
NVIDIA DGX Series
AI インフラストラクチャの金字塔。 NVIDIA DGX H100

世界最先端のエンタープライズ向け AI インフラストラクチャ
NVIDIA H100 GPU x8、合計 GPU メモリ 640GB
GPU あたり 18 NVIDIA® NVLinks®、GPU 間の双方向帯域幅 900GB/秒
NVIDIA NVSWITCHES™ x4
7.2 テラバイト/秒の GPU 間双方向帯域幅 、前世代比 1.5 倍以上
NVIDIA CONNECTX®-7 x8 および、NVIDIA BLUEFIELD® DPU 400Gb/秒 ネットワーク インターフェイスx2
ピーク時の双方向ネットワーク帯域幅 1TB/秒
デュアル x86 CPU と 2TB システム メモリ
AI への依存が非常に高い仕事を可能にするパワフルな CPU
30TB NVMe SSD
最高のパフォーマンスを実現するための高速ストレージ
NVIDIA DGX H100を受注開始。
2023.07.05 HPCシステムズ、NVIDIA DGX H100を株式会社フジクラへ納入、フジクラの多彩なAI技術開発の更なる加速化に寄与[詳細を見る]
 製品概要
製品概要
NVIDIA DGX H100システムは、大規模言語モデル、レコメンダー システム、ヘルスケア研究および気候科学に必要とされる、膨大な演算性能要件に対応できるスケールを備えています。1 台のシステムには8 基の NVIDIA H100 GPU が搭載され、これらの GPU が NVIDIA NVLink® で 1 つに接続されています。NVIDIA DGX H100 システムは1台あたり、新しい FP8 精度で前世代の 6 倍以上となる、32 ペタフロップスの AI 性能を発揮します。
NVIDIA DGX H100 システムは、次世代の NVIDIA DGX Base POD™ および NVIDIA DGX SuperPOD™ AI インフラストラクチャ プラットフォームの構成要素となっています。最新の DGX SuperPOD アーキテクチャには、合計 256 基の H100 GPU を搭載する最大 32 のノードを接続する、新しい NVIDIA NVLink Switch Systemが実装されています。
