
NVIDIA DGX Series
NVIDIA A100上に構築された世界初のAIシステム 販売終了製品:NVIDIA DGX A100

8基のNVIDIA A100 TensorコアGPUにより5 PFLOPS のAI演算性能を発揮します。GPU用メモリは帯域幅12.4TB/秒、合計容量320GBを備えています。
NVIDIA DGX ™ A100は、すべてのAIワークロードに対応するユニバーサルシステムであり、世界初の5ペタフロップスAIシステムでこれまでにない計算密度、パフォーマンス、柔軟性を提供します。また、世界で最も先進的なアクセラレータであるNVIDIA A100 Tensor Core GPUを備えており、企業はトレーニング、推論、分析を統合して、NVIDIA AIエキスパートへの直接アクセスを含む、統合が容易な導入AIインフラストラクチャに統合できます。
 製品概要
製品概要
■ NEWS
「NVIDIA DGX A100」に、このNVIDIA A100 80GBを搭載した「NVIDIA DGX A100 640GB System」も発表されました。
従来のDGX A100をご利用のお客様にはGPUボードのアップグレードサービスも提供される予定です。

NVIDIA DGX A100 製品概要

すべてのAIワークロードに対応するユニバーサルシステム
NVIDIA DGX A100は、分析からトレーニング、推論まで、すべてのAIインフラストラクチャのユニバーサルシステムです。コンピューティング密度の新たな基準を設定し、5ペタフロップスのAIパフォーマンスを6Uフォームファクターにパッキングし、従来のインフラストラクチャサイロをすべてのAIワークロード用の1つのプラットフォームに置き換えます。
DGXperts:AI専門知識への統合アクセス
DGXpertsは、規範的なガイダンスと設計の専門知識を提供するAIに精通した施術者が、AIの変革を加速させています。彼らは過去10年間に豊富な経験を積み、DGXへの投資の価値を最大化する14,000人以上のAIに堪能なプロフェッショナルのグローバルチームです。
重要なアプリケーションを迅速に立ち上げて実行し、稼働を維持できるようにし、スムーズに洞察までの時間を飛躍的に向上させます。

最速での解決
NVIDIA DGX A100は、NVIDIA A100 TensorコアGPU上に構築された世界初のAIシステムです。8つのA100 GPUを統合するこのシステムは、これまでにない加速を提供し、NVIDIA CUDA-X ™ソフトウェアとエンドツーエンドのNVIDIAデータセンターソリューションスタック向けに完全に最適化されています。
比類のないデータセンターのスケーラビリティ
DGXシステムの中で最速のI/Oアーキテクチャを備えています。
NVIDIA DGX A100は、毎秒450ギガバイト(GB / s)のピーク双方向帯域幅を備えたMellanox ConnectX-6 VPI HDR InfiniBand / Ethernetネットワークアダプターを備えています。これは、DGX A100 をスケーラブルAIインフラストラクチャのエンタープライズブループリントであるNVIDIA DGX SuperPOD ™などの大規模AIクラスターの基盤となる多くの機能の1つです。大規模な最先端のネットワーキング・ハードウェアでGPUアクセラレーションされたコンピュートソフトウェアの最適化により、何千ものノードを使用してAIと大規模画像分類します。
NVIDIA A100 TensorコアGPU
NVIDIA A100 TensorコアGPUは、AI、データ分析、高性能コンピューティング(HPC)にこれまでにない加速を提供し、世界で最も困難なコンピューティングの課題に取り組みます。
また、パフォーマンスを大幅に向上させる第3世代NVIDIA Tensorコアにより、数千まで効率的に拡張できます。
第3世代TensorCore:
DLやHPCのデータ形式に十分な取り扱いサポートを持ちつつ、Sparsity(データ中のゼロの多さ)を意識した機能を備えたことで、V100を超えるスループットを実現(理想的にはV100の2倍のスループット)。
DLの学習が進むと、学習された出力を決定するのに意味のある重みは一部(約半分)となって、残りは不要(重み値がゼロ)になります。
そこでゼロでないデータの番地をインデックス化し、意味のある部分だけ計算してしまえば、学習結果を変えずに無用な計算を省いて高速化できます。

