US時間 4/2、日本時間 4/3 に第2世代 インテル® Xeon® スケーラブル プロセッサーがリリースされました。
今回導入された新しい機能の一つに、Vector Neural Network Instruction(VNNI) があります。
似たような位置づけの言葉として Intel® DL Boost がありますが、Intel® DL Boost は、インテルによる Deep Learning を加速する技術全体をあらわすマーケティング用語となっていて、執筆時点で該当するのは VNNI と bfloat16 です。
初代インテル® Xeon® スケーラブル プロセッサー(Skylake)までは、推論の畳み込み積和算において、VPMADDUBSW ⇒ VPMADDWD ⇒ VPADDD という3命令を順に実行する必要がありました。VNNI では、それと同じ結果を、1命令実行するだけで得られる、VPDPBUSD という命令が増えます。
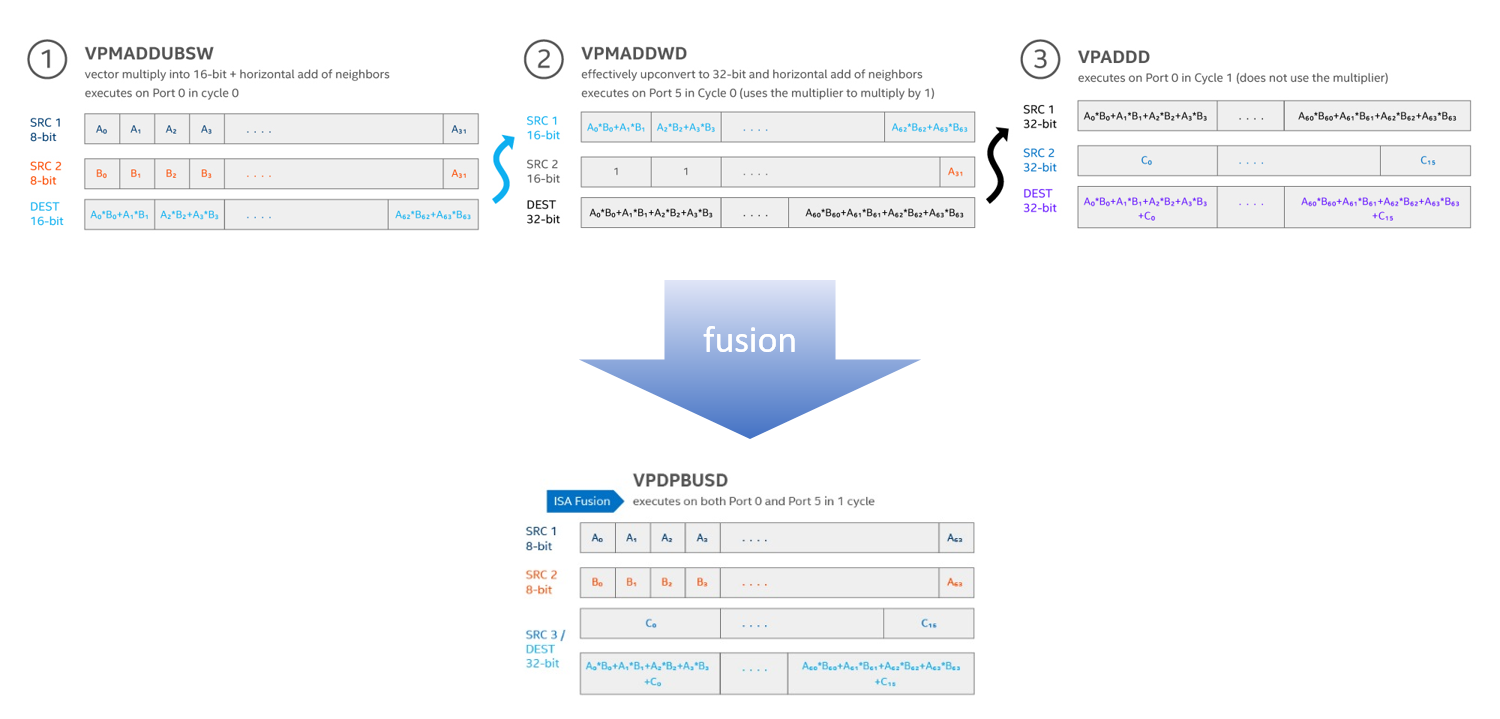
VNNI は CPUによって自動的には使われませんので、それを使うようアプリケーション側もしくは Deep Learning フレームワーク側が作りこまれている必要があります。VNNI について 2019年以内に(既に最適化済みを含め)最適化予定をうたっているのは TensorFlow、mxnet、Caffe、OpenVINO, MKL-DNN です。
なお、VPDPBUSD では扱う数値精度が int8 と低いので、この命令は学習には適しません。インテル公式記事(下記参考文献の2.) によると、次の世代の Xeon である Cooper Lake では bfloat16 に対応するとうたわれていますので、それになってようやくDeep Learning の学習計算を高速化できる話とされています。
参考文献:インテル公式ページ