FP8 で 1 エクサフロップスと前世代の 6 倍以上の AI 性能を発揮する、次世代の DGX SuperPOD は、数兆のパラメータを持つ膨大な LLM ワークロードを処理できる能力によって、AI の地平を切り開きます。
 主な特長
主な特長
NVIDIA H100 TensorコアGPU
NVIDIA H100 Tensor コア GPU では、あらゆるワークロードのための前例のないパフォーマンス、スケーラビリティ、およびセキュリティを利用できます。NVIDIA® NVLink® Switch システムにより、最大 256 基の H100 を接続して、エクサスケール ワークロードを加速することができ、兆単位のパラメーター言語モデルを解くための専用の Transformer Engine も備えています。H100 の複合的な技術革新により、大規模な言語モデルを前世代の 30 倍という驚異的なスピードで高速化し、業界をリードする対話型 AI を提供することができます。

画期的なテクノロジ
最新の TSMC 4N プロセスを利用し、800 億個以上のトランジスタで作られた Hopper は、NVIDIA H100 Tensor コア GPU の中核をなす 5 つの画期的なイノベーションを持ち、それにより世界最大の言語生成モデルである NVIDIA の Megatron 530B チャットボットの AI 推論で、前世代と比較して 30 倍という驚異的なスピードアップを実現します。
Transformer Engine
NVIDIA Hopper アーキテクチャは、AI モデルのトレーニングを高速化するように設計された Transformer Engine との組み合わせで Tensor コア テクノロジを前進させます。Hopper Tensor コアでは FP8 と FP16 の精度を混在させることができます。トランスフォーマーの AI 計算が劇的に速くなります。Hopper はまた、TF32、FP64、FP16、INT8 の精度の浮動小数点演算 (FLOPS) を前世代の 3 倍にします。Transformer Engine と第 4 世代 NVIDIA® NVLink® と組み合わせることで Hopper Tensor コアは HPC と AI のワークロードを桁違いに高速化します。
NVLink と NVSwitch
現代のビジネス環境において、エクサスケール HPC(High-Performance Computing)や兆を超えるパラメーター数を持つAIモデルなど、非常に要求の高い計算タスクに対応するために、高速でスケーラブルなコンピューティングプラットフォームが不可欠です。これを実現するには、GPU間の効率的な通信が不可欠であり、そのために高度な相互接続技術が必要です。
DGX-H100は、第4世代のNVLinkテクノロジを採用しており、これによりレーンあたり100Gbps、ポートあたり200Gbpsの高速なpoint-to-point接続方式を提供しています。各NVIDIA H100 GPUに対して18ポートのNVLinkを搭載することで、各GPUの合計帯域幅は900ギガバイト/秒(GB/s)に達します。この性能は、PCIe Gen5の帯域幅の7倍以上に相当します。また、DGX-H100は第3世代のNVSwitchも搭載しており、これは複数のNVLink接続をスイッチする技術です。これによりマルチキャストを含む任意のGPU間でのノンブロッキング通信を非常に効率的に行えます。
さらに、NVSwitchは、In-network Computingとして知られる、これまでにInfiniBandでしか実現できなかった技術であるSHARP(Scalable Hierarchical Aggregation and Reduction Protocol)をサポートしています。これにより、NVSwitchは高速な通信を行いつつ、内部に組み込まれた演算ユニットを使用して、リダクション処理などの計算を同時に実行できます。これにより、データ伝送量を削減し、高速な計算を実現することが可能となります。

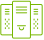
NVIDIA コンフィデンシャル コンピューティング
データはストレージに保存されているときと、ネットワーク間を転送されるときは暗号化されますが、処理中は保護が解除されます。この保護のない時間に対処するのが NVIDIA コンフィデンシャル コンピューティングです。使用中のデータとアプリケーションを保護します。NVIDIA Hopper アーキテクチャは、コンフィデンシャル コンピューティング機能を持った世界初のアクセラレーテッド コンピューティング プラットフォームを導入するものです。
ハードウェアベースの強力なセキュリティを持ち、ユーザーはオンプレミス、クラウド、エッジでアプリケーションを実行できます。許可のないエンティティは使用中のアプリケーション コードやデータを表示することも、変更することもできません。データとアプリケーションの機密性と完全性が守られ、AI トレーニング、AI 推論、HPC ワークロードのかつてない高速化を利用できます。
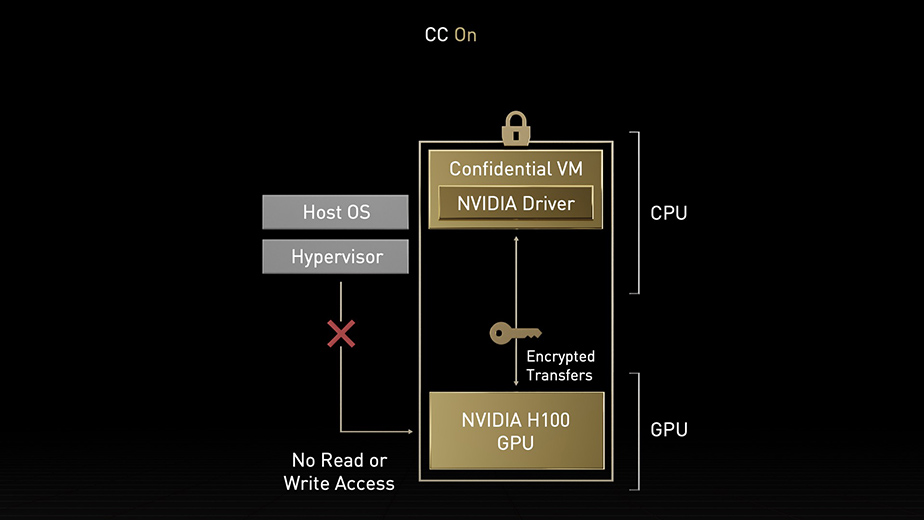
第 2 世代 MIG
マルチインスタンス GPU (MIG) という機能では GPU を、完全に分離された複数の小さなインスタンスに分割できます。それぞれにメモリ、キャッシュ、コンピューティング コアが与えられます。Hopper アーキテクチャは MIG の機能をさらに強化するものです。最大 7 個の GPU インスタンスで仮想環境のマルチテナント/マルチユーザー構成をサポートします。コンフィデンシャル コンピューティングによってハードウェアおよびハイパーバイザー レベルで各インスタンスが分離されるため、安全です。MIG インスタンスごとに専用のビデオ デコーダーが与えられ、共有インフラストラクチャで安定したハイスループットのインテリジェント ビデオ解析 (IVA) が実現します。そして、Hopper の同時実行 MIG プロファイリングを利用すると、管理者はユーザーのために正しいサイズの GPU 高速化を監視し、リソース割り当てを最適化できます。
研究者のワークロードが比較的少ない場合、完全な CSP インスタンスを借りる代わりに、MIG を利用して GPU の一部を安全に分離することを選択できます。保存中、移動中、処理中のデータが安全なため、安心です。
DPX 命令
動的プログラミングは、複雑な再帰的問題を単純な小問題に分割して解決するアルゴリズム手法です。小問題の結果を格納しておけば、後で再計算する必要がありません。幾何級数的問題の解決にかかる時間が短縮され、その複雑性が緩和されます。動的プログラミングは幅広い使用例で一般的に使用されています。たとえば、Floyd-Warshall は、出荷車両と配送車両のための最短経路を地図に表示する経路最適化アルゴリズムです。Smith-Waterman アルゴリズムは DNA 配列とタンパク質フォールディングの応用に使用されます。
Hopper では DPX 命令で動的プログラミング アルゴリズムを加速します。CPU と比較して 40 倍、NVIDIA Ampere アーキテクチャ GPU と比較して 7 倍の速さです。結果的に、病気の診断、リアルタイムの経路最適化、さらにはグラフ分析を劇的に速くします。

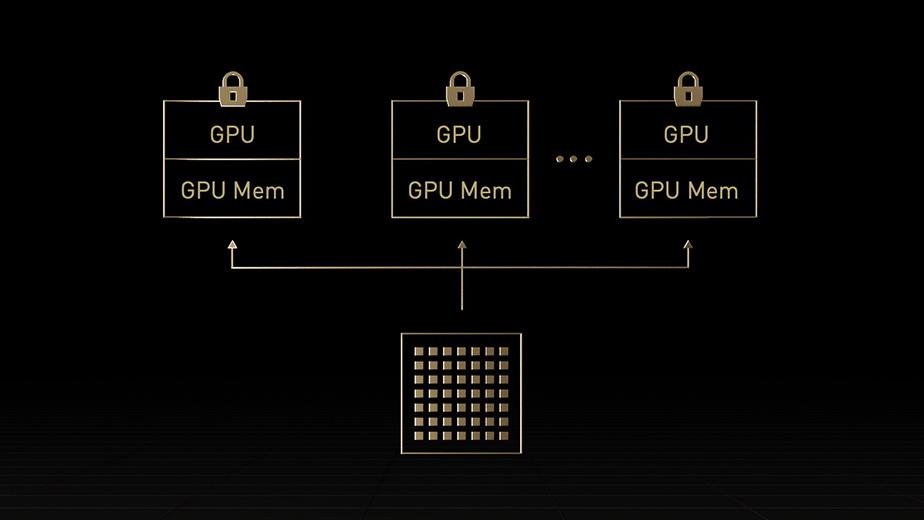
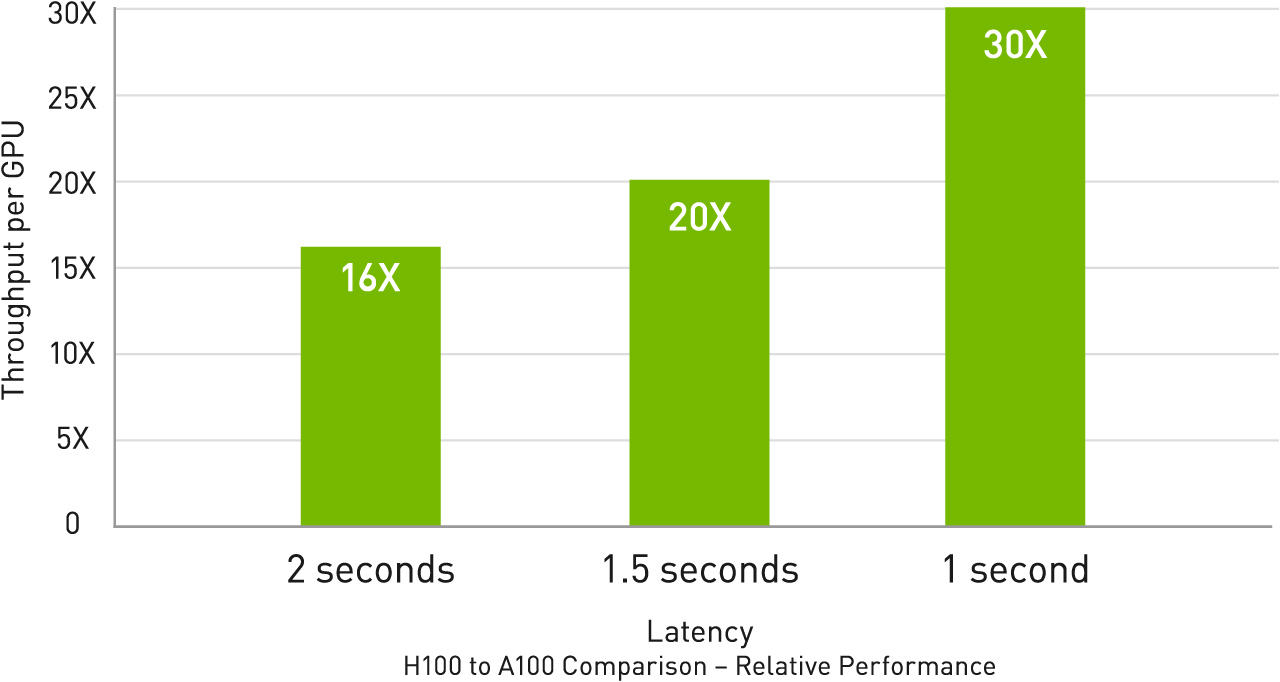
H100とA100のAI トレーニング パフォーマンス結果
H100とA100のAI 推論パフォーマンス結果
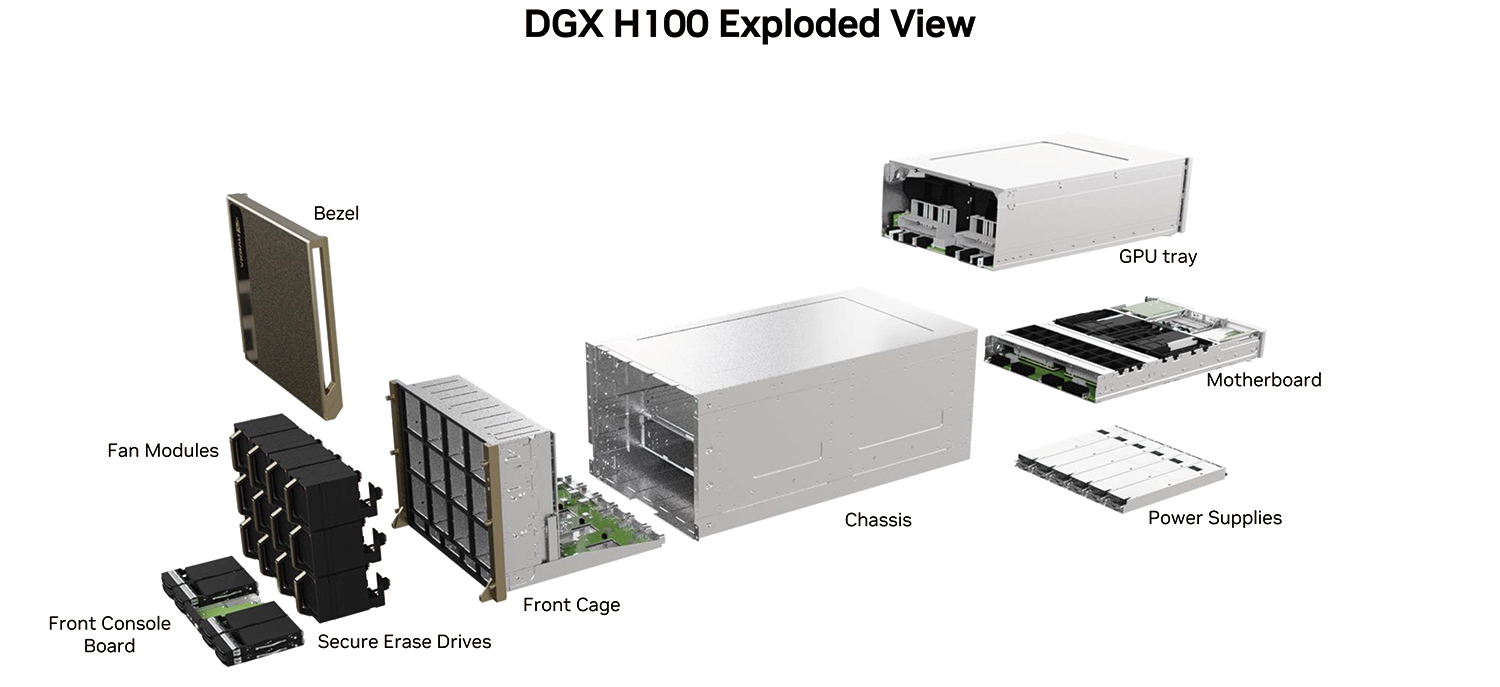
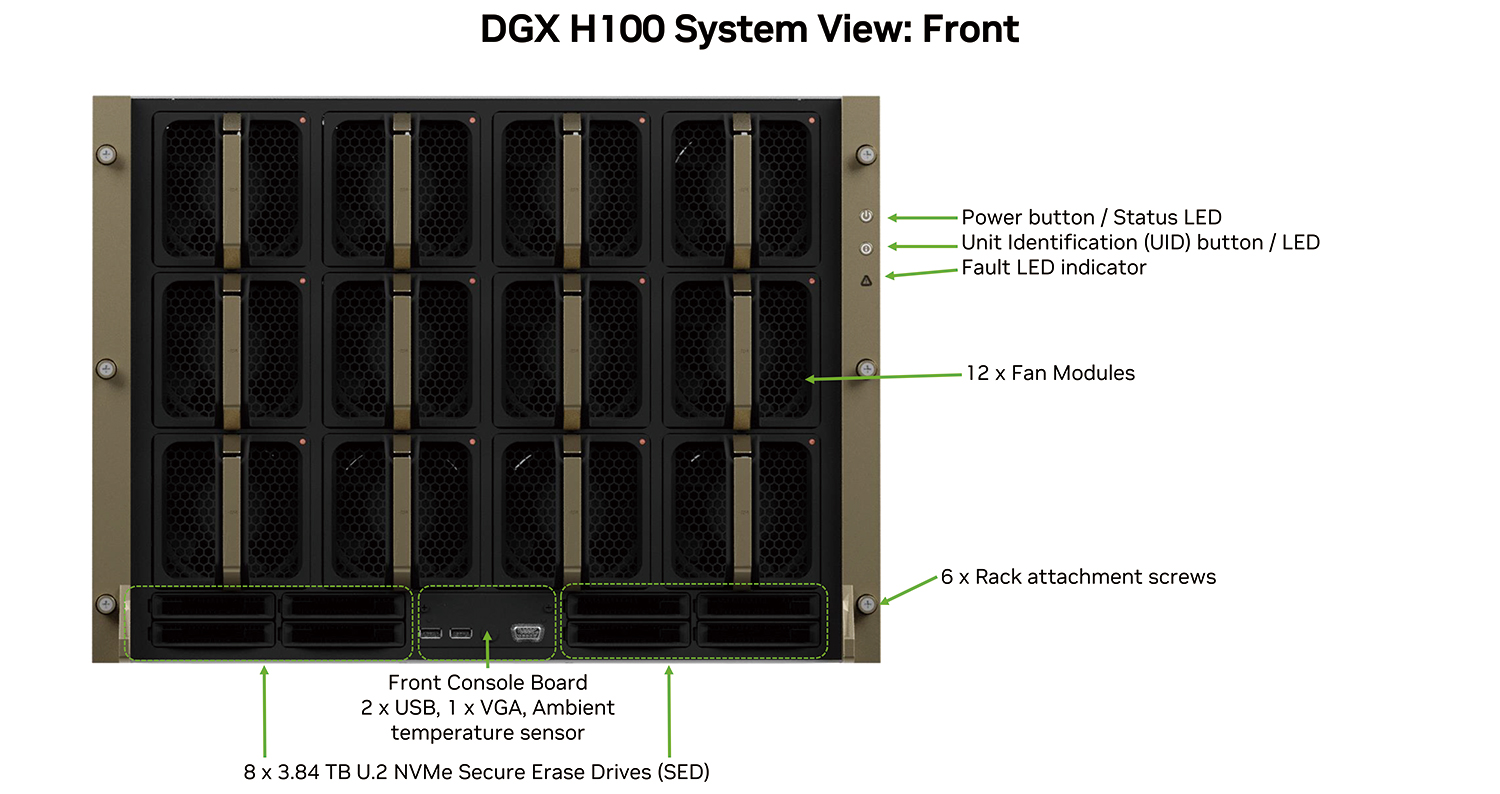
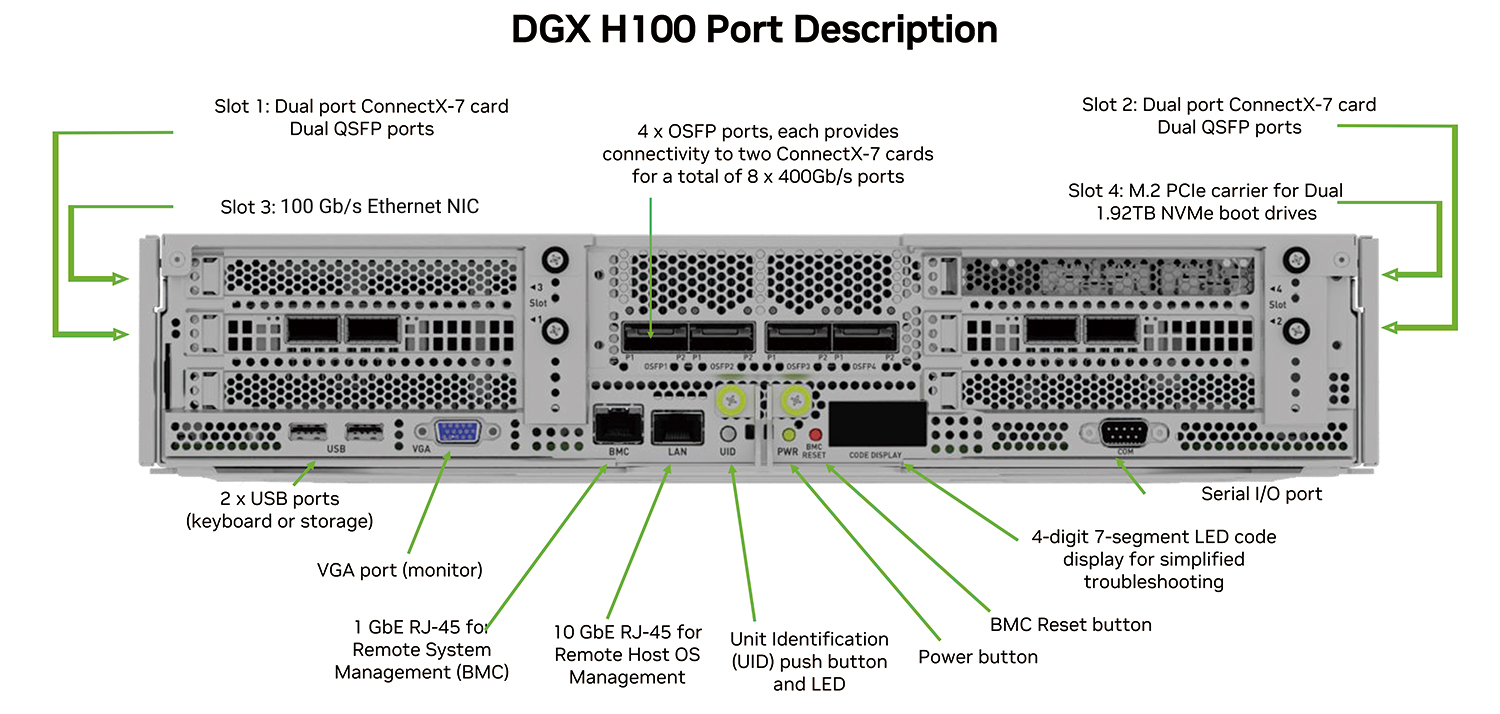
 システム解説
システム解説
DGX H100 ユーザガイド
● NVIDIA DGX H100 System User Guide
ホワイトペーパーダウンロード
● NVIDIA H100 Tensor Core GPU Architecture
GTC 2022 Keynote
 仕様・スペック
仕様・スペック

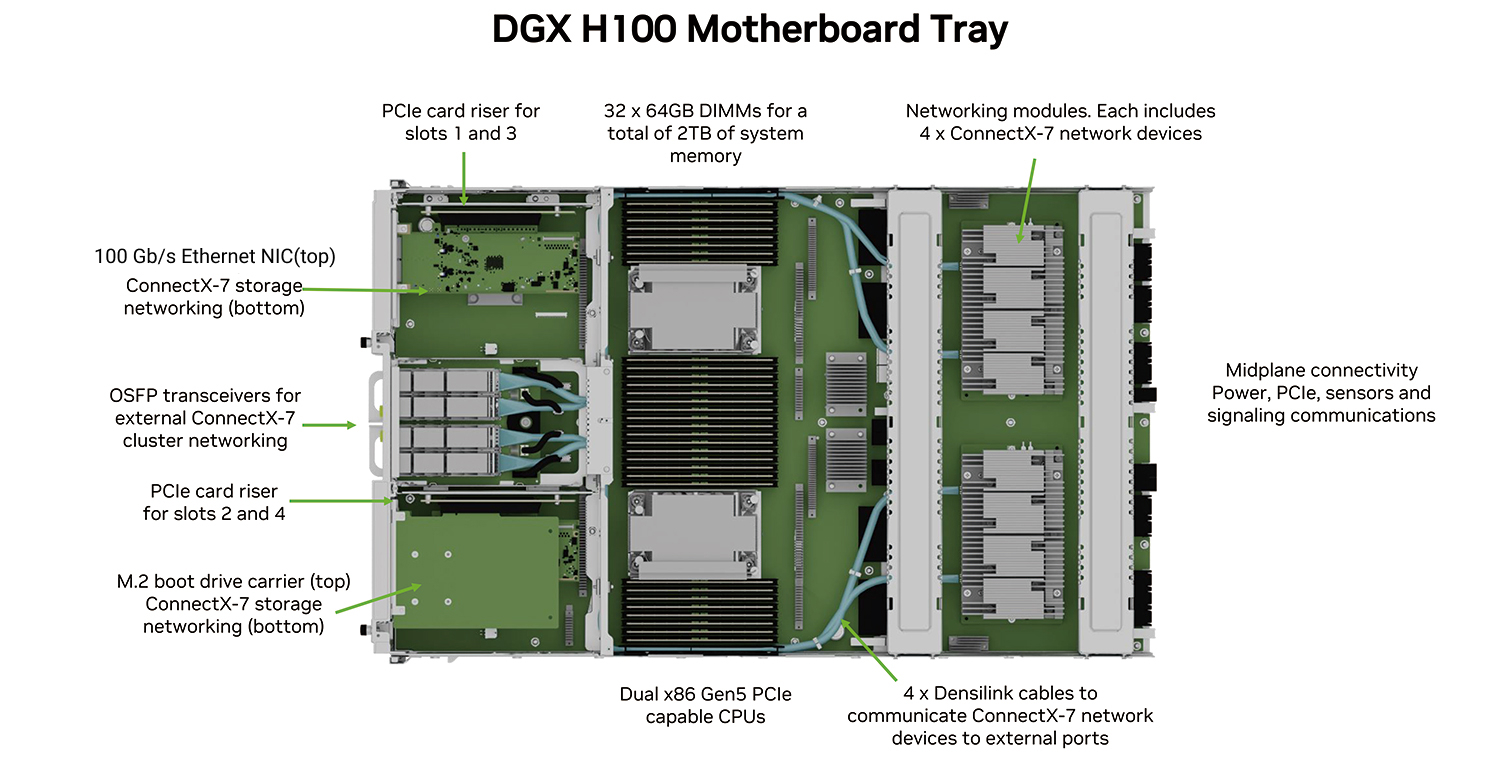
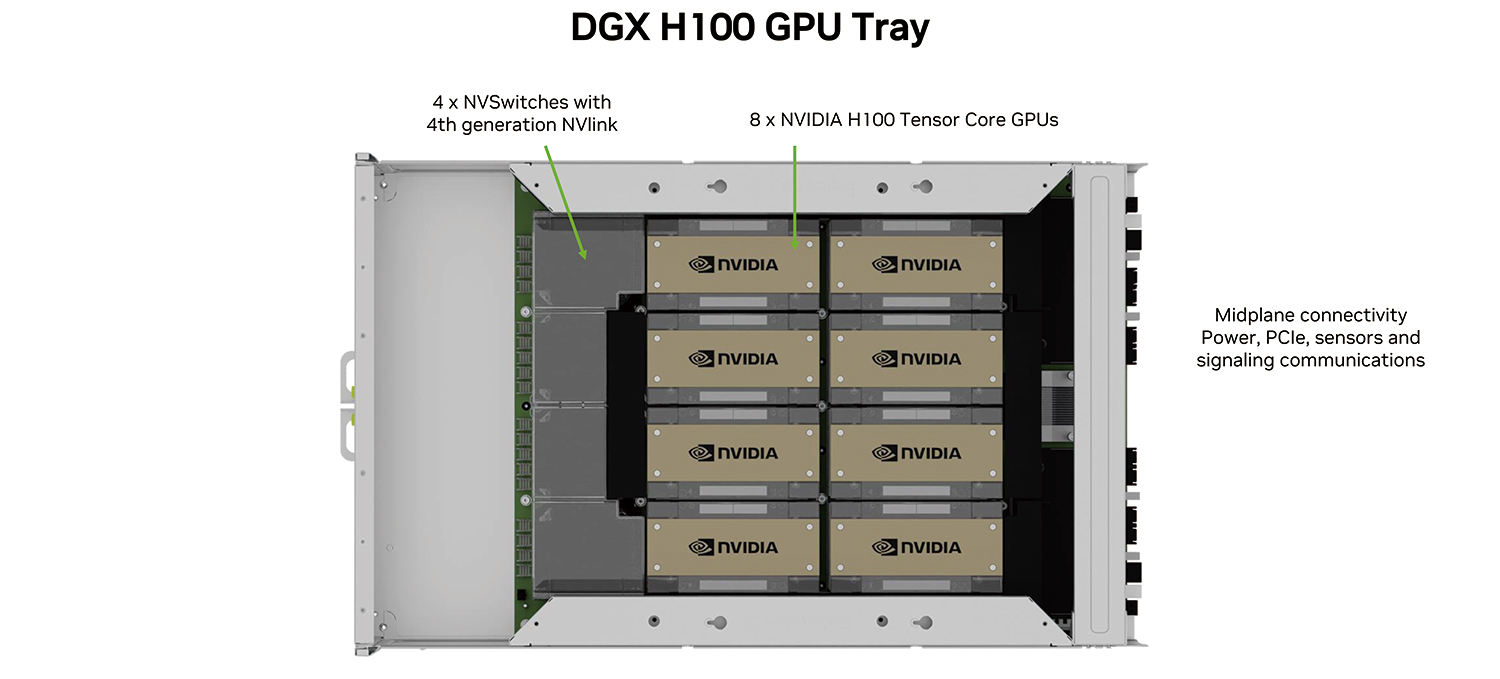
DGX H100
| SYSTEM | NVIDIA DGX H100 |
|---|---|
| GPU | 8x NVIDIA H100 Tensor Core GPUs |
| GPU memory | 640GB total |
| Performance | 32 petaFLOPS FP8 |
| NVIDIA® NVSwitch™ | 4 x 4th generation NVLink (GPU間帯域 900 GB/s) |
| System power usage | ~10.2kW max |
| CPU | 2x Intel® Xeon® Platinum 8480C (56cores,2.0GHz,TDP=350W) |
| System memory | 2TB |
| Cluster Network | 4 x OSFP ports (各 OSFPポートは NVIDIA ConnectX-7s (400Gb/s InfiniBand/Ethernet) 2ポートに接続) |
| Storage Network | 2 x dual-port NVIDIA ConnectX-7 (400Gb/s InfiniBand/Ethernet) |
| Host Management | 1x 10Gb/s RJ-45 Ethernet 1x 100Gb/s QSFP Ethernet |
| Remote System Management(BMC) | 1x 1Gb/s RJ-45 Ethernet (Redfish, IPMI, SNMP, KVM, Webインターフェイスをサポート) |
| Storage | OS: 2x 1.9TB NVMe M.2 Internal storage: 8x 3.84TB NVMe U.2 |
| System software | DGX H100 systems come preinstalled with DGX OS, which is based on Ubuntu Linux and includes the DGX software stack (all necessary packages and drivers optimized for DGX). Optionally, customers can install Ubuntu Linux or Red Hat Enterprise Linux and the required DGX software stack separately. |
| Operating temperature range | 5–30°C (41–86°F) |
DGX-H100-tensor-コアGPU
| フォーム ファクター | H100 SXM |
|---|---|
| FP64 | 30 teraFLOPS |
| FP64 Tensor コア | 60 teraFLOPS |
| FP32 | 60 teraFLOPS |
| TF32 Tensor コア | 1,000 teraFLOPS* | 500 teraFLOPS |
| BFLOAT16 Tensor コア | 2,000 teraFLOPS* | 1,000 teraFLOPS |
| FP16 Tensor コア | 2,000 teraFLOPS* | 1,000 teraFLOPS |
| FP8 Tensor コア | 4,000 teraFLOPS* | 2,000 teraFLOPS |
| INT8 Tensor コア | 4,000 TOPS* | 2,000 TOPS |
| GPU メモリ | 80GB |
| GPU メモリ帯域幅 | 3TB/秒 |
| デコーダー | 7 NVDEC |
| 7 JPEG | |
| 最大熱設計電力 (TDP) | 700W |
| マルチインスタンス GPU | 最大 7 個の MIG @ 10GB |
| フォーム ファクター | SXM |
| 相互接続 | NVLink: 900GB/秒 PCIe Gen5: 128GB/秒 |
| サーバー オプション | 4 または 16 GPU 搭載の NVIDIA HGX™ H100 パートナーおよび NVIDIA-Certified Systems™ 8 GPU搭載の NVIDIA DGX™ H100 |
* 疎性あり
会社名及び製品名等は、当社及び各社の商標または登録商標です。価格、写真、仕様等は予告なく変更する場合があります。製品の色調及び仕様は実際と異なる場合があります。
NVIDIA Partner Network(NPN)に認定されました
HPCシステムズは、NVIDIA社のパートナー認定制度 “NVIDIA Partner Network (NPN)” において、「DGX AI Compute System」 「Networking」 「Compute」 の3つのコンピテンシーで最上位レベルのELITE PARTNER に認定されています。
HPC システムズは、Solution Provider と Solutions Integration Partner の二つのパートナーカテゴリーをカバーする製品知識と、長年培ってきた高度な HPC-AI システムインテグレーション技術を掛け合わせることで、お客様の研究・開発の加速化、効率化に対する最適解を提供してまいります。
※ NVIDIA パートナー ネットワーク (NPN) は、NVIDIA が展開するパートナープログラムです。 2024年7月現在、日本国内の企業が約80社加入しています。 NVIDIA パートナー ネットワーク (NPN) は、13種類のパートナーのタイプと、11種類のコンピテンシーで構成されています。
ご参考: NVIDIA パートナー ネットワーク (NPN)
お問い合わせ
お客様に最適な製品をご提案いたします。まずはお気軽にお問い合わせください。
03-5446-5531
平日9:00~18:00(土・日・祝日は除きます)
※土曜日、日曜日、祝日、年末年始は、休日とさせていただきます。