





ローカルLLMスターターセット
ローカルLLM・RAG開発に最適なGPU環境を最短で構築機密性の高いデータを用いて生成AIを活用
【2025/8/12 更新】
OpenAIから発表された新しいオープンソースモデル「gpt-oss」の技術検証を実施しました。
gpt-oss 検証結果速報
| モデルサイズ | VRAM要件 | context length | embedding length | quantization | 推論速度 |
|---|---|---|---|---|---|
| 120B | 80GB | 131,072 | 2,880 | MXFP4 | 35~40 Token/s (A100 x8) |
| 20B | 15GB | 131,072 | 2,880 | MXFP4 | 67 Token/s (A100 x1) 102 Token/s (H100 x1) |
NVIDIAの最新GPU、RTX PRO 6000 Blackwell Max-Qを使用した際のGPT-OSSモデルの推論速度ベンチマーク結果です。
| GPU | モデルサイズ | 消費電力 / TDP | メモリ使用量 / 総容量 | 推論速度 |
|---|---|---|---|---|
| RTX PRO 6000 Blackwell Max-Q Workstation Edition 1基 | 120B | 272W / 300W | 64,657MiB / 97,887MiB | 95.70 tokens/s |
| 20B | 281W / 300W | 15,613MiB / 97,887MiB | 131.42 tokens/s | |
| NVIDIA H100 Tensor Core GPU 1基 | 120B | 213W / 350W | 64,556MiB / 81,559MiB | 62.02 tokens/s |
①Mixture-of-Expertsアーキテクチャの採用
②ネイティブ MXFP4量子化
③OpenAI Harmony レスポンスフォーマット
また、NVIDIA RTX PRO 6000 Blackwell GPUはFP4での推論に対応しており、AIワークロードに特化した効率的な演算能力が大きく寄与していると推察されます。従来世代のデータセンター向けGPU(A100/H100)と比較しても、格段の速度向上が見られました。
そのほか、A100やH100/H200などのベンチマーク結果一覧を下記フォームよりダウンロードいただけます。是非ご活用ください。
※検証は「ollama run」をオプションなしで実行した速報値です。
今後、コンシューマー向けGPUでのベンチマークも予定しています。
大規模言語モデル(LLM)とRAG (Retrieval-Augmented Generation)とは
大規模言語モデル(LLM)は、膨大な量のテキストデータを学習することで、人間の言語を理解し生成する能力を持ったAIモデルです。
文脈を把握して自然な文章を生成することが可能で、質問応答、文章の自動要約、翻訳、創作文章の生成など、さまざまな言語処理タスクを実行できます。
この技術によって、チャットボット、検索エンジン、推薦システム、自然言語インターフェースなど、多岐にわたる分野で活用され、業務の自動化や顧客対応の効率化に役立つと期待されています。また、専門分野に特化したカスタムモデルを構築することで、特定の業界や用途に最適化された応用が可能です。
また、LLMは大量のパラメータを持つため、効率的な計算資源(GPUサーバーなど)の活用が求められます。適切なハードウェアと最適化手法を組み合わせることで、実用レベルでの高速な応答や大規模な処理が実現されています。
しかしながら、LLMは膨大なデータから言語パターンを学習する一方で、「ハルシネーション」と呼ばれる、事実に反する情報や誤った応答を生成するリスクがあります。これは、学習データの偏りや情報の更新遅れ、あるいは単純にモデルの生成アルゴリズムの特性によるものです。
RAG(Retrieval-Augmented Generation)とは?
