





アプライアンス
販売終了製品:NVIDIA DGX Station™
NVIDIA® DGX Station™ パーソナル AI スーパーコンピュータ

オフィス向けに設計された NVIDIA® DGX Station™ は、最先端の AI 技術を搭載した世界初の個人向けスーパーコンピューターです。あらゆる NVIDIA DGX™ Systems の動力源となっている NVIDIA GPU Cloud Deep Learning Stack を基盤としており、ご自身のデスクで実験し、その作業を DGX Systems やクラウドに拡張できます。
最先端のAI開発向けパーソナルスーパーコンピュータ
データサイエンスチームは、ディープラーニング、データ分析の革新を、より速く実現するために、コンピューティングパフォーマンスを求めています。
これまで、AI スーパーコンピューティングはデータセンターに限定され、ディープニューラルネットワークを開発し、テストするための実験は、多くの研究者にとって敷居が高いものが有りました。
そこでディープラーニングを試すことができる、AI スーパーコンピューティングのパワーを、手の届くところで実現できるソリューションを開発しました。

AI開発環境を研究者のデスクに
NVIDIA DGX Station はオフィス向けに設計されており、デスク下で400個のCPUに匹敵する計算能力を得ることができ、消費電力はCPUクラスターの20分の1以下、騒音レベルは一般的なワークステーションの10分の1以下に抑えられています。
データサイエンティストとAI研究者は、最適化されたディープラーニングソフトウェアを手にすることができ、また汎用的なデータ分析ソフトウェアを高性能な計算環境で即座に実行することが可能で、研究開発の生産性を飛躍的に向上させることができます
ディープラーニングを早く始めよう
NVIDIA DGX Station は研究者が独自にディープラーニングプラットフォームを構築するという限界を打ち破ります。
フレームワーク、ライブラリ、ドライバを最適化するためには、専門知識と労力が必要です。NVIDIA DGX Stationを導入することで、研究者はシステムインテグレーションやソフトウェアエンジニアリングに貴重な時間と費用を奪われることなく、ディープラーニングトレーニングや実験に費やすことができます。
NVIDIA DGX Station は、AI 研究をスタートできるプラグインが用意されています。わずか1日で、パワーアップしたディープニューラルネットワークのトレーニングを経験できます。
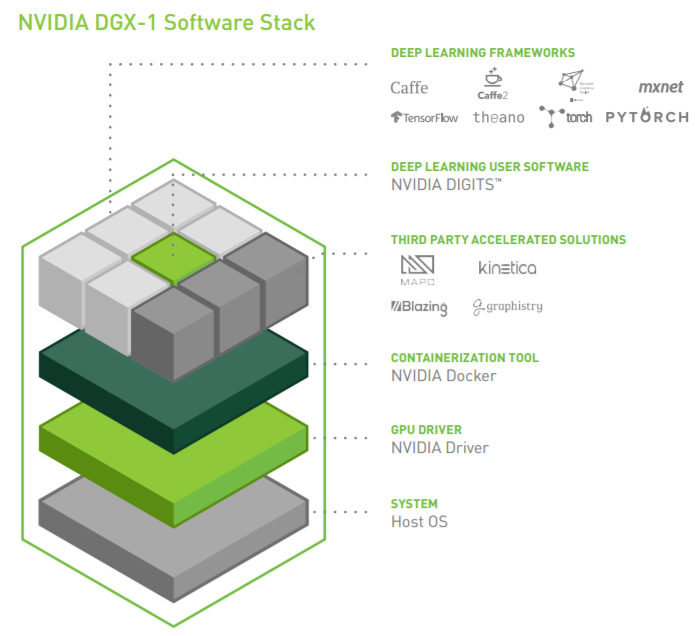
デスクからデータセンターまで ~ソフトウェアスタックがもたらす生産性~
ディープラーニングプラットフォームでは、ソフトウェアエンジニアリングの専門知識が必要となり、ディープラーニングの性能を最大限引き出すようにフレームワークを最適化し、オープンソースソフトウェアの安定版を待つ時間を確保する必要があり、これは数千万円の初期ハードウェアコストを無駄にすることと同じです。
NVIDIA DGX Station には、すべてのDGXソリューションと同じソフトウェアスタックが含まれています。NVIDIAのエンジニアによって最適化され、毎月更新される人気のディープラーニングフレームワークを利用することも、この革新的なシステムなら可能です。また、NVIDIA DIGITS ディープラーニング、サードパーティによるアクセラレーションソリューション、NVIDIAディープラーニングSDK(cuDNN、cuBLAS等)、CUDA ツールキット、マルチGPU通信ライブラリ NCCL、NVIDIAドライバへのアクセスも可能です。
NVIDIA Dockerを搭載したコンテナテクノロジーをベースに構築することで、ディープラーニングのソフトウェアスタックを統合し、ワークフローを簡素化しました。データセンターやクラウドにモデルを展開する場合には、再コンパイルの必要がありません。DGX Station で実行されているのと同じ環境を保って、DGX-1またはクラウドに簡単に移行できます。
スーパーコンピューティングのパフォーマンスをデスクで
NVIDIA DGX Station は、ワークステーション型にもかかわらず、スーパーコンピュータに匹敵する驚異的なパフォーマンスと、水冷システムによる静音性を実現しています。
NVIDIA DGX Stationは、次世代NVLinkや、Tensor コアアーキテクチャなどの革新技術を内包したNVIDIA® V100アクセラレータを4基実装した唯一無二のパーソナル AI スーパーコンピュータです。
主な特徴
- 最も高速なGPUワークステーションと比較して、ディープラーニングトレーニングで3倍のパフォーマンス
- 20ノードのSparkサーバークラスタと比較して、大規模なデータセット分析で100倍のスピードアップを実現
- NVIDIA NVLinkテクノロジにより、PCIe接続されたGPUよりもI/Oパフォーマンスが5倍向上
- ディープラーニングトレーニングと30,000 images/sec.の推論パフォーマンスで最大限の多機能性を実現
パフォーマンス
Tensor(多次元配列)演算処理のための専用コア「Tensorコア」