■ NVIDIA GTC 2020
A100のTensorCoreに搭載された新しいTensorFloat-32[TF32]
3:35頃で説明されている、FP32(単精度浮動小数点数)の入出力データをDLフレームワークやHPCで扱う際に、その取扱い処理 を加速する簡単な方法。TensorCore内部で、FP32に比べて13ビット少ないビット数でFP32の範囲をFP16の精度で表現し、入力をFP32で受けて取りまとめをFP32で行う。
コード変更の必要なしに使えて、学習計算を高速化できる。V100のFP32積和演算に比べて10倍以上、ゼロが多いデータの場合は20倍以上高速化する。
FP16/FP32の混合精度のDLの場合では、A100 TensorCoreはV100の2.5倍性能、ゼロが多いデータの場合は5倍性能を実現する。
A100のTensorCoreに搭載された新しいBfloat16[BF16]/FP32混合精度演算
FP16/FP32の混合精度演算と同じ流量で実行できる。DL推論におけるINT8、INT4、2値丸めについてTensorCoreは高速化し、V100のINT8に比べてA100のゼロの多い場合のINT8は20倍以上高速化する。HPCについては、新しいIEEE準拠のFP64処理にTensorCoreは対応していて、V100のFP64性能の2.5倍を実現する。
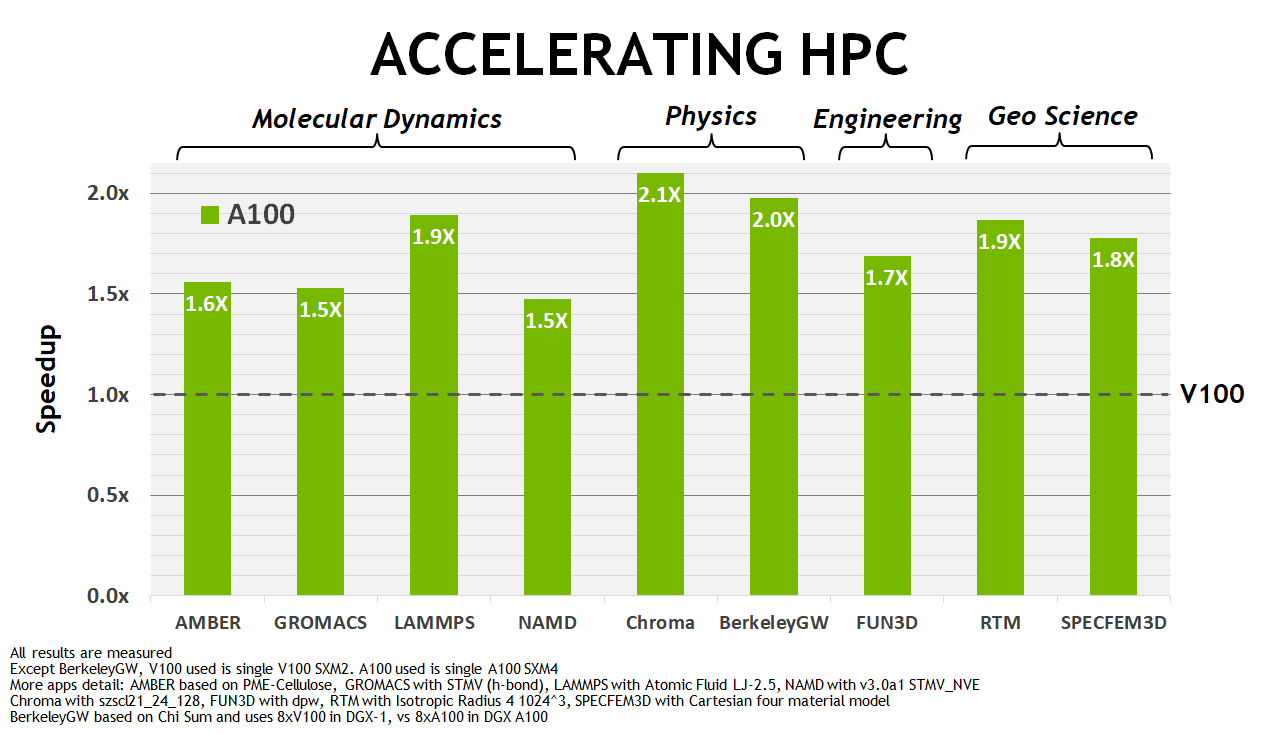
V100とA100の学習・推論性能ベンチ結果

