IcelakeはRHEL、CentOS や AlmaLinuxなど、RHEL8系からの対応という事で、RHEL8系へのOSの変更といった事例が増えています。RHEL8系ならではの様々な違いなどもありますが、困ってしまうのがpythonの扱いです。RHEL8系はOSの管理用のpythonとユーザー環境用のpythonが分れているなどの違いもありますが、python2のサポート終了に関係して、site-packageを入れたrpmパッケージが少ないなどもあり、OS付属のpython2.7を使用するのは如何なものか、というのが実際のところです。
いやいや、python3を使えばいいじゃないというのが世の通り相場なのですが、HPCアプリの場合、そう簡単に切り変えられる訳ではありません。なぜかというと、HPCアプリ、特に信頼があるとされているHPCアプリの場合、アップデートの頻度が低いからです。これはまあ、当たり前の話で、開発初期ならいざ知らず、HPCアプリの場合、アップデートが頻繁にあるという事はバグも豊富にある、すなわち、折角、計算した結果が正しいかどうか疑わしい、という話になります。そうなってしまうと、そのアプリを利用して書いた論文なども間違いだったという話になりかねない訳でして、こうした問題がある為に、HPCアプリの開発は結構、入念に行なわれているので、アップデート頻度はどうしてもその手間の分、間隔が空きがちになります。
世間的にはアップデートが頻繁なものはアクティブで良いとされがちですが、HPC分野の場合、出来が悪くてfixが多発、そんな物ぁ信頼出来ないよ、という見方も一面の真実だったりします。
アップデートの間隔が大きく、リリース前のチェックも手間となってしまうと、結構な割合で、アプリの中のutilityスクリプトなどで使われているpythonも2系統だったりするのです。
また、HPC分野の場合、研究の継続性というものも重要なので、いつも最新のバージョンを使用するとは限りません。以前の論文の続きであれば、そこで使用していたバージョンも使用して、最新のバージョンとの差異もチェックするなどといった目的で、少し前のバージョンも動作してくれないと困る、といったご要望も耳にします。
そういった訳で、例えRHEL8系になっていようが、python2のサポートが終了しようが、python2で書かれたスクリプトが動かないと困るといった事が発生するので、その対応を行なう必要があるのですが、OSの側のパッケージが期待出来ないというのであれば、ローカル環境にビルドしてしまえ、という割と力技な解決策もあったりします。
そこで、python2.7.18をビルドして、必要なsite-packagesをとなった時、HPC分野であれば、numpyは忘れてはいけないでしょう。numpyはBLASを使用しますから、ここで使用されるBLASの影響をついでに見ておこうというのが、今回の内容です。
pipでインストールされるpython2のnumpyは、OpenBLAS版が多いようです。そこで、OpenBLASの代りにCPU最適化したBLASを使うようにビルドして、その影響を見てみます。
試験に使用したのは、https://software.intel.com/content/www/us/en/develop/articles/numpyscipy-with-intel-mkl.html のインテルが作成したものです。このうちのAppendix.Bのスクリプトを使用しました。倍精度の浮動小数点計算を使用しています。試験環境はCentOS 8.3、python2.7.18、numpy 1.16.6、scipy 1.2.3で、CPUはCascade Lake Xeonを使用しました。
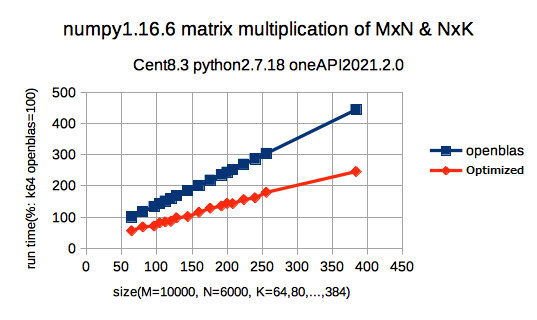
行列乗算の実行時間のグラフで、OpenBLAS版のM=10000, N=6000, k=64の実行時間を100として、相対値で標記してあります。実行時間のグラフなので、低いほど高性能という事になります。倍くらい性能が違いますね。
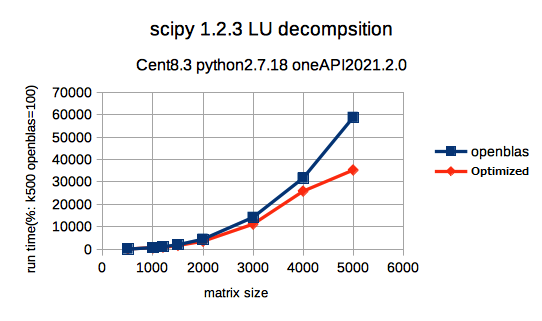
LU分解をscipyを使用して実行した結果です。scipyはnumpyを使用して新たにビルドしてあります。これもOpenBLAS版のk=500の実行時間を100として相対値で記載しています。matrix sizeが小さいうちは、誤差程度しか違いませんが、サイズが大きい時、K=5000の時で、CPU最適化版は、OpenBLAS版の6割程度の時間で計算終了しています。
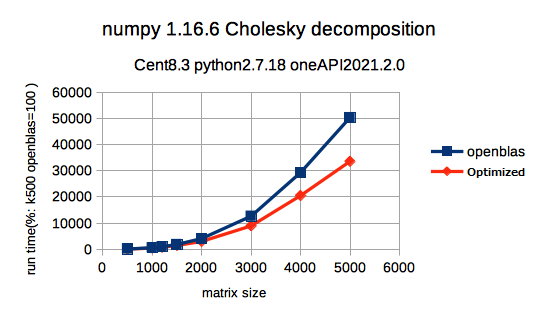
コレスキー分解をnumpyで実行した結果です。OpenBLAS版のk=500の実行時間を100として相対値で記載しています。こちらもmatrix sizeが大きくなると差が広がり、k=5000では、7割弱の計算時間で、CPU最適化版は計算終了しています。
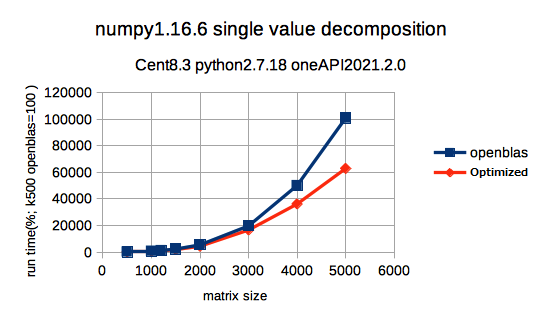
特異値分解をnumpyを使用して実行した結果です。OpenBLAS版のk=500の実行時間を100として相対値で記載しています。こちらも同様で、K=5000ではCPU最適化版は6割程度の実行時間で終了しています。
numpyのベンチは、結構、公表されているのですが、割と、無理して使うほどじゃない、という結果が多い印象はあります。じゃあ、この差はなんだ、というと、サイズの違いでしょうか。実行時間の為もあって、matrix sizeをこれくらい大きくしたものって、結構、少なかったりします。実際に、このテストするの、か〜なり時間がかかりましたからね。
事実、pythonでnumpyを使う場合、ちょちょっとした行列計算に便利だからという利用は多いので、スクリプトでそんな巨大な行列、扱わないよ、そうした場合、CなりFortranなりでプログラム書くからね、という事になりがちなので、そういう目的であれば、小さ目のサイズで比較した結果から、無理してCPU最適化版を使わないというのも、それはそれで正しいと思います。
とまあ、そういった事もあって、敢えてnumpyにCPU最適化を使用した場合の比較などをやってこなかったのですが、最近は少し事情も変ってきてるようです。というのは、pythonのスクリプトで、かなりヘヴィな処理をさせる場合、多いみたいなんですね。
HPC分野の場合、MDなどを行なっている分野では、結構、pythonスクリプトでヘヴィな処理を行なう場合が増えているようです。
一番、多いのは機械学習の分野でしょうか。こちらの分野の場合、HPC分野とは異なって、pythonのみで全て行なうといった漢気溢れる方も多いようです。まったく同じ処理を何度もするのではなく、少しづつ変化させてといった場合が多いでしょうから、スクリプトで可能ならその方が良い場合は、多分、多いのでしょうね。
そういった場合、プレやポストの処理で、numpyを多用して、巨大なデータマトリックスを処理という場合も多いようで、実際、社内でこのデータを見せたところ、HPC分野の人は、ふ〜ん、といった程度だったのですが、機械学習分野の人は、なにぃ!これは凄いといった喰い付きで、見せた私がドン引きしたくらいです。
今回の図のように、サイズが大きくなればなるほど、実行時間に大きな差が出ますから、その差は大きいのでしょう。まあ、その場合は、python3を使用するのですが。
因みにですが、python3でもほぼ同じ結果となります。BLAS依存ですから、BLASが同じなら結果も同じですね。
もっとも、この公開されているスクリプトはpython2仕様なので、python3で使う場合、print文や除算などで修正が必要です。sixでは吸収してくれないんですよね、この違い。プログラム言語にも、さすてぃなびりてぃは必要だと思うの。
思わぬところで、python2のスクリプトを動かす為にはsixや2_to_3では不足している事を実感するハメになり、ローカル環境のpython 2.7.18も、場合によってはお役に立てるかなと思っています。
このRHEL8で動かすCPU最適化版 numpyの入ったpython2.7.18のローカル環境が必要な場合、弊社営業にお問い合わせ下さい。対応致します。
あの〜、python2でも3でもいいのですが、EPYCなので、という場合は、
…、頑張れ!
