
概要
先日、DGX-1を購入した記事を書きました。今回は、DGX-1を現在の他製品と比較したベンチマークを紹介します。
ハードウェア環境
今回は、DGX-1と、HPC5000-XBWGPU10R4Sに NVIDIA® V100-PCIE(16GB)、RTX2080Tiを搭載して、比較します。ハードウェア環境は下表のとおり。表で分かる通り、RTX2080TiとNVIDIA® V100PCIEは、4枚しか持っていません。
| 機種 | NVIDIA DGX-1 | HPC5000-XBWGPU10R4S |
| 搭載GPU | NVIDIA® V100-SXM2 | RTX2080Ti、NVIDIA® V100-PCIE |
|
搭載GPU数(最大搭載可能GPU数) |
8(8) | 4(10) |
| 搭載CPU |
Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz |
Intel(R) Xeon(R) CPU E5-2698 v3 @ 2.30GHz |
| 搭載CPU数 | 2 | 2 |
| 搭載メモリ容量 | 512 GB | 128GB |
今回使用したGPU、NVIDIA® V100-SXM2、NVIDIA® V100-PCIE、RTX2080Tiのスペックを下表に示します。
|
|
NVIDIA® V100-SXM2 |
NVIDIA® V100-PCIE |
RTX2080Ti |
|
GPUアーキテクチャ |
Volta |
Volta |
Turing |
|
GPUベース クロック |
1290 MHz |
1245 MHz |
1350 MHz |
|
GPU boost時 クロック |
1530 MHz |
1370 MHz |
1545 MHz |
|
CUDAコア |
5120 |
5120 |
4352 |
|
TensorCore |
640 |
640 |
544 |
|
メモリ仕様 |
HBM2 |
HBM2 |
GDDR6 |
|
メモリインターフェース |
4096 bit |
4096 bit |
352 bit |
|
メモリ帯域幅 |
900 GB/sec |
900 GB/sec |
616 GB/sec |
|
メモリ容量 |