こうした正確性の懸念に対処するための有力なアプローチとして、RAG(Retrieval-Augmented Generation)という技術があります。 RAG(Retrieval-Augmented Generation)とは、大規模言語モデル(LLM)に外部の知識を組み合わせて回答を生成する技術です。ユーザーの質問に対して、まず関連する情報を事前に用意したドキュメントなどから検索(Retrieval)し、その情報をもとに自然な文章で回答を生成(Generation)します。これにより、モデルの事前学習に含まれない最新情報や社内特有のナレッジを活用した、より正確で信頼性の高い応答が可能になります。ローカル環境でLLMを構築するメリット
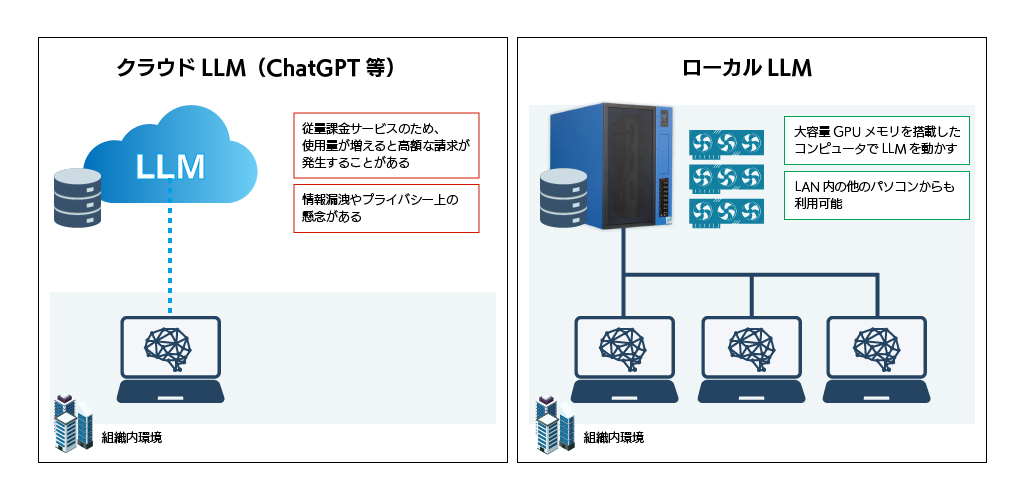
ローカル環境とは、システムやアプリケーションを自社内のサーバーやネットワーク上で構築・運用する環境です。これにより、セキュリティやプライバシーの管理が安全になり、外部依存を避けられる利点があります。さらに、高いカスタマイズ性により自社のニーズに合わせた最適な構成を選ぶことができ、特別な用途向けの高度な処理が可能になります。
ローカル環境でLLMとRAGを組み合わせたシステムを構築することで、機密性の高いデータや社内情報が外部に流出するリスクを抑え、安心して運用できます。全てのデータが社内に留まるため、情報漏洩対策も徹底可能です。
また、社内の業務内容や特定のニーズに合わせたチューニングやドメイン特化の知識の組み込みが容易です。RAGを活用することで、最新データや社内特有の情報を元に正確な回答が提供できます。
ローカルLLMスターターセットとは
初期設定はHPCシステムズのエンジニアが行っており、LLM/RAG開発に適したハードウェア&ソフトウェア一式がプリインストールされているため、最短で取り組みを始めることが出来ます。
クラウドを使わず、社内の文書やデータを活用してRAG(Retrieval-Augmented Generation)を実装することで、機密性の高い情報を安全に扱えるLLM環境構築をご支援いたします。
構築例
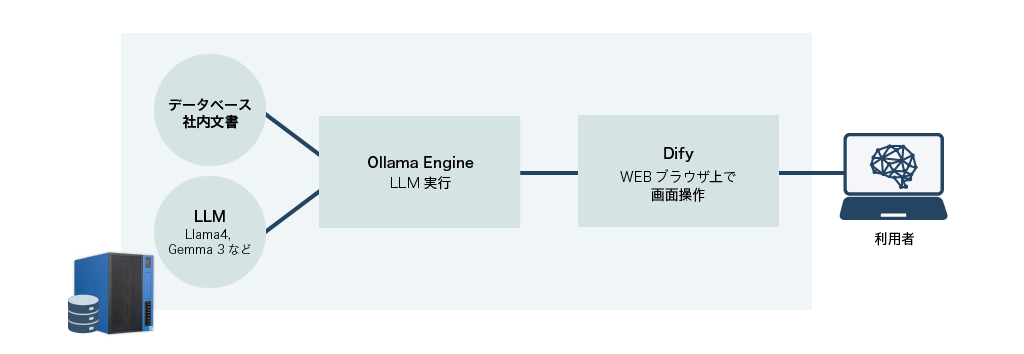
Ollamaとは
大規模言語モデル(LLM)をローカル環境で実行できるオープンソースのツール。これにより、クラウドに依存せず、自分のコンピュータ上で直接LLMを利用できるようになります。Difyとは
初心者から上級者まで誰でも簡単にチャットボットやAIアプリケーションを開発できる、オープンソースのLLMアプリ開発プラットフォーム。直感的な操作性で、変更内容をリアルタイムで確認しながら開発を進められます。
安心・スピーディにローカルLLMを導入できる3つの特長
セキュアなローカル環境
- 機微情報をはじめとした社内データをローカル環境内に留め、セキュリティリスクを最小化
短期間で導入可能
- LLM/RAG開発に適したハードウェア&ソフトウェア一式をプリインストール
導入前後も手厚くサポート
- 予算・用途に応じて最適な性能をご提案
- 3年間のセンドバック保守付帯
- オプションとしてオンサイト保守 / ストレージ返却不要サービスあり
- ※伴走支援サービスをご希望の方は、「neoAI Chat for オンプレミス」をご検討ください
GPUワークステーションラインナップ
| モデル | HPC2000-CARL104TS | HPC3000-XSR116TS | HPC3000-XSRGPU4TP-LC | HPC5000-XERGPU4TS | |||
|---|---|---|---|---|---|---|---|

