
技術情報
NVIDIA® GeForce® GTX 1080 のDeep Learningにおける学習性能を比較
Pascalアーキテクチャーを採用したGeForce GTX 1080がリリースされました。
消費電力が180Wと前世代のTesla、GeForce GTX TITAN Xよりも大幅に小さくなったにも関わらず、単精度浮動小数演算性能が最大8.9TFLOPSと前製品を大きく上回るスペックで、Deep Learningにおける学習の効率化にも大きく期待されます。
今回は、GTX 1080、Tesla M40、Tesla K80という現行製品のGPUカードの性能比較を行いました。GPUカードあたりの性能比較のため、Tesla K80のみ、GPUチップ2並列でベンチマークを取得しています。
| GPU | Geforce GTX 1080 | Tesla M40 | Tesla K80 |
|---|---|---|---|
| アーキテクチャー | Pascal | Maxwell | Kepler |
| CUDAコア | 2560 | 3072 | 2496 x2 |
| コアクロック | 1.607~1.733GHz | 0.948~1.114 GHz | 0.562~0.875 GHz |
| 単精度浮動小数演算性能 | 8.2~8.9 TFLOPS | 5.8~6.8 TFLOPS | 5.6~8.7 TFLOPS |
| メモリ容量 | 8 GB | 12 GB | 12 x2 GB |
| メモリ帯域幅 | 320 GB/s | 288 GB/s | 240 x2 GB/s |
| 消費電力 | 180 W | 250 W | 149 x2 W |
| OS | Ubuntu 14.04.3 LTS |
|---|---|
| CUDAバージョン | 8.0rc |
| cuDNN バージョン | 5.0 |
| Frame work | Caffe-nv 0.14.4 |
Googlenet
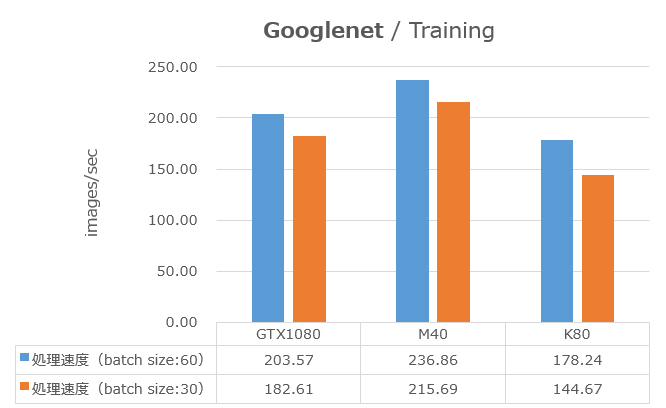
Googlenetのベンチマークをとりました。各GPUでの性能をグラフの青色の棒で示します(Tesla K80はGPUチップ2つで並列しています。)GTX 1080の性能がTesla M40に劣る結果となりました。GTX 1080とTesla M40との差は16%と大きく、GPU上のメモリ帯域幅だけでは説明がつかない差と考えます。ベンチマーク中はGPU負荷率が100%に張り付いていたため、その点からもメモリがボトルネックとは考えにくいです。
GPU上のメモリ消費量はbatch size 60 の時、GTX 1080は88%、M40は56%でした。メモリ量がパフォーマンスに影響してないか確かめるために、batch sizeを30に落としてベンチマークを取りました。この結果をグラフのオレンジ色の棒で示します。batch size が半分になると、メモリ消費量は約半分になり、GTX 1080は48%、M40は30%消費していました。GPU上のメモリに空きがある状態でも、GPUカード間の性能差が大きく変化しませんでした。この結果から、使用GPUメモリ量がGPUカードのパフォーマンスに影響を与えていないことが分かります。
※ Googlenetとは
ILSVRC2014において、最も高い画像認識率を示したニューラルネットワークモデル。22層の畳み込み層からなり、全結合層を持たないという特徴的な構成をしています。このことからcuDNNの性能がよく表れるモデルのため、ベンチマークでよく用いられます。画像認識で、よく用いられるモデルです。
AlexNet
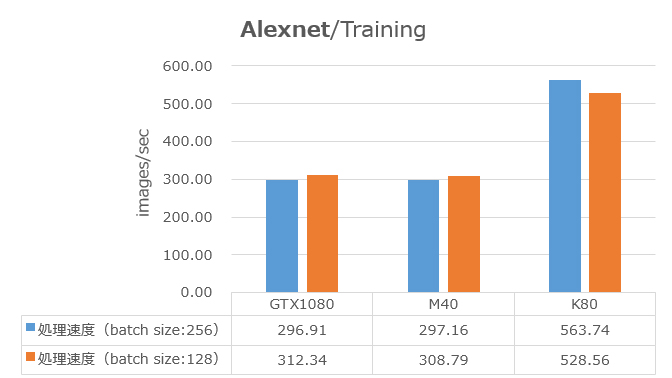
AlexNetでのベンチマーク結果を次図に示します(Googlenet同様に、Tesla K80はGPUチップ2つで並列しています)。このモデルでは、GTX 1080とTesla M40との差は、ほぼありませんでした。