32 GB |
16 GB |
11 GB |
|
最大消費電力 |
300 W |
250 W |
250 W |
|
倍精度理論性能 |
7.8 TFLOPS |
7.0 TFLOPS |
|
|
単精度理論性能 |
15.7 TFLOPS |
14.0 TFLOPS |
13.4 TFLOPS |
|
TensorCore理論性能 |
125 TFLOPS |
112.0 TFLOPS |
107.2 TFLOPS |
|
GPU間通信 |
NVLink |
P2P over PCIe Bridge | CPU Bridge |
|
GPU間通信帯域 |
25 GB/sec |
16 GB/sec |
8 GB/sec |
ソフトウェア環境
今回のベンチマークは、Nvidia GPU Cloud(以下、NGC)のDockerイメージのTensorflow上で、Nvidia提供の同梱プログラムnvidia-example/cnnなどで行いました。各モデルと精度に関して、なるべく大きなバッチサイズでベンチマークをしています。その時のバッチサイズは下表の通りです。(バッチサイズとパフォーマンスの関係についてはこちらを参考ください)
○ NVIDIA® V100 の バッチサイズ
|
|
inception-resnet-v2 |
inception-v3 |
inception-v4 |
resnet-101 |
resnet-152 |
|
fp32 |
64 |
128 |
64 |
100 |
64 |
|
fp16 |
128 |
256 |
128 |
200 |
128 |
○ RTX2080Ti の バッチサイズ
|
|
inception-resnet-v2 |
inception-v3 |
inception-v4 |
resnet-101 |
resnet-152 |
|
fp32 |
32 |
64 |
32 |
48 |
32 |
|
fp16 |
64 |
128 |
64 |
96 |
64 |
GPU単体性能比較
NVIDIA® V100 SXM2 と NVIDIA® V100 PCIe の性能差は、GPUクロックの差と同様で、数%~10%程度でした。GPUの単体としては、あまり差はありませんでした。NVIDIA® V100 と RTX2080Tiとの性能差は、半精度で1.6~1.7倍、単精度で1.3~1.4倍でした。
