
Software
計算化学 ソフトウェア
GPUの使用(Using GPUs)
Gaussian 16は、Linux環境において、NVIDIA Tesla K40とK80 GPUを、P100(Rev. B.01)を、V100(Rev. C.01)を、使用できます。それより前のGPUでは、Gaussian 16のアルゴリズムを実行するための演算能力(Computational Capabilities)やメモリサイズが十分ではありません。
Gaussian 16 can use NVIDIA K40, K80, P100 (Rev. B.01) and V100 (Rev. C.01) GPUs under Linux. Earlier GPUs do not have the computational capabilities or memory size to run the algorithms in Gaussian 16.
ジョブに対するメモリの割り当て
(Allocating Memory for Jobs)
CPU使用時よりもGPU使用時の方が、十分な量のメモリをジョブに割り当てることがとても重要になります。なぜなら、GPUを効率的に使用するには、計算タスクをより大きな粒度で複数同時に実行する必要があるためです。Tesla K40とTesla K80は最大16 GBのメモリを搭載しています。通常、この容量のうちの大部分はGaussian 16から利用出来るようになっています。Gaussianに8~9GBを与えれば、各GPUで12GBを利用可能な状況において良好に動作します。同様に、16GB搭載GPUにおいては、11~12GBを与えれば良好に動作します。付け加えて言うと、1個のGPUを制御するCPUスレッドそれぞれにおいて、GPUに与えるのと同容量のメモリが(ホスト側で)利用可能になっていなければなりません。
Allocating sufficient amounts of memory to jobs is even more important when using GPUs than for CPUs, since larger batches of work must be done at the same time in order to use the GPUs efficiently. The K40 and K80 units can have up to 16 GB of memory. Typically, most of this should be made available to Gaussian. Giving Gaussian 8-9 GB works well when there is 12 GB total on each GPU; similarly, allocating Gaussian 11-12 GB is appropriate for a 16 GB GPU. In addition, at least an equal amount of memory must be available for each CPU thread which is controlling a GPU.
制御用CPUについて(About Control CPUs)
GPUを使用する場合、各GPUは特定のCPUによって(役割的に)制御されなければなりません。制御用CPUは、制御対象GPUと物理的にできるだけ近い位置にあるべきです(例えば、制御対象GPUを挿入できるPCI Expressバスが複数スロット存在する場合に、制御用CPUから出ているPCI Expressバスの方(のスロット)に制御対象GPUが接続されていることが望ましいと言えます)。GPUは制御用CPUを共有できません。 GPUコントローラとして使用されるCPUは、GPU並列な計算の部分の間においては、そのGaussianジョブの計算用CPUとして参加しないことに注意してください。
GPUを搭載しているシステム上のハードウェアの位置関係は、nvidia-smiユーティリティを使用して確認できます。 たとえば、2個の16コアHaswell CPUチップと4個のTesla K80ボード(各Tesla K80は内部的に2個の論理GPUを持っています)を持つマシンにおけるnvidia-smiの出力を次に示します。
When using GPUs, each GPU must be controlled by a specific CPU. The controlling CPU should be as physically close as possible to the GPU it is controlling. GPUs cannot share controlling CPUs. Note that CPUs used as GPU controllers do not participate as compute nodes during the parts of the calculation that are GPU-parallel.
The hardware arrangement on a system with GPUs can be checked using the nvidia-smi utility. For example, this output is for a machine with two 16-core Haswell CPU chips and four K80 boards, each of which has two GPUs:
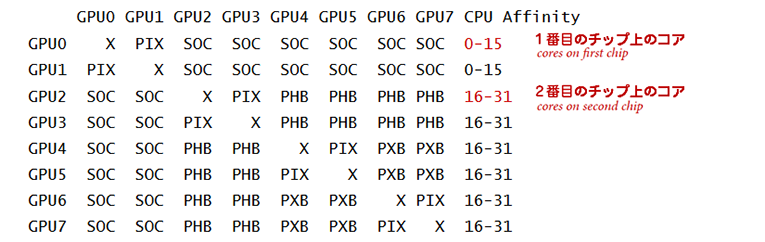
凡例) X:自分自身
SOC:ソケットレベルのリンク(例えばQPI)を通る経路
PIX:PCI Express内部スイッチ(例えばK80内部のPCI Expressスイッチ)を通る経路
PXB:複数のPCI Express内部スイッチを通る経路
PHB:PCI Expressホストブリッジを通る経路
この出力で重要な部分は、CPUアフィニティです。 この例では、GPU 0と1(最初のK80カード)は1番目のCPUに接続され、GPU 2~7(他の2個のK80カード)は2番目のCPUに接続されていることを示しています。
The important part of this output is the CPU affinity. This example shows that GPUs 0 and 1 (on the first K80 card) are connected to the CPUs on chip 0 while GPUs 2-7 (on the other two K80 cards) are connected to the CPUs on chip 1.