V100とA100のHPC計算ベンチ結果
ホワイトペーパーダウンロード
NVIDIA DGX A100紹介動画
 主な特長
主な特長

-
科学技術計算、クラウドグラフィックス、データ分析用に構築された、最新 Ampere 世代 NVIDIA A100 GPU を搭載。A100 GPU は 540 億を超えるトランジスタを 7nm 製造プロセスで実装。 TensorFloat32 に対応し、さらに Sparse データに最適化された新たな第 3 世代 TensorCore と、容量 40GB で 1.6TB/s もの高帯域な HBM2 メモリを備え、PetaOPS 級の理論性能を誇ります。
merit 1
-
DGX A100® にはシステムボード上に 8 つの NVIDIA A100 GPU を搭載し、それらを第3世代NVLink と NVSwitch により 600GB/s の帯域で結合。 9 枚の Mellanox ConnectX-6 200Gbps カードで高スケーラビリティを実現します。ソフトウェアスタックに Spark 3.0、RAPIDS、TensorFlow、PyTorch、Triton を構成し、5PFLOPS を 1 台で実現する統合 AI システムです。
merit 2
-
NVIDIA 技術によって加速される Spark 3.0 を搭載。 GPUDirect ストレージ、GPU と GPU メモリを意識したSparkスケジューラ、GPU最適化されたSpark SQLアクセラレータを備えます。Spark3.0 を使ってデータセンタースケールのデータ処理(学習・推論)をハイスループットに実行します。
merit 3
-
NVIDIA A100 GPU により Deep Learning の劇的な加速が期待されます。 さらに、Multi-InstanceGPU(MIG)機能によって GPU サーバーのマルチテナント運用における集約率向上に貢献します。
merit 4
 システム解説
システム解説

