HPC
HPC AMDの新GPU Instinct™ MI300シリーズについて
AMDのAI 向け新GPU製品 Instinct MI300X および Instinct MI300Aの詳細が発表されました。 ネットでは取り上げられなかった 情報も交えて紹介いたします。
■Instinct MI300Xについて
図1 AMD Instinct MI300X 及び MI300A
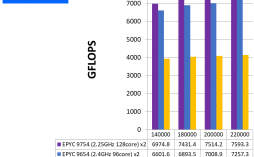
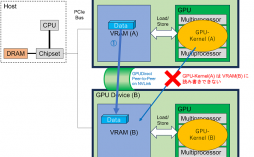
AMD InstinctMT MI300X は NVIDIA の H100 を凌駕するデータセンタ用の高性能 GPU です。すでに1月のCESの前日基調講演や6月の「Data Center and AI Technology Premiere」で発表されていましたが、今回サンノゼで開催さ...
2023.12.14

HPCDL