GaussianジョブにおけるGPUと制御用CPUの指定(Specifying GPUs & Control CPUs for a Gaussian Job)
計算に使用するGPUとそれらの制御用CPUは、%GPUCPU という Link 0コマンドで指定します。このコマンドは1個のパラメータをとります。
The GPUs to use for a calculation and their controlling CPUs are specified with the %GPUCPU Link 0 command. This command takes one parameter:
%GPUCPU=gpu-list=control-cpus
gpu-list にはGPUの番号をカンマ区切りで入力します( 0-4,6 というように数値範囲で記述することも可能です)。control-cpus にはgpu-listと同じ形式でCPUの番号を入力します。2つのlistの中の対応する項目どうしは、GPUとそのGPUのための制御用CPUをあらわします。
例えば、6個のGPUと32個のCPUを有するシステムにおいて、ジョブが全てのCPU(計算ノードとして寄与する26個のCPUとGPUを制御するために使用された6個のCPU)を使用する場合は、次のLink 0コマンドを使用します。
where gpu-list is a comma-separated list of GPU numbers, possibly including numerical ranges (e.g., 0-4,6), and control-cpus is a similarly-formatted list of controlling CPU numbers. The corresponding items in the two lists are the GPU and its controlling CPU.
For example, on a 32-processor system with 6 GPUs, a job which uses all the CPUs—26 CPUs serving solely as compute nodes and 6 CPUs used for controlling GPUs—would use the following Link 0 commands:
%CPU=0-31 制御用CPUがこのリストに含まれています
%GPUCPU=0,1,2,3,4,5=0,1,16,17,18,19
これらのコマンドは、CPU 0~31がジョブで使用されることを意味します。GPU0〜5は、GPU0はCPU0によって制御され、GPU1はCPU1によって制御され、GPU2はCPU16によって制御され、GPU3はCPU17によって制御されるというように、使用されます。%CPUは制御用CPUを含んでいる事に留意してください。
前の例では、GPUリストとCPUリストは、次のように、より簡潔に記述できます。
These command state that CPUs 0-31 will be used in the job. GPUs 0 through 5 will be used, with GPU0 controlled by CPU 0, GPU1 controlled by CPU 1, GPU2 controlled by CPU 16, GPU3 controlled by CPU 17, and so on. Note that the controlling CPUs are included in %CPU.
In the preceding example, the GPU and CPU lists could be expressed more tersely as:
%CPU=0-31
%GPUCPU=0-5=0-1,16-19
通常、連続したプロセッサをこのようにわかりやすい書き方で使うでしょうが、特殊な状況下ではそうならないこともあります。例えば、同じマシンにすでに%CPU=16-21として6個のCPUを使うジョブがすでにある状況を考えてみます。そのときには、6個のGPUとすでに使用されている6個を除いた26個のCPUを用いるように、次のように指定します。
Normally one uses consecutive processors in the obvious way, but things can be associated differently in special cases. For example, suppose the same machine already had a job using 6 CPUs, running with %CPU=16-21. Then, in order to use the other 26 CPUs with 6 controlling GPUs, you would specify:
%CPU=0-15,22-31
%GPUCPU=0-5=0-1,22-25
このジョブでは合計26個のCPUを使います。そこでは、計算のために20個が使われ、CPU 0, 1, 22, 23, 24, 25によって制御される6個のGPUが使われるでしょう。
This job would use a total of 26 processors, employing 20 of them solely for computation, along with the six GPUs controlled by CPUs 0, 1, 22, 23, 24 and 25 (respectively).
Rev. B.01 では、CPUとGPUのリストが両方とも整列されてからマッチングが行われます。このことは、最小番号のスレッドが、GPUを持っているCPU上で実行されることを確かにします。このようにすることで、計算の一部において (例えば、メモリ容量制限等の理由で、) プロセッサー数を削減しなければならなくなった場合に、GPUを有するスレッドを優先的に使う/保持することになる(なぜならスレッドの削減は逆順に行われるため)。
In [REV B], the lists of CPUs and GPUs are both sorted and then matched up. This ensures that the the lowest numbered threads are executed on CPUs that have GPUs. Doing so ensures that if a part of a calculation has to reduce the number of processors used (i.e., because of memory limitations), it will preferentially use/retain the threads with GPUs (since it removes threads in reverse order).
