





アプライアンス
販売終了製品:NVIDIA DGX Station A100
世界で唯一のペタスケール統合AIワークステーション

DGX Station A100は、世界で唯一のペタスケール統合AIワークステーションであり、第二世代のDGXステーションは、4基のNVIDIA A100 GPUを搭載し、最大320GBのGPUメモリを搭載、2.5ペタフロップスのAIパフォーマンスを実現します。
4基の80GBのNVIDIA A100 Tensor Core GPUを搭載しており、データサイエンスやAI研究チームが独自のワークロードや予算に応じてシステムを選択できるオプションを提供しています。
企業のオフィス、研究施設、研究所、またはホームオフィスで働くチームに向け、要求負荷の高い機械学習とデータサイエンスのワークロードを加速します。
AIトレーニングを加速
ディープラーニングデータセットはますます大きく複雑になり、会話型AI、レコメンダーシステム、コンピュータービジョンなどのワークロードが業界全体でますます普及しています。
統合ソフトウェアスタックが付属するNVIDIADGX Station A100は、PCIeベースのワークステーションと比較して、複雑なAIモデルでソリューションを実現するまでの時間を最速で実現するように設計されています。
データサイエンスチーム向けのAIスーパーコンピューティング
トレーニング、推論、データ分析などのすべてのワークロードに一元化されたAIリソースを複数のユーザーに提供できます。これにより他のNVIDIA認定システムと連携して機能します。
また、マルチインスタンスGPU(MIG)を使用すると、最大28個の個別のGPUデバイスを個々のユーザーとジョブに割り当てることができます。
NVIDIA DGX A100システムと同じソフトウェアスタックを使用
DGX Station A100は、NVIDIA DGX A100システムと同じソフトウェアスタックを使用して作業を加速することができ、開発から展開まで容易にスケールアップすることができます。
AIイノベーションを後押し
世界中の組織がDGX Station A100を採用し、教育、金融サービス、政府、ヘルスケア、小売などの業界全体でAIやデータサイエンスを強化しています。
例えばドイツの人工知能研究センターでは、DGX Stationを使用して、社会や産業の課題に対応するために、緊急時の対応を支援するコンピュータビジョンシステムをはじめとする 自然災害の問題に取り組むモデルを構築しています。
データセンターを利用しなくてもデータセンターのパフォーマンス
DGX Station A100はデータセンターの電力と冷却を必要としないサーバーグレードのAIシステムです。
4つのNVIDIAA100 TensorコアGPU、最高級のサーバーグレードCPU、超高速NVMeストレージ、 最先端のPCIe Gen4バスに加え、サーバーのように管理できるリモート管理が含まれています。
どこにでも設置できるAIアプライアンス
企業のオフィス、ラボ、研究施設、さらには自宅で作業する開発者向けに設計されており、複雑な インストールや重要なITインフラストラクチャは必要ありません。
標準の壁コンセントに差し込むだけで、数分で起動して実行し、どこからでも作業できます。
AI、HPC向けにGPUメモリを倍増
NVIDIA DGX A100 640GBシステムは、エンタープライズでは、企業がターンキーAIスーパーコンピュータ上で大規模なAIモデルを構築、トレーニング、展開することを可能にします。20台のDGX A100システムを搭載し、NVIDIA DGX SuperPOD™ソリューションに統合することもできます。AI チームは大規模なデータセットやモデルでの精度をさらに高めることができます。
ハイパフォーマンスコンピューティングにも最適なシステム
4つのNVIDIAA100 Tensor CoreGPUを搭載したDGXStation A100は、開発者がHPCクラスターに 展開する前に科学的なワークロードをテストするのに最適なシステムで、オフィスや自宅からでも
画期的なパフォーマンスを実現できます。
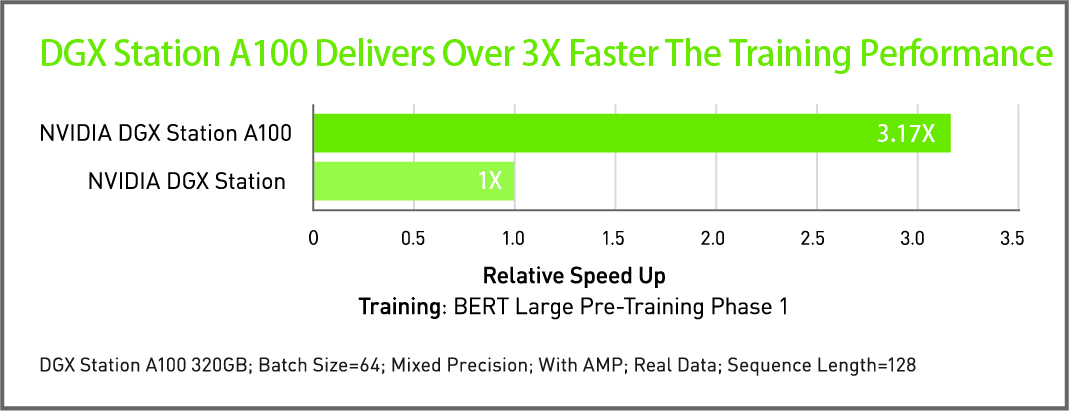
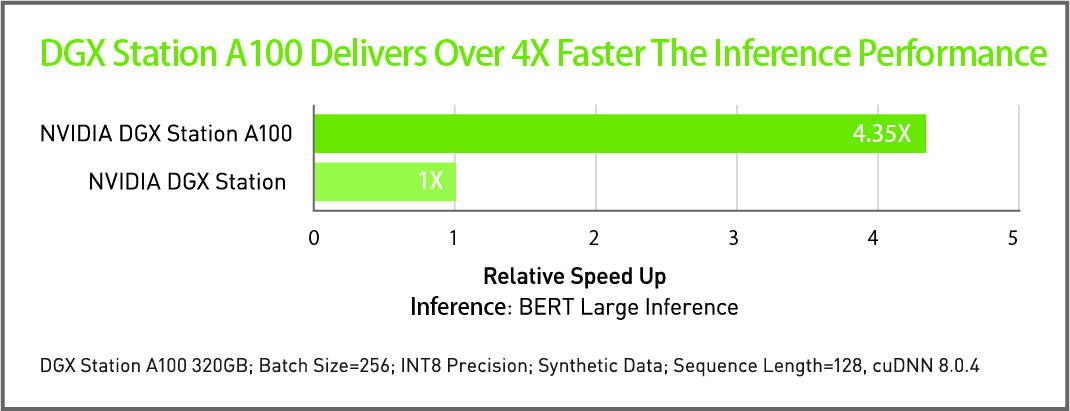
パフォーマンス
高性能トレーニングは生産性を加速します。洞察までの時間が短縮され、市場投入までの時間が短縮されます。