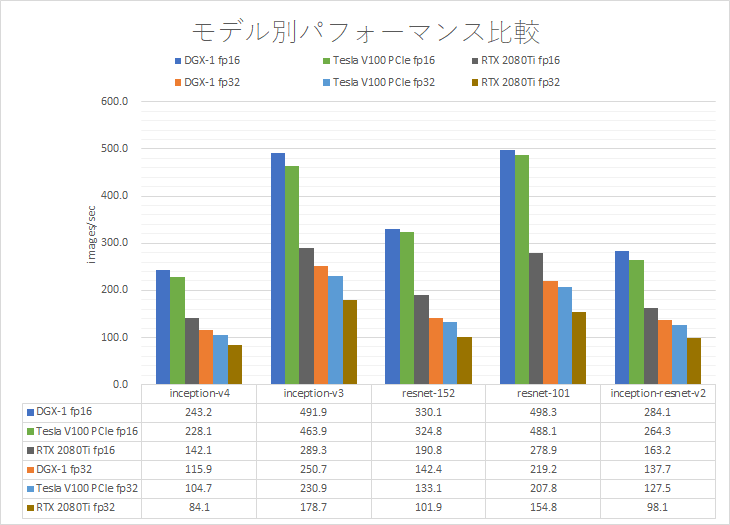
GPU間の帯域幅測定
DGX-1、NVIDIA®V100 PCIe、RTX2080Tiごとに、GPU間の帯域幅を測定しました。DGX-1はNVLinkの構成が不均一なため、NVLinkが1重、2重、非NVLinkで分けています。NVIDIA®V100はPCIeブリッジを通して通信します。現在、RTX2080Tiは、P2P通信ができないようで、CPUブリッジで通信します。(Geforce製品に関して、P2P通信のような機能は予告なく付加、排除される可能性があるとNVIDIAから伺っております。)
ここでグラフ中、NVLink1は1重のNVLink、NVLink2は2重のNVLinkで接続されているGPU間の帯域幅を示します。
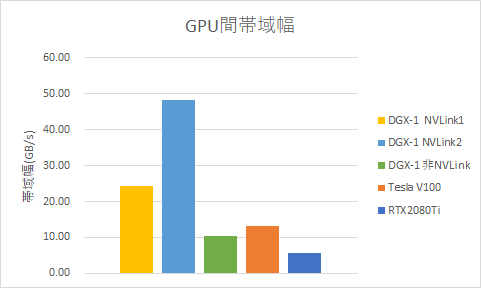
GPUを複数使用して動作させる時、NCCLというGPU並列のライブラリを使用します。NCCLはGPU間の通信網において、2つの独立したリング経路を選択し、その2つのリングの双方向、つまり、4方向に同時に通信を行います(バージョン2.3までは、この形式でしたが、2.4からは、2分木という経路選択方法になりました)。NCCLのベンチマーク、AllReduce時の帯域幅を下に示します。
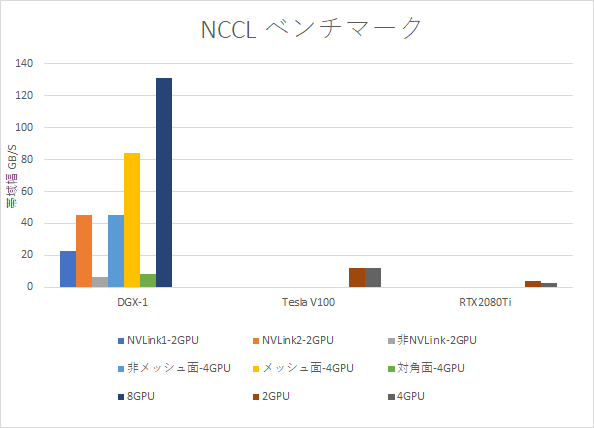
NVLink1、NVLink2の意味は、GPU間帯域幅の時と同様です。2GPUでは、帯域幅と同程度の速度となります。DGX-1は、GPU間の接続が不均一なので、4GPUの通信も、3パターンあります。DGX-1のGPU間接続は、CubeMeshと呼ばれ、立方体の頂点にGPUを配し、一部の対角線を結んだのがNVLinkの接続構成です。
4GPUの通信の場合、この立方体の、4つの頂点の選び方でパターンが分かれます。対角線を結んであるメッシュ面、対角線を結んでない非メッシュ面、立方体の面に属さない対角面の3パターンです。