- 8X NVIDIA A100 GPU、合計320 GBのGPUメモリ、12 NVLinks / GPU、600 GB / s GPU-to-GPU双方向帯域幅
- 6X NVIDIA NVSWITCHES 4.8 TB / s双方向帯域幅、前世代のNVSwitchの2倍
- 9x MELLANOX CONNECTX-6 200Gb / Sネットワークインターフェイス 450 GB / sピーク双方向帯域幅
- デュアル64コアAMD CPU 秒と1つのTBシステムメモリの消費電力のほとんど集中AIジョブズへ3.2倍以上のコア
- 15 TB GEN4 NVME SSD 25 GB /秒のピーク帯域幅、Gen3 NVME SSDより2倍高速
 仕様・スペック
仕様・スペック
DGX A100
| SYSTEM | NVIDIA DGX A100 640GB |
|---|---|
| GPUs | 8x NVIDIA A100 80 GB GPUs |
| 演算性能 [Tensor演算性能] | 5 petaFLOPS AI 10 petaOPS INT8 |
| GPU メモリ | 640 GB total |
| NVIDIA NVSwitches | 6 |
| System Power Usage | 6500W |
| CPU | Dual AMD Rome 7742, 128 cores total, 2.25 GHz (base), 3.4 GHz (max boost) |
| システムメモリ | 2 TB |
| ネットワーク | 8x SinglePort Mellanox ConnectX-6 VPI 200Gb/s HDR InfiniBand 2x Dual-Port Mellanox ConnectX-6 VPI 10/25/50/100/200 Gb/s Ethernet |
| 内蔵ストレージ | OS: 2x 1.92 TB M.2 NVME drives Internal Storage: 30 TB (3.84 TB x 8) U.2 NVMe drives |
| 内蔵ストレージ最大容量 | 30 TB (3.84 TB x 8) |
| ソフトウェア | Ubuntu Linux OS |
| システム重量 | 123.16 kg |
| 梱包重量 | 163.16kg |
| システムサイズ | 全高: 264.0mm 全幅: 482.3mm 奥行: 897.1mm |
| 運用温度 | 5℃ - 30℃ |
DGX-A100-tensor-コアGPU-GA100
| Data Center GPU | NVIDIA A100 |
|---|---|
| GPU Codename | GA100 |
| GPU Architecture | NVIDIA Ampere |
| GPU Board Form Factor | SXM4 |
| SMs | 108 |
| TPCs | 54 |
| FP32 Cores / SM | 64 |
| FP32 Cores / GPU | 6912 |
| FP64 Cores / SM | 32 |
| FP64 Cores / GPU | 3456 |
| INT32 Cores / SM | 64 |
| INT32 Cores / GPU | 6912 |
| Tensor Cores / GPU | 432 |
| GPU Boost Clock | 1410 MHz |
| Peak FP16 Tensor TFLOPS with FP16 Accumulate | 312/624 |
| Peak FP16 Tensor TFLOPS with FP32 Accumulate | 312/624 |
| Peak BF16 Tensor TFLOPS with FP32 Accumulate | 312/624 |
| Peak TF32 Tensor TFLOPS | 156/312 |
| Peak FP64 Tensor TFLOPS | 19.5 |
| Peak INT8 Tensor TOPS | 624/1248 |
| Peak INT4 Tensor TOPS | 1248/2496 |
| Peak FP16 TFLOPS | 78 |
| Peak BF16 TFLOPS | 39 |
| Peak FP32 TFLOPS | 19.5 |
| Peak FP64 TFLOPS | 9.7 |
| Peak INT32 TOPS | 19.5 |
| Texture Units | 432 |
| Memory Interface | 5120-bit HBM2 |
| Memory Size | 40 GB |
| Memory Data Rate | 1215 MHz DDR |
| Memory Bandwidth | 1.6 TB/sec |
| L2 Cache Size | 40960 KB |
| Shared Memory Size / SM | Configurable up to 164 KB |
| Register File Size / SM | 256 KB |
| Register File Size / GPU | 27648 KB |
| TDP | 400 Watts |
| Transistors | 54.2 billion |
| GPU Die Size | 826 mm2 |
| TSMC Manufacturing Process | 7 nm N7 |
NVIDIA Partner Network(NPN)に認定されました
HPCシステムズは、NVIDIA社のパートナー認定制度 “NVIDIA Partner Network (NPN)” において、「DGX AI Compute System」 「Networking」 「Compute」 の3つのコンピテンシーで最上位レベルのELITE PARTNER に認定されています。
HPC システムズは、Solution Provider と Solutions Integration Partner の二つのパートナーカテゴリーをカバーする製品知識と、長年培ってきた高度な HPC-AI システムインテグレーション技術を掛け合わせることで、お客様の研究・開発の加速化、効率化に対する最適解を提供してまいります。
※ NVIDIA パートナー ネットワーク (NPN) は、NVIDIA が展開するパートナープログラムです。 2024年7月現在、日本国内の企業が約80社加入しています。 NVIDIA パートナー ネットワーク (NPN) は、13種類のパートナーのタイプと、11種類のコンピテンシーで構成されています。
ご参考: NVIDIA パートナー ネットワーク (NPN)
お問い合わせ
お客様に最適な製品をご提案いたします。まずはお気軽にお問い合わせください。
03-5446-5531
平日9:00~18:00(土・日・祝日は除きます)
※土曜日、日曜日、祝日、年末年始は、休日とさせていただきます。