GPUと全体的なジョブ性能(GPUs and Overall Job Performance)
GPUは、大きな分子系における、DFTでのエネルギー計算・勾配計算・および振動数計算(基底状態と励起状態の両方)に効果的ですが、小さなジョブには効果的ではありません。 また、MP2やCCSDのようなpost-SCF計算においても効果的に使われません。
各々のGPUは1個のCPUより数倍高速です。 しかし、近年の計算機では、一般的にGPUよりも多いCPUが搭載されています。 最高の性能は全CPUと全GPUを使用することで達成されます。
ある状況では、Gaussian 16で多くのCPUもまた効果的に使用されるため、GPUによる潜在的な速度向上が限られることがあります。たとえば、GPUがCPUよりも5倍速いと仮定した場合、CPUを単独で使用するのと比べてGPUを使用すると速度向上は5倍でしょう。しかし、32個の CPUと8 個のGPUを有する大規模計算機でGPUを使用すると、潜在的な速度向上は2倍です。
GPUs are effective for larger molecules when doing DFT energies, gradients and frequencies (for both ground and excited states), but they are not effective for small jobs. They are also not used effectively by post-SCF calculations such as MP2 or CCSD.
Each GPU is several times faster than a CPU. However, on modern machines, there are typically many more CPUs than GPUs. The best performance comes fromm using all the CPUs as well as the GPUs.
In some circumstances, the potential speedup from GPUs can be limited because many CPUs are also used effectively by Gaussian 16. For example, if the GPU is 5x faster than a CPU, then the speedup of using the GPU versus the CPU alone would be 5x. However, the potential speedup resulting from using GPUs on a larger computer with 32 CPUs and 8 GPUs is 2x:
GPU無しの場合: 32*1 = 32
GPU有りの場合: (24*1) + (8*5) = 64 制御用CPUは計算に使用されないことに留意して下さい
速度向上: 64/32 = 2倍
ここでは、計算の中のGPU並列部分が総実行時間の大半を占めている と仮定した解析であることに注意してください。
Note that this analysis assumes that the GPU-parallel portion of the calculation dominates the total execution time.
メモリの確保。GPUは16GBまでのメモリを有する可能性があります。ある人はそのほとんどをGaussianに対して利用可能とするように試すでしょう。このとき、GPUを計算のために確保して使うCPUスレッドに対して、等しい量のメモリが存在するように注意してください。12GB GPUにおいて 8-9GB を使うことは良好に動作するでしょうし、16GB GPUにおいて 11-12GB を使うことも同様です(システムのために一部メモリを予約しています)。Gaussianは全スレッドに対してメモリ量を等分します。GPUを効率よく使うためには、確保される総メモリが、スレッド数と必要なメモリの積になっているべきです。例えば、4CPU と、それぞれ16GBのメモリを有するGPUを2基使用する場合、4 × 12 GBの総メモリを使うべきです。
Allocation of memory. GPUs can have up to 16 GB of memory. One typically tries to make most of this available to Gaussian. Be aware that there must be at least an equal amount of memory given to the CPU thread running each GPU as is allocated for computation. Using 8-9 GB works well on a 12 GB GPU, or 11-12 GB on a 16 GB GPU (reserving some memory for the system). Since Gaussian gives equal shares of memory to each thread, this means that the total memory allocated should be the number of threads times the memory required to use a GPU efficiently. For example, when using 4 CPUs and 2 GPUs each with 16 GB of memory, you should use 4 × 12 GB of total memory. For example:
%Mem=48GB
%CPU=0-3
%GPUCPU=0-1=0,2
使用するプロセッサとGPUを決定するとき・どのくらいの量のメモリを確保するのかを決定するときは、お使いの環境の特性に十分理解する必要があります。
You will need to analyze the characteristics of your own environment carefully when making decisions about which processors and GPUs to use and how much memory to allocate.
クラスター内のGPU(GPUs in a Cluster)
クラスタ計算機内のノード上にあるGPUを使用できます。%CPUと%GPUCPUの指定はクラスタ内の各ノードに対して適用されるため、ノードの構成(GPUの数やCPUに対するアフィニティ)は同じでなければなりません。 ほとんどのクラスタは同一ノードの集まりになっているため、この制限は通常問題とはなりません。
GPUs on nodes in a cluster can be used. Since the %CPU and %GPUCPU specifications are applied to each node in the cluster, the nodes must have identical configurations (number of GPUs and their affinity to CPUs); since most clusters are collections of identical nodes, this restriction is not usually a problem.



お問い合わせ
平日9:30~17:30 (土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)