システム仕様
| モデル名 | NVIDIA DGX Station A100 320GB |
|---|---|
| GPUs | 4x NVIDIA A100 80GB GPUs |
| Tensor演算性能 | 2.5 petaFLOPS AI 5 petaOPS INT8 |
| GPU メモリ | 320 GB total |
| CPU | Single AMD 7742, 64 cores, 2.25 GHz (base)‒3.4 GHz (max boost) |
| システムメモリ | 512 GB DDR4 |
| 内蔵ストレージ | OS: 1x 1.92 TB NVME drive Internal storage: 7.68 TB U.2 NVME drive |
| 内蔵ストレージ最大容量 | 7.68 TB |
| ネットワーク | Dual-port 10Gbase-T Ethernet LAN Single-port 1Gbase-T Ethernet BMC management port |
| ディスプレイアダプター | 4 GB GPU memory, 4x Mini DisplayPort |
| 静音性 | 37dB(A) 未満 |
| システム重量 | 91lbs / 43.1kg |
| システムサイズ | Height: 25.1 in (639 mm) Width: 10.1 in (256 mm) Length: 20.4 in (518 mm) |
| 梱包重量 | 127.7lbs / 57.93kg |
| 最大消費電力 | 1.5 kW at 100‒120 Vac |
| 運用温度 | 5–35 ºC (41–95 ºF) |
| ソフトウェア | Ubuntu Desktop Linux OS DGX 推奨 GPU ドライバ CUDA Toolkit |
| アーキテクチャ | Ampere |
|---|---|
| プロセスルール | 7nm(TSMC) |
| 倍精度性能 | FP64 : 9.7TFLOPS FP64 Tensor Core : 19.5TFLOPS |
| 単精度性能 | FP32 : 19.5TFLOPS Tensor Float 32(TF32) : 156TFLOPS(Structural sparsity有効時312TFLOPS) |
| 半精度性能 | 312TFLOPS(Structural sparsity有効時624TFLOPS) |
| Bfloat16 | 312TFLOPS(Structural sparsity有効時624TFLOPS) |
| 整数性能 | INT8 : 624TOPS(Structural sparsity有効時1,248TOPS) INT4 :1,248TOPS(Structural sparsity有効時2,496TOPS) |
| GPUメモリ | 80GB HBM2 |
| メモリ帯域 | 1.935TB/s |
| ECC | 有効 |
| グラフィックス バス | PCI-Express 4.0 x16 : 64GB/s |
| マルチインスタンスGPU(MIG) | 最大7GPU |
| 最大消費電力 | 300W |
| 実アプリ性能 | 90% |
| 冷却方法 | Passive |
| API | CUDA、DirectCompute、OpenCL、OpenACC |
| 概形寸法 | 2スロットサイズ |
NVIDIA Partner Network(NPN)に認定されました
HPCシステムズはNVIDIA社のパートナー認定制度 NVIDIA Partner Network (NPN) においてHigh Performance Computing (HPC) ならびに Deep Learning の ELITE PARTNER に認定されています。
また、DGX-2 の販売資格である Advanced Technology Program (ATP) のメンバーに認定されています。
NPNとは、NVIDIA社 の Solution Provider 向けの Program です。Solution Providerは、VAR(Value Added Reseller:付加価値再販業者)と呼ばれるパートナー企業が対象となります。
■ NVIDIA Partner Network(NPN)(NVIDIA社 Website)



お問い合わせ
平日9:30~17:30 (土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)