システム解説

システム仕様
| GPUs | 4x NVIDIA® V100 |
|---|---|
| Tensor演算性能 | 480TFLOPS |
| GPU メモリ | 128GB total system [GPU4基の合計] |
| NVIDIA Tensor コア | 2560 |
| NVIDIA CUDA コア | 20480 |
| CPU | Intel Xeon Processor E5-2698 v4 (20コア, 2.2GHz, 50MB L3Cache, TDP135W) |
| システムメモリ | 256GB LRDIMM DDR4 |
| ストレージ | Data: 3x 1.92TB SSD RAID0 OS: 1x 1.92TB SSD |
| ネットワーク | 2x 10Gigabit Ethernet |
| ディスプレイ | 3x DisplayPort, 4K 解像度 |
| 外部ポート | 2x eSATA, 2x USB 3.1, 4x USB 3.0 |
| 静音性 | 35dB(A) 未満 |
| システム重量 | 88lbs / 40kg |
| システムサイズ | D518mm x W256mm x H639mm *キャスター含む。床から本体底面までの高さは 28mm (当社測定値)。 |
| 梱包重量 | 100lbs / 45.5kg (当社測定値) |
| 梱包サイズ | D680mm x W525mm x H760mm |
| 最大消費電力 | 1500W |
| 運用温度 | 10-30℃ |
| ソフトウェア | Ubuntu Desktop Linux OS DGX 推奨 GPU ドライバ CUDA Toolkit |
| 製品名 | NVIDIA® V100 |
|---|---|
| GPU アーキテクチャ | GV100 (Volta) |
| 製造プロセス | 12nm |
| NVIDIA Tensor コア | 640 |
| NVIDIA CUDA コア | 5120 |
| コアクロック (GPU Boost時) | 1455MHz |
| Tensor演算性能 | 120TFLOPS |
| 単精度浮動小数点演算性能 [FP32] | 15TFLOPS |
| 倍精度浮動小数点演算性能 [FP64] | 7.5TFLOPS |
| メモリ容量 | 32GB |
| メモリインターフェイス | 4096-bit HBM2 |
| メモリ帯域幅 | 900GB/s |
| NVLink帯域幅 (双方向) ※ | 200GB/s |
| L2キャッシュ | 6MB |
| L1キャッシュ | 10MB |
| 総レジスタファイル | 20480KB |
| 最大消費電力 | 300W |
※NVIDIA® V100 for NVLink-enabled Servers に高速インターコネクト「NVLink」を6リンク備えていますが、DGX Station におけるGPU間接続リンク数は4リンクとなっております。NVLinkによるGPU間の接続帯域幅は1リンクあたり双方向50GB/s。4リンク合計で双方向200GB/sとなります。
NVIDIA Partner Network(NPN)に認定されました
HPCシステムズはNVIDIA社のパートナー認定制度 NVIDIA Partner Network (NPN) においてHigh Performance Computing (HPC) ならびに Deep Learning の ELITE PARTNER に認定されています。
また、DGX-2 の販売資格である Advanced Technology Program (ATP) のメンバーに認定されています。
NPNとは、NVIDIA社 の Solution Provider 向けの Program です。Solution Providerは、VAR(Value Added Reseller:付加価値再販業者)と呼ばれるパートナー企業が対象となります。
■ NVIDIA Partner Network(NPN)(NVIDIA社 Website)



お問い合わせ
平日9:30~17:30 (土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)