メッシュ面(面0123、面4567)に関して、どのようにリングを配置するかは、不明ですが、すべてのGPUがNVLinkを通って通信できます。メッシュ面には、最低4本のNVLinkで接続されているGPUがあり、帯域幅も実測 83.9 GB/secと、NVLink4本分の帯域幅で通信しています。次に、非メッシュ面(例えば、面0154)は、1つのリングを双方向で通信するので、NVLink1本分×2で、実測45.5 GB/secの帯域幅で通信できます。さらに、対角面(例えば、面0167)は、必ずCPUを介して通信することになるので、2GPUを、非NVLinkで通信するのと同じ帯域幅となり、実測 8.2 GB/sec となりました。
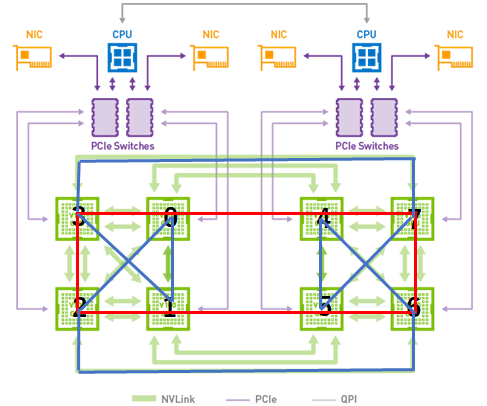
8GPUを使用する場合の経路は、上図の赤で記した、04765123 と、 青で記した、01375462 となります。このリングを双方向に、並列して通信することになります。赤は2重のNVLinkのリングのため、(NVLink2 + NVLink1)×2方向となり、NVLink 6本分の速度で、実測131 GB/sec の帯域幅となりました。
複数GPU並列ベンチマーク
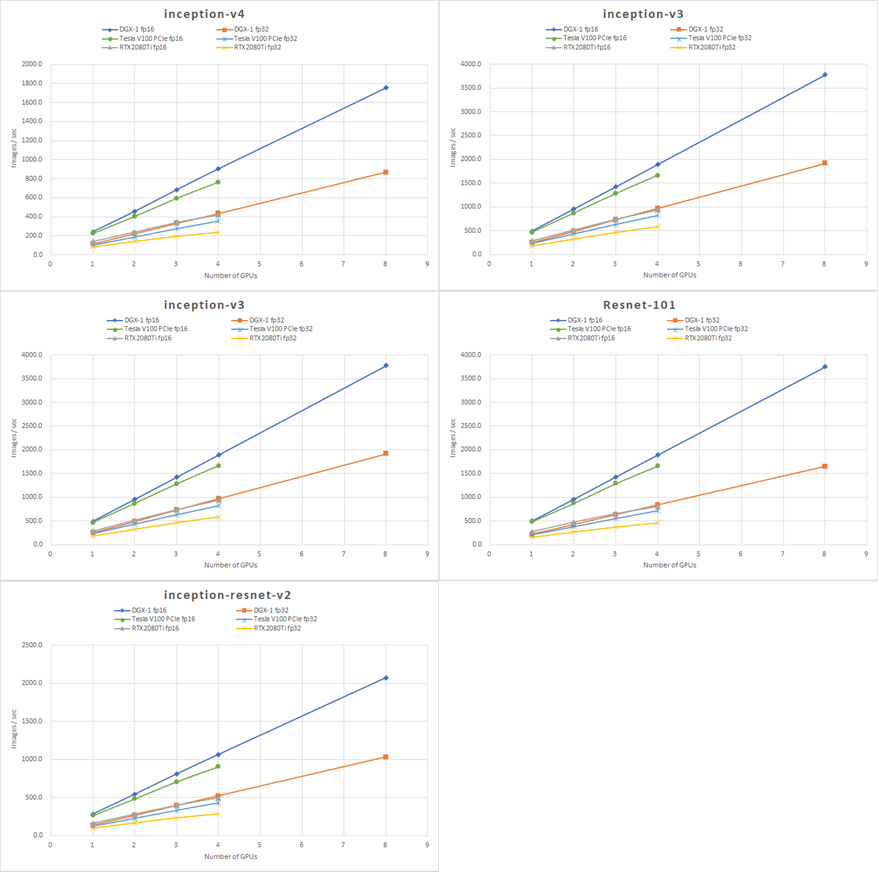
複数GPU(DGX-1は8個、他は4個)でベンチマークを行いました。GPU間の速度が、大きく影響する結果となりました。P2P通信ができないRTX2080Tiの伸びが見るからに悪く、DGX-1が4GPUまででも分かるくらいに、効率良く伸びていることが分かります。ちなみにDGX-1の4GPUは、メッシュ面(0123)を使用して実行しています。
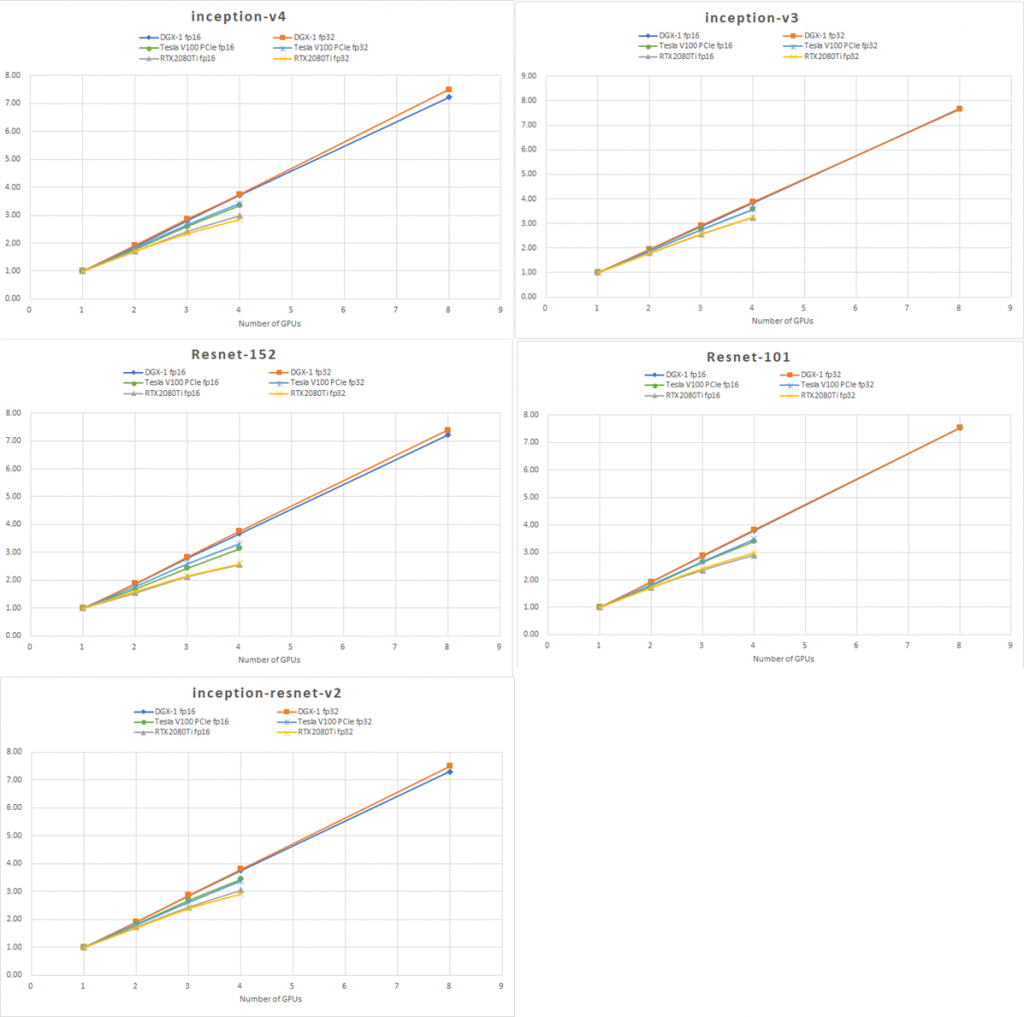
ベンチマーク結果を1GPU時の速度で正規化して、並列効率を見てみると、デバイス毎にグラフの傾きが分かれ、GPU間の通信速度が、並列効率に大きな影響を与えていることが分かります。
結論
DGX-1の並列性能を中心に検証しました。DGX-1は大規模なGPU並列で真価を発揮します。8GPUの並列計算において、90%以上の並列効率を有し、他の構成では達成することができないパフォーマンスを示しました。絶対性能を求めている方にお勧めします。

