
はじめに
2025年になり、CPU側のシステムメモリとGPU側のVRAMを統合したメモリ空間を利用できるサーバーがNVIDIA社から次々とリリースされています。GPUからシステム側のメモリに透過的にアクセスできるようにすることで、利用できるメモリ量を増やそうという取り組みは、LLM(大規模言語モデル)の高性能化に伴い、動作に要求されるメモリサイズも肥大化している課題への一つの解決策として注目されています。
一方、HPC(高性能計算)分野においても、この統合メモリ環境の導入は大きなパラダイムシフトを引き起こすと期待しています。これまで科学計算では、GPUだけでほぼすべての演算を完結できる手法は限られていました。多くの場合、目的に応じてCPUとGPUを使い分けるような処理が必要でしたが、CPU-GPU間のデータ通信がボトルネックとなり、柔軟に使い分けて性能を引き出すのは難しい状況でした。統合メモリ環境の導入により、CPUとGPUを目的に応じて使い分けるような計算プログラムが使える領域が広がるでしょう。
本記事ではまず、NVIDIA社の統合メモリ環境についてGH200を元に紹介した後、実際に統合メモリをどうやって使うのかをFortranを利用して解説します。実は統合メモリ環境を採用することによって、GPUを利用したプログラムの実装がこれまでよりも簡単になります。これを機に新たにGPUプログラミングに挑戦してみてはどうでしょうか?
GH200の統合メモリ環境
NVIDIA社のGH200は、統合メモリ環境を実現するためのNVLinkC2Cが最初に導入されたサーバーです。
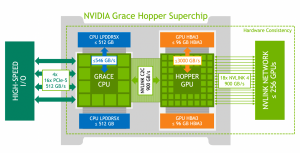
上記が、GH200の概略図です。GH200には、上図の右側部分にあたる、外だしのNVLinkNetworkでノード間をつなぐことで、別のノード上にあるGPUのメモリ空間まで統合・連結させるExtended GPU Memoryという機能も用意されていますが、こちらの説明は本記事では割愛します。1台のサーバー内でシステムメモリとVRAMがどのように統合されるかにのみ紹介します。
概略図にある通り、GH200は統合メモリ環境と謳っていますが、CPU側のシステムメモリとGPU側のVRAMは物理的に分かれています。そのため、nvidia-smi等を利用してGPUメモリ容量を確認すると、GPU側のVRAM容量である96GBしか表示されません。NVIDIAの統合メモリ環境の肝はCPU-GPU間を新たな規格であるNVLink C2Cで接続している点です。NVLink C2Cは900GB/sという、PCIe Gen5の約7倍程度の高帯域を実現しているだけではなく、新たにキャッシュコヒーレントなアドレス空間をハードウェアレベルで実現する仕組み(ATS: Address Translation Services)も実装しています。ATS機能により、CPUとGPUのスレッドからCPU/GPUどちらのメモリに対しても同時かつ透過的にアクセスすることを可能にします。
新たなUnified Memory機能を有効化する
しかしながら、上記の統合メモリ環境は、「何もしなくても」自動的にシステムメモリをGPUが参照してくれるわけではありません。具体的に言うと、nvccやnvfortranを使ってプログラムをコンパイルする際、mem:unified オプションを有効にする必要があります。上記オプションをつけずにコンパイルした場合、透過的なメモリアクセスはおこなわれず、GPU側がアクセスできるメモリは96GBのVRAMのみになります。
mem:unifiedオプションはGH200によって新たに導入されたものではなく、2023年頃にCUDAに導入された Heterogeneous Memory Management(HMM)機能によって追加されたものです。ソフトウェアレベルでの対応が先に行われてunified memoryを使うためのコーディング方法が整備された後に、ハードウェアレベル(ATS)で対応したGH200が登場した、という順序になります。
そのため、mem:unifiedオプションは、下記条件を整えることで従来のGPUサーバーでも有効にすることができます。
- CUDA 12.2以上、NVIDIAのオープンソース版ドライバ r535_00 以上
- Linuxカーネル 6.1.24+、6.2.11+、もしくは 6.3+
- Turing、Ampere、Ada Lovelace、Hopper、Blackwell 世代のGPU
詳細については、NVIDIA社のHMM紹介記事をご確認ください。特筆事項として、オープンソース版のGPUドライバが必要となる点に注意してください。弊社ではこれまでプロプライエタリ版(非オープンソース)のドライバを採用していました。しかし昨今、NVIDIA社はGPUドライバのオープンソース化を進めており、Blackwell世代のGPUからはオープンソース版ドライバのみがサポートされるようになりました。これを受けて、弊社でもBlackwell世代のGPUのリリース以降、オープンソース版ドライバへ切り替えています。今後、Blackwell GPUを搭載しUbuntu 24.04 OSをインストールしたサーバーから順次、HMM機能が有効化された状態で納品いたします。
ATSとHMMという2つの用語が出てきて混乱しやすいかもしれませんが、次のようにイメージすると理解しやすいと思います。
・HMM:
ソフトウェアレベルでシステムメモリとGPUメモリのアドレス空間を統一して扱う仕組み。条件が整えば通常の GPU搭載サーバーでも使用可能で、必ずしもGrace Hopperのような統合メモリ環境を必要としません。
・ ATS:
HMMが提供する機能をハードウェアレベルでもサポートする機能。Grace Hopper等の統合メモリ環境を搭載し たサーバーが必要です。
HMM・ATSがシステム的に有効になっているかは、次のコマンドで確認できます。
nvidia-smi --query | grep "Addressing Mode"
HMMまたはATSと返ってくれば、これから説明するUnified Memoryを利用することができます。
FortranでUnified Memoryを使う
ここからは、これまでのGPUプログラミングがmem:unifiedオプションを有効にすることでどのように変わるのかをFortranをベースに説明します。FortranからGPUを利用する代表的な方法は下記4つです。
- OpenACC
- OpenMP for GPU
- do concurrent
- CUDA Fortran