 NVIDIA Geforce RTX 5090 ×1
NVIDIA Geforce RTX 5090 ×1
|
 NVIDIA RTX PRO 6000 ×1
NVIDIA RTX PRO 6000 ×1
|

 NVIDIA RTX PRO 6000 Max-Q ×1
NVIDIA RTX PRO 6000 Max-Q ×1
|
NVIDIA RTX PRO 6000 Max-Q×2
|

 NVIDIA RTX L40S ×4
NVIDIA RTX L40S ×4
|
 NVIDIA RTX PRO 6000 Max-Q ×2
NVIDIA RTX PRO 6000 Max-Q ×2
|
NVIDIA RTX PRO 6000 Max-Q ×4
|
|
| ENTRY① | ENTRY② | MID-RANGE① | MID-RANGE② | HIGH-END① | HIGH-END② | HIGH-END③ | |
| 最大LLMパラメーター数 (FP4使用時) |
50B | 153B | 153B | 307B | 307B | 614B | 614B |
| 冷却方式 | 空冷 | 空冷 | CPU/GPU両水冷 | 空冷 | |||
| 搭載可能GPU | NVIDIA RTX GPU ×1 | NVIDIA RTX Pro 6000 Max-Q (96GB) x2 | 水冷NVIDIA L40S ×4 | NVIDIA RTX Pro 6000 Max-Q (96GB ×2 | |||
| CPU | インテル Core Ultra プロセッサー ×1 | インテル Xeon W-3400/3500(最大60コア) ×1 | 水冷インテル Xeon W-3400/3500(最大56コア) ×1 | インテル Xeon スケーラブルプロセッサー (最大64コア) ×2 | |||
| メモリ | 64GB | 128GB | 128GB | 256GB | 256GB | 256GB | 512GB |
| ストレージ | 960GB M.2 NVMe SSD ×2 (System, Backup) 1.92TB 2.5インチ NVMe SSD ×1 (Data) |
960GB M.2 NVMe SSD ×2 (System, Backup) 3.84TB 2.5インチ NVMe SSD ×1 (Data) |
1TB M.2 NVMe SSD ×2 (System, Backup) 4TB M.2 NVMe SSD ×1 (Data) |
960GB 2.5インチ NVMe SSD ×2 (System, Backup) 3.84TB 2.5インチ NVMe SSD ×1 (Data) |
|||
| 必要電源 | 100V15A×1回路 | 100V15A×1回路 | 100V15A×2回路 | 100V/15A×2回路 | 200V/20A または 30A×1回路 | ||
| 参考価格 |
NVIDIA Geforce RTX 5090 (32GB・575W) ×1基構成
1,600,000円 (税込 1,760,000円) |
NVIDIA RTX PRO 6000 (96GB・600W) ×1基構成
2,600,000円 (税込 2,860,000円) |
NVIDIA RTX PRO 6000 Max-Q (96GB・300W) ×1基構成
3,000,000円 (税込 3,300,000円) |
NVIDIA RTX PRO 6000 Max-Q (96GB・300W) ×2基構成
4,900,000円 (税込 5,390,000円) |
NVIDIA RTX L40S(48GB) ×4基構成
8,400,000円 (税込 9,240,000円) |
