、大規模言語モデル(LLM)をローカル環境で実行できるオープンソースのツールです。これにより、クラウドに依存せず、自分のコンピュータ上で直接LLMを利用できるようになります。
森田
モデル選択画面を開くと、「パラメータ」という項目も出て来ますね。
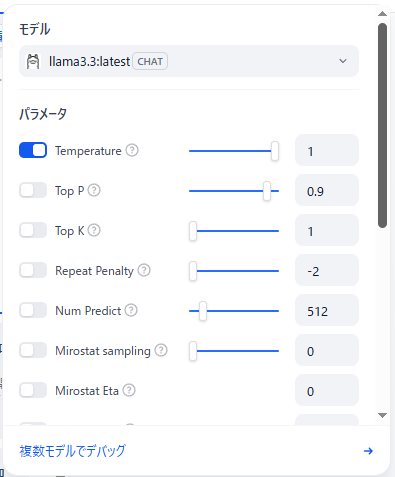
坂本
これらを調整することで、モデルの応答の“性格”を自由にコントロールできるんです。例えば Temperatureは、0に近いと事実重視で安定した応答、値を上げると創造的で多様な応答になります。用途や好みで調整してみてください。
Temperature:0に近いと事実重視で安定した応答、値を上げると創造的で多様な応答になります。
Top P / Top K:出力候補の絞り込みに使う。Top Pは確率合計、Top Kは候補数で制限します。
Repeat Penalty:同じ語句の繰り返しを抑える設定。負の値だと逆に繰り返しやすくなります。
Num Predict:出力されるトークン数(文字数に近い)を指定します。
Mirostat sampling / Eta:応答の一貫性と調整性に関する高度な設定です(通常はオフで構いません)。
RAG(Retrieval Augmented Generation)実装のポイント
森田
プレビューでボットを動かしてみましたが、望んだ内容が返ってきません…。回答の中にブランクがあります。
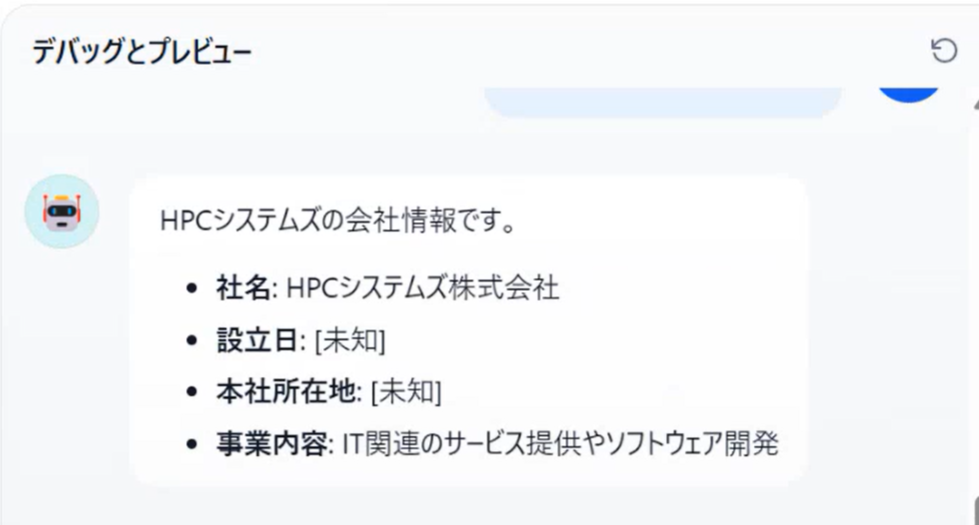
坂本
標準のLLMは一般知識に明るいですが、業界の専門知識には疎いです。知識を増やし、誤った回答を防ぐために、RAGを使ってみましょう。下の「コンテキスト」という欄から設定できます。
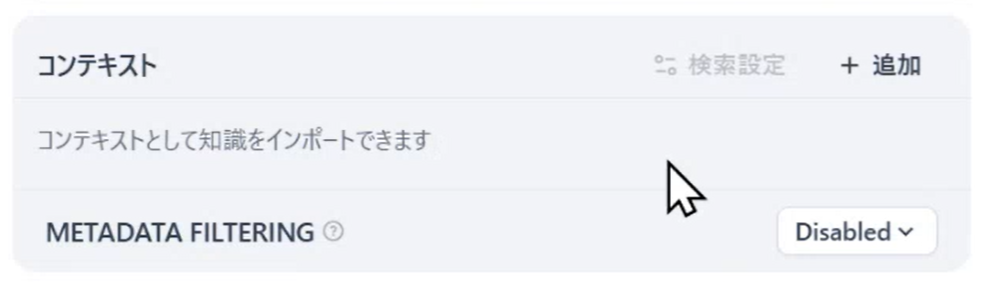
森田
アシスタント業務を任せたいので、プレゼン資料やパンフレットを読み込ませてみます。
ローカルLLMなので、機密情報が含まれていても安心して活用できるのが便利ですね。
様々なファイルがインポートできるようですが、どういった形式が向いているんでしょうか?
坂本
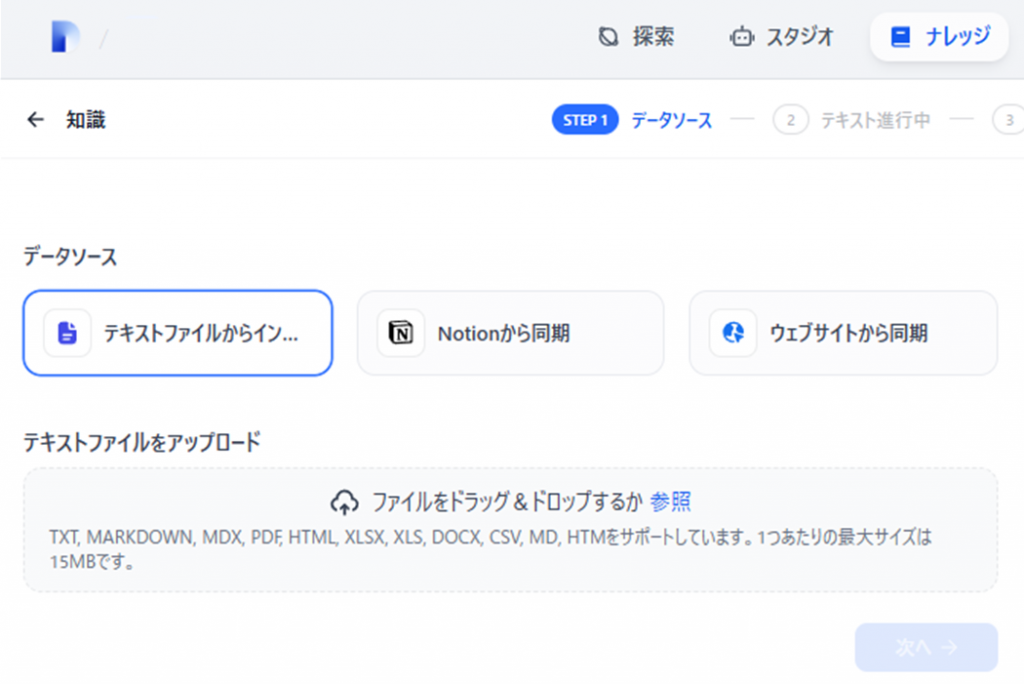
AIは文字だけで情報を理解するので、場合によって表やPDFが不向きな場合はあります。あとは読み込ませたドキュメントファイルを正しくAIが理解できるよう、チャンク設定を確認しましょう。今回はデフォルトのままで進めて問題ないと思いますが、ファイルの内容によってはここを調整する必要があります。
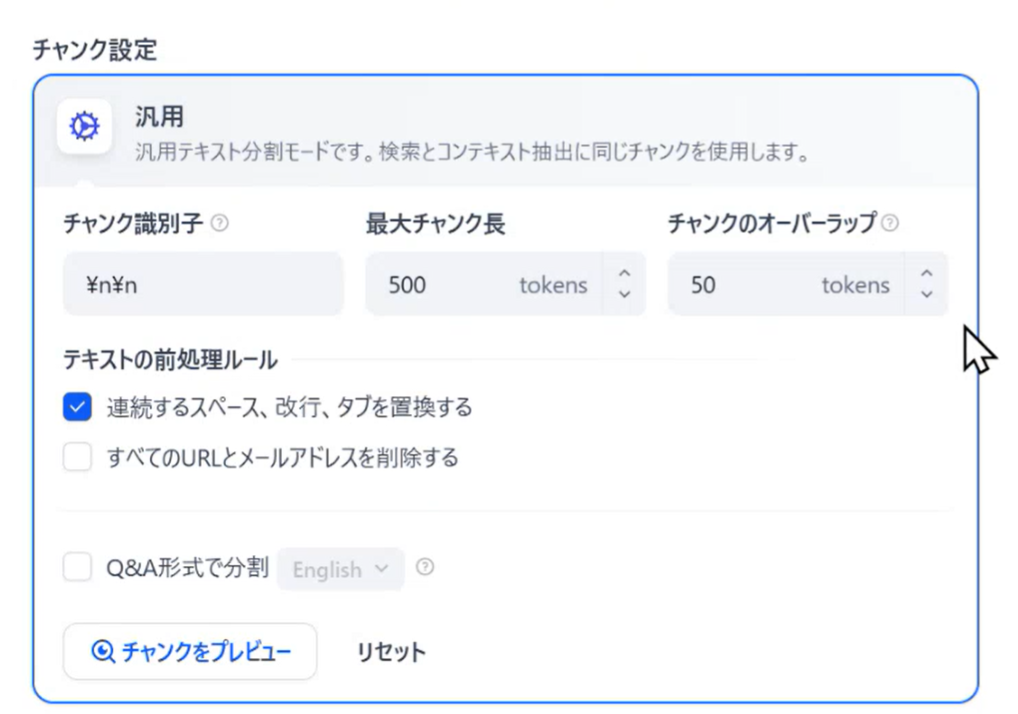
チャンクとは、AIが文書を処理しやすくするために情報を小さな単位に分割する技術です。RAGでナレッジを活用する際、長文のドキュメントをそのまま使うのではなく、数百文字程度の意味のまとまりごとに分割(=チャンク化)します。これにより、ユーザーの質問に対して関連性の高い部分だけを効率よく検索・抽出できるようになります。改行や段落ごとのルールで区切ることで、内容の精度や検索性能を高めることができます。
チャットボットの検証~保存・公開
坂本
設定は完了しました。テストしてみましょう!

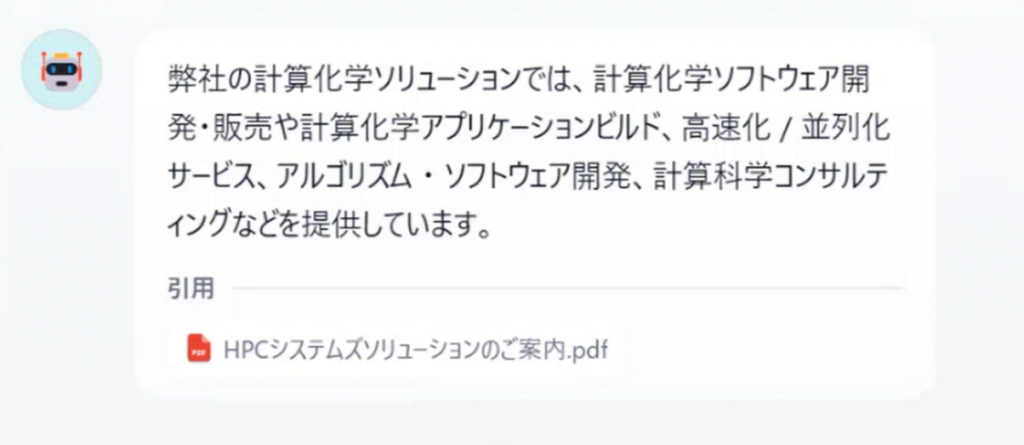
森田
今度は望む回答が出て来ました。情報の引用元も明示されていますね。
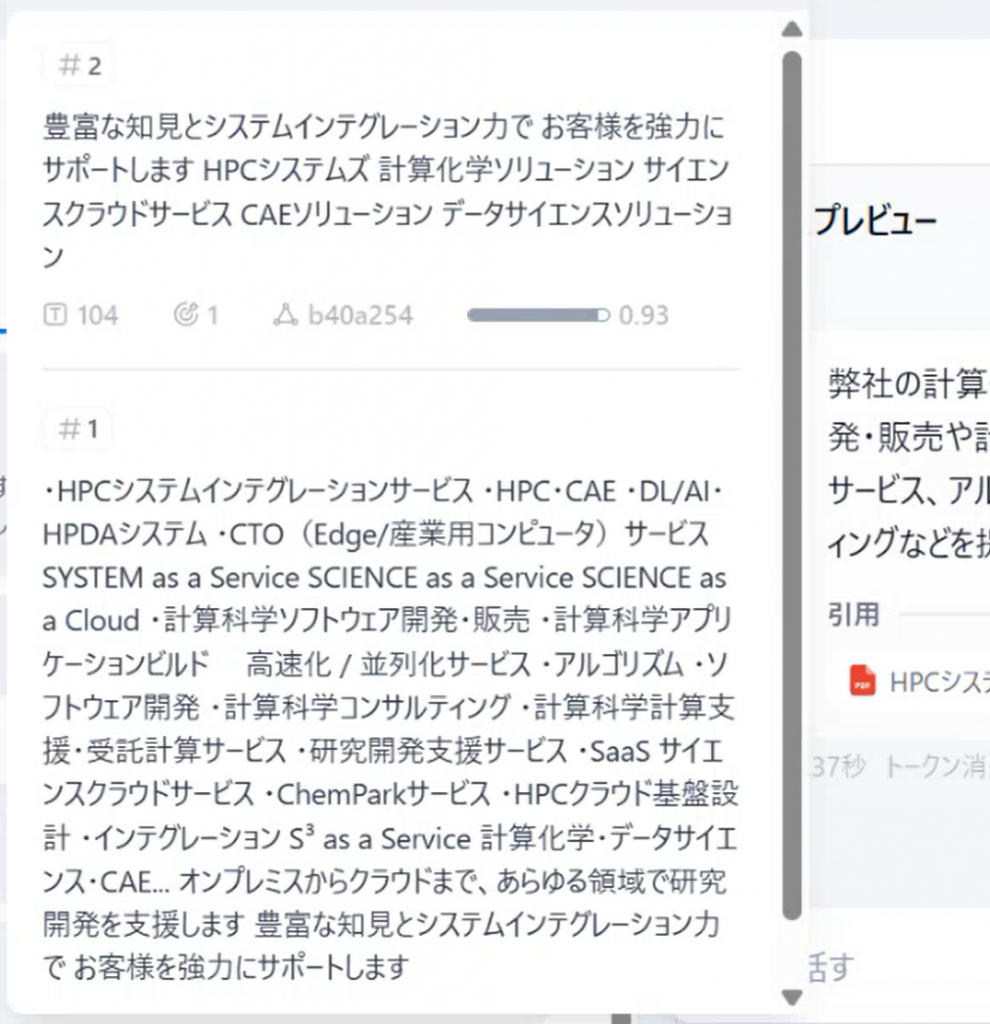
坂本
情報の確からしさが上がりましたね。回答の根拠となったドキュメントと、そのスコアも確認可能です!PDFはあまりAI学習に向いていないので、内容が崩れていますが…。
坂本
あとは右上の「公開する」ボタンをクリックすることで、このボットアプリをリリースできます。
リリース後もユーザーのニーズに合わせてドキュメントを更新したり、プロンプトを修正して使い勝手をよくしていけますよ。
ハードウェア選定の重要性
森田
実際に動かしてみると、ハードウェアへの負担が大きいことがわかりますね。
坂本
精度の良い大きなローカルLLMモデルになるほど、GPUメモリを多く必要とします。 そのため、適切なハードウェアを選ぶことが重要ですね。
森田
今使っているワークステーションは、性能もですが、騒音が気になります…。
坂本
ローカルLLMを動かせるようなハイスペックなサーバーだと発熱もすごいので、ファンや冷却装置の動作音が気になることが多いですね。特に、50dBを超えると作業環境としてはかなり騒がしく感じられます。
森田
なるほど。特にオフィスや共有スペースで使用する場合、ハードウェア選定の際には性能だけでなく、静音性も重要な要素ですね。
最後に
坂本
さて、一通りLLMとRAGを活用したチャットボット作りを体験していただきました。いかがでしたか?
森田
思ったよりサクサク作れるというのが率直な感想です。プロンプトすらAIで生成できるというのは驚きでした。ドキュメントを整備して拡充すれば、専門知識を備えた最高のアシスタントが生まれそうですね。
ローカルLLMなので、モデルやパラメータを自由にカスタマイズ出来るというのも便利そうです。
坂本
一般利用を想定して公開されているAIチャットボットアプリではどうしても自由度に限界がありますから。機密情報の取扱いについて懸念がないこともメリットですね。
森田
自分でイチから作らなければならないというのは大変そうだと思っていましたが、その意識が払しょくされました。先生のおかげです!ありがとうございました。
坂本
生成AIもどんどん進化し、自力でチャットボットを作るハードルはどんどん下がっています。面白い活用方法を思いついたら是非ご相談ください!
今回の記事では、営業社員が技術社員と協力してDify上でチャットボットを構築する過程を通じて、LLMとRAGの活用方法を学びました。実際に触ってみることで、生成AIの仕組みや活用イメージが具体化されたのではないでしょうか。
私たちHPCシステムズは、ローカルLLMの導入やGPUサーバーの構築に豊富な実績を持っています。「社内向けに安全なAI環境を整えたい」「LLMを活用して業務改善したい」とお考えの方は、ぜひお気軽にご相談ください。専門スタッフが、導入から運用までしっかりとサポートいたします。
ローカルLLMを始めるならHPCシステムズ
ローカルLLMスターターセット
ローカルLLM・RAG開発に最適なGPU環境を最短で構築。機密性の高いデータを用いて生成AIを活用するためのご支援を行っております。
詳細は以下のリンクからご確認ください。
gpt-oss 検証結果速報
【2025/8/12 更新】
OpenAIから発表された新しいオープンソースモデル「gpt-oss」の技術検証を実施しました。
| モデルサイズ | VRAM要件 | context length | embedding length | quantization | 推論速度 |
|---|---|---|---|---|---|
| 120B | 80GB | 131,072 | 2,880 | MXFP4 | 35~40 Token/s (A100 x8) |
| 20B | 15GB | 131,072 | 2,880 | MXFP4 | 67 Token/s (A100 x1) 102 Token/s (H100 x1) |
NVIDIAの最新GPU、RTX PRO 6000 Blackwell Max-Qを使用した際のGPT-OSSモデルの推論速度ベンチマーク結果です。
| GPU | モデルサイズ | 消費電力 / TDP | メモリ使用量 / 総容量 | 推論速度 |
|---|---|---|---|---|
| RTX PRO 6000 Blackwell Max-Q Workstation Edition 1基 | 120B | 272W / 300W | 64,657MiB / 97,887MiB | 95.70 tokens/s |
| 20B | 281W / 300W | 15,613MiB / 97,887MiB | 131.42 tokens/s | |
| NVIDIA H100 Tensor Core GPU 1基 | 120B | 213W / 350W | 64,556MiB / 81,559MiB | 62.02 tokens/s |
非常に大規模な120Bモデルにおいても、95tokens/sを超える圧倒的な推論速度を記録しました。この結果は、GPT-OSSが以下3つの革新的技術を採用している点が寄与していると考えられます。
①Mixture-of-Expertsアーキテクチャの採用
②ネイティブ MXFP4量子化
③OpenAI Harmony レスポンスフォーマット
また、NVIDIA RTX PRO 6000 Blackwell GPUはFP4での推論に対応しており、AIワークロードに特化した効率的な演算能力が大きく寄与していると推察されます。従来世代のデータセンター向けGPU(A100/H100)と比較しても、格段の速度向上が見られました。
そのほか、A100やH100/H200などのベンチマーク結果一覧を下記フォームよりダウンロードいただけます。是非ご活用ください。
※検証は「ollama run」をオプションなしで実行した速報値です。
今後、コンシューマー向けGPUでのベンチマークも予定しています。
水冷ワークステーション
ローカル環境で大規模言語モデル(LLM)を運用する際、最も重要になるのが処理性能と安定性、そして静音性です。高性能GPUを活用したモデル推論やRAG処理は、CPU・GPUに大きな負荷をかけるため、発熱も相応に大きくなります。そこでおすすめするのが、水冷式のワークステーションです。
水冷システムは、空冷に比べて冷却効率が高く、かつ動作音も抑えられるのが特長です。静音性は特に重要で、たとえば50dBを超えるようなファンノイズが続くと、オフィスや研究室ではストレスの原因になりかねません。水冷なら、こうした音の問題を最小限にしつつ、24時間稼働にも耐えうる冷却性能を確保できます。
HPCシステムズでは、ご予算・計算規模に合わせて多彩なラインナップをご用意しております。 研究開発から実運用まで、目的に合わせた最適な一台をご提案いたします。
ローカルLLMを本格的に活用したいとお考えなら、ぜひ当社の水冷ワークステーションをご検討ください!
| 製品名 | CPU | 冷却方式 | 分類 | GPU対応・備考 |
|---|---|---|---|---|
 HPC2000-CRL104TS-D6 |
第13世代 Core-i9 | CPU簡易水冷 | エントリーワークステーション | 6000Ada GPU ×1まで対応 ※GPUは空冷となります |
 HPC5000-XER216TS-LC |
第5世代 Xeon スケーラブル ×2 | CPU/GPU 両水冷 | ハイエンドHPCワークステーション | 6000Ada GPU ×1まで対応 ※GPU搭載時はCPU-TDP制限あり |
 HPC3000-XSR116TS-LC |
第4世代 Xeon W-3400/3500 | CPU/GPU 両水冷 | AIワークステーション | 6000Ada GPU ×2まで対応 ※CPU-TDP制限あり |
 HPC3000-XSRGPU4TP-LC |
第4世代 Xeon W-3400/3500 | CPU/GPU 両水冷 | ハイエンドAIワークステーション | 6000Ada GPU ×4まで対応 |
NVIDIA Blackwell 対応製品
NVIDIA Blackwellシリーズを搭載したハードウェアなら、社内ネットワークだけで本格的なローカルLLM環境が手軽に構築できます。Blackwell GPUは大規模モデルの推論に最適化された高い演算性能と大容量メモリを備え、複数のモデルやRAG処理を同時並行で高速にこなします。HPCシステムズなら利用用途にあったBlackwell搭載製品をご提案可能です。ぜひお気軽にお問い合わせ下さい。
| NVIDIA RTX PRO 6000 | NVIDIA RTX 6000 Ada | NVIDIA L40S | NVIDIA H200NVL PCIe | |||||
|---|---|---|---|---|---|---|---|---|
| Blackwell Workstation Edition | Blackwell Max‑Q Workstation Edition | Blackwell Server Edition | ||||||
 |
 |
 |
 |
 |
 |
|||
| 冷却方法 | Active | Active | Passive | Active | Passive | Passive | ||
| 最大消費電力 | 600 W | 300 W | 400 W〜600 W | 300 W | 300 W | 600 W | ||
| 外形寸法 | 137.2 mm(高さ) x 304.8 mm(長さ) | 111.8 mm(高さ) x 266.7 mm(長さ) | 111.8 mm(高さ) x 266.7 mm(長さ) | 111.15mm(高さ) × 266.7mm(長さ) | 111.15mm(高さ) × 266.7mm(長さ) | 111.15mm(高さ) × 266.7mm(長さ) | ||
| スロットサイズ | 2スロット | 2スロット | 2スロット | 2スロット | 2スロット | 2スロット | ||
| HPC3000‑XSR108TS 100V |
ワークステーション |  |
お問い合わせ | 1 | ✕ | 1 | ✕ | ✕ |
| HPC3000‑XSR116TS 100V |
 |
1 ※Xeon w5‑3433 (16core 2.0GHz 220W) Xeon w5‑3423 (12core 2.1GHz 220W)のみ |
2 ※Xeon w5‑3433 (16core 2.0GHz 220W) Xeon w5‑3423 (12core 2.1GHz 220W)のみ |
✕ | 2 ※Xeon w5‑3433 (16core 2.0GHz 220W) Xeon w5‑3423 (12core 2.1GHz 220W)のみ |
✕ | ✕ | |
| HPC5000‑XERGPU4TS 100V/200V |
ワークステーション ※4Uラックマウント可能 |
 |
✕ | 4 ※3基以上は200V環境を推奨 |
お問い合わせ | 4 ※3基以上は200V環境を推奨 |
4 ※3基以上は200V環境を推奨 |
原則として搭載不可 ※過去搭載実績あり、要相談 |
| HPC5000‑XERGPU4R2S 200V |
2Uサーバー |  |
✕ | 3 |
お問い合わせ | 3 | 4 | 4 ※400Wまで/環境温度25度以下/CPU制限付 |
| HPC5000‑XERGPU10R5S 200V |
5Uサーバー |  |
✕ | 8 | お問い合わせ | 8 | 8 | 8 |
| HPC5000‑ETNGPU8R5S 200V |
 |
✕ | 8 | お問い合わせ | 8 | 8 | 8 | |
