GPGPUはホットな分野でlammpsも07Sep09よりGPGPU対応ライブラリーとモジュールが含まれました。 GPGPUは使う予定は無いという方へのGPGPUに対応したlammpsでのGPGPUの波及効果の情報です。
GPGPU対応は大きく2つあります。1つはCUDAを利用してGPGPUを使う形にソースを移植する場合、もう1つはGPGPUを使用出来るモジュールやライブラリを作り、GPGPUも」使えるようにソース全体を整頓する場合です。 lammpsの場合は後者で、GPGPUを使える環境の場合GPGPUを使えるようにソースを整理しました。
lammps 07Sep09以降のようなGPGPUも使えるように整備するという事はどういった事でしょう。 極めて大雑把に言えば、可能な限り浮動小数点計算は避けて、固定小数点計算を行なうという事です。GPGPUは結局、ベクトルプロセッサを上手く活用するという手法なので、固定小数点計算は整数演算に移行出来るので、ベクトルプロセッサで高速に計算が可能になるという仕組です(実際は、もっと複雑ですが)。
実は、こうしたソースの整備は、GPGPUを使わない場合でも、大きな効果があるのです。
それはSSEが上手く活用し易くなるという事です。SSEも細部は異りますが、ベクトルプロセッサなので、intelなどのコンパイラは、浮動小数点計算も頑張ってSSEを使えるようにバイナリを作るのですが、やはり可能なかぎり排除したソースと、とりあえず倍精度浮動小数点にしておけば計算誤差の問題は安全だろう、というソースではコンパイラの効率化にも限度があります。逆に言えば、GPGPUに対応するようにソースを整備した場合、SSEが本来の性能を発揮出来る場合がある、という事です。
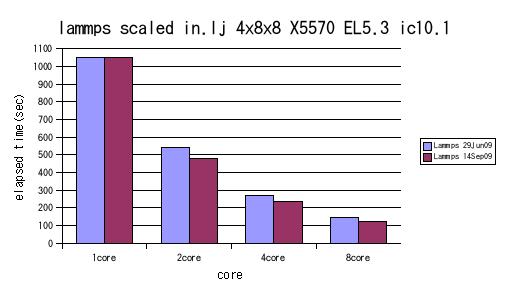
これはlammpsのGPGPU非対応の29Ju09とGPGPU対応の14Sep09をSSE3を使用するコンパイラオプションでビルドして、in.lj.scaledをx=4, y=8, z=8でベンチマークを行なった結果です。パッとみてもかなり高速になった事がお分かりだと思います。
非常に興味深いのが1coreと2coreの比較です。グラフでは分り難いかもしれないので具体的な数値を上げてみると
| lammps ver | 1core | 2core |
| lammps 29Jun09 | 1050.00 sec | 540.00 sec |
| lammps 14Sep09 | 1051.62 sec | 480.00 sec |
なんと、2並列計算の場合シリアルの倍以上に高速化しています。
同じような事は地上最速のMD計算を目指すというgromacs 4系でmdrunをSSE用にソースツリーに含まれているアセンブリコードを使用してビルドした場合も、2並列にした場合、インプットデータによってはシリアルの倍以上、速度が上がります。
これはSSEを上手く活用する事で、計算自体が速くなる事に加えて並列した場合、計算に必要なデータが半分になる為、キャッシュのヒット率が上がったりメモリ上のデータをCPUに転送する量が減った事で、CPUのデータ入力待ちが減った為と推定されます。
GPGPU非対応時代のlammpsでも、2並列で倍になっているのも並列計算プログラムをご利用されている方には驚きかとも思いますが、lammpsは計算効率を上げる為、CPUのデータ待ちを避ける目的でメモリ上からCPUに転送されるデータがGZIPで圧縮されているので、CPUのデータ待ち時間が少いからなのですがこれに加えて、GPGPUモジュールを使えるようにソースを整備した為、同じ計算精度でも、SSEを十分に活用でき、まるでアセンブラでSSE対応コードを書いたgromacs 4のような高速化が実現しています。
GPGPUはいま現在、使う予定は無い、という場合でもlammpsのようにGPGPUがホットになった為に、波及効果がありますので、ちょっと情報を調べてみたり、ソースを書く場合、気を付けてみると意外な効果があるかもしれません。