CUDAを利用したコーディングは、NVIDIA GPUの性能を最大限に引き出せますが、元のプログラムから大幅に改変する必要があり、学習コストが高く保守性が低いという難点があります。そのため、はじめはOpenACCを利用することがお奨めです。元コードにディレクティブ(指示文)を追加するだけで動作し、場合によってはCUDAに匹敵する性能が得られることが報告されています。Fortran準拠のdo concurrentはディレクティブの追記もせずにコンパイル時のオプション変更のみでGPU化できる点が魅力ですが、利用可能な範囲が狭く、現時点ではあまり推奨できません。
OpenACCでは、これまではCPU-GPU間のデータ転送をユーザーが明示的に指示する必要がありました。「CPU側の変数Aの値をGPU側の変数Aにコピーする」「GPU側の変数AをCPU側の変数Aに戻す」といったデータ指示文を適切に追加することで、CPU-GPU間のデータ通信を制御します。コンパイル時にmem:separatedオプションをつけて動作させるため、以降ではseparetedモードと呼ぶことにします。
一方で、mem:unifiedオプションを有効にすることでもOpenACCは動作します。(以下では「unifiedモード」と呼ぶことにします。) 。このモードに変更すると、CPU側に確保されたデータをGPUから直接読み書きできるようになるため、データ転送のための指示文を書かずに動作させることができます。HMMとATSどちらが有効になっているかで内部的な挙動は異なりますが、コーディングしている際に両者の違いを意識する事はあまりありません。
unifiedモードでCPU/GPUどちらにデータが置かれるかは、基本的にコンパイラとランタイム任せになります。
GPU側からのアクセスが多いと判断した場合は、CPUからGPUへメモリコピーするなどの操作が自動で挿入されます。
簡単なコードで挙動確認
では実際に、1〜100000までを足し合わせた結果を出す簡単なコードで挙動を確認します。
本来であれば、データ移動に関する指示文を書かないコードを使って、unifiedモード にすれば正常に動作し、separated モードだとエラーが発生するという挙動を期待していました。しかし、最近のコンパイラはある程度自動で判断して必要な copy 指示を挿入するため、簡単なプログラムでは特に指示文を書かなくても動作してしまいます。そこで挙動の違いを明確に示す目的で、下記のようなコードで比較しました。
program test
implicit none
integer,parameter:: n = 100000
double precision:: a(n)
double precision:: sua
integer i
do i = 1,n
a(i) = dble(i)
enddo
sua = 0.d0
!$acc data present(a) !この行がなくても意図した通りに動くのがunified memoryの特徴
!$acc kernels
!$acc loop independent reduction(+:sua)
do i = 1,n
sua = sua + a(i)
enddo
!$acc end kernels
!$acc end data !この行がなくても意図した通りに動くのがunified memoryの特徴
write(*,*)sua
end program
データ指示文のpresent(a)は、今回の動作検証のために導入した指示文で、CPUからGPUへのコピーをさせないために追加しました。
上記のプログラムを下記のように、コンパイルオプションを変えて実行してみます。
#unified memoryモード
nvfortran -fast -acc -gpu=cc86,mem:unified:nomanagedalloc -Minfo=accel test_acc.F90
#separatedモード
nvfortran -fast -acc -gpu=cc86,mem:separate -Minfo=accel test_acc.F90
unifiedモードでコンパイルする際に nomanagedalloc というオプションを追加しています。これは、単に unified を指定しただけでは一部の環境で managed メモリとして動作する場合があるため、完全に managed メモリとして動作する挙動を排除する目的で追加しています。
また、cc86 は今回の検証で使用した GPUのcompute capability を指定したものです。実際の値は使用する GPU によって変わるため、実行環境に合わせて設定してください。
コンパイル時に出力される情報は、両モードとも概ね同じ内容が出力されました。sua 変数については copy 指示文が自動で挿入されましたが、変数 a は present 指定しているため、CPU–GPU 間でデータコピーが行われた旨のログは出力されていません。
11, Generating present(a(:))
12, Generating implicit copy(sua) [if not already present]
14, Loop is parallelizable
Generating NVIDIA GPU code
14, !$acc loop gang, vector(128) ! blockidx%x threadidx%x
Generating reduction(+:sua)
作成したプログラムをunifiedモードで実行すると、 GPU がホスト側のメモリに直接アクセスできるため、CPU側に置かれたデータを参照して計算が正常終了します。これに対し separated モードでは、GPU にデータを参照しに行きますが、CPUからGPUへのデータコピーをしていないため、GPU側にデータが存在せず異常終了します。
今回は検証のために present 構文を追加した状況で実行しましたが、data指示文を削除してもunifiedモードであれば正常に動作します。
さいごに
今回の例は簡単なコードのため「それだけか」と感じるかもしれませんが、プログラムが複雑になるほど ユーザーが明示的にデータ転送を指示するのは困難です。unifiedモードであればデータ転送を意識せずにコーディングできるため、これまでよりも簡単にGPUを利用できるようになります。
GH200 等の統合メモリ環境であれば、unifiedモードのままでも実運用できるケースがでてくるでしょう。また、依然としてデータ転送を明記した最適化が必要な場合でも、ボトルネックの部分だけ明記することで速度向上が見込めるかもしれません。
統合メモリ環境によって、かつては CPU–GPU 間の通信がボトルネックとなって諦めていた手法が実用レベルにまで引き上げられる可能性があります。研究者にとって新しい武器になることを期待しています。