NVIDIA RTX PRO 6000 Max-Q (96GB・300W) ×2基構成
5,400,000円 (税込 5,940,000円) |
NVIDIA RTX PRO 6000 Max-Q (96GB・300W) ×4基構成
9,100,000円 (税込 10,010,000円) |
| 生成AIモデル ※25年12月時点 |
gpt-oss:20b(16GB / OpenAI) gemma3:27b(17GB / Google) mistral-small3.1:24b(15GB / Mistral-AI) |
gpt-oss:20b(16GB / OpenAI) gpt-oss:120b(80GB / OpenAI) llama4:scout(67GB / Meta) gemma3:27b(17GB / Google) mistral-small3.1:24b(15GB / Mistral-AI) |
gpt-oss:20b(16GB / OpenAI) gpt-oss:120b(80GB / OpenAI) llama4:scout(67GB / Meta) gemma3:27b(17GB / Google) mistral-small3.1:24b(15GB / Mistral-AI) |
gpt-oss:20b(16GB / OpenAI) gpt-oss:120b(80GB / OpenAI) llama4:scout(67GB / Meta) llama4:maverick(245GB / Meta) gemma3:27b(17GB / Google) mistral-small3.1:24b(15GB / Mistral-AI) |
|||
| Embeddingモデル ※25年5月時点 |
nomic-embed-text:v1.5 (274MB / Nomic) |
||||||
| 備考 |
|
||||||
NVIDIA RTX Pro 6000 Blackwell Series
税抜 1,500,000 円
(税込 1,650,000円)
ローカルLLMの活用例
研究支援
専門分野のリサーチリスト作成や文献要約を自動化。関連論文の探索でも言語モデルが類似キーワードを判断し、テーマに関連する論文を幅広く探索。
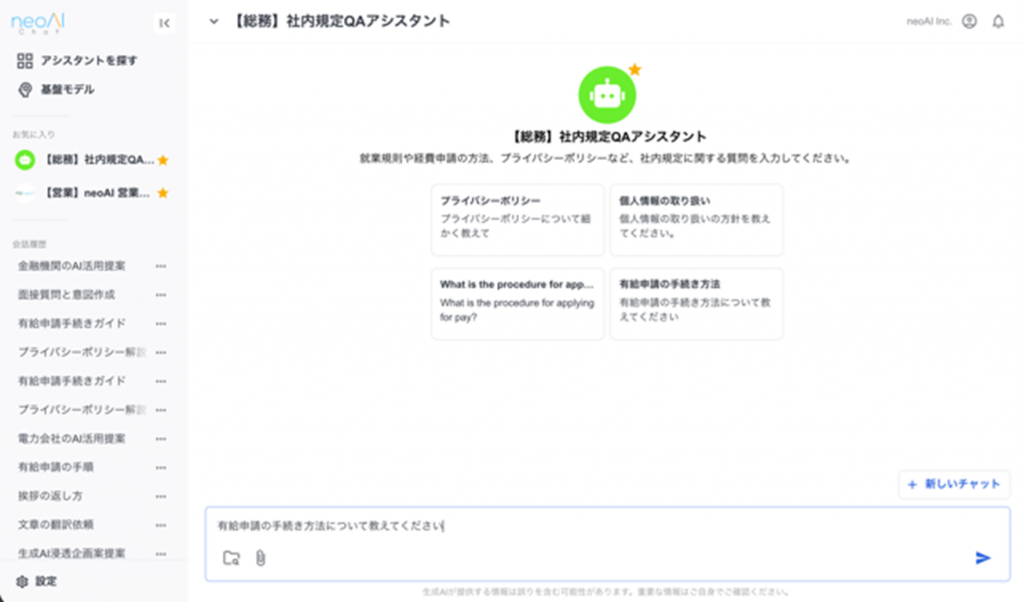
社内問い合わせ対応
社内文書を読み込ませることで、就業規則や社内ルールについても正確な回答を自動作成。問い合わせに対する対応コストの削減を実現。
製品開発支援
設計仕様書やテストケースの生成、顧客フィードバック分析を自動化し、開発サイクルを短縮。
AIチャット活用までのご支援が必要なお客様へ!
オンプレミスAIチャット導入ソリューション+伴走支援が付帯 「neoAI Chat for オンプレミス」サービスのご案内
neoAIが提供する高精度な生成AIシステム「neoAI Chat for オンプレミス」と「オフィス設置可能な静音AIサ ―バ/水冷ワークステーション」とでAI活用をご支援するサービスを開始しました。これにより、「サーバの設置に適した場所がない」「機密情報を外部に送信できない」「AI導入の専門家がいない」といった理由でAI導入をためらっていた企業でも、大規模言語モデル(LLM)および検索拡張生成(RAG)技術を利用した生成AIシステムを手軽に導入・運用することが可能になります。
HPCシステムズの AI / DeepLearning ソリューション
お問い合わせ
平日9:30~17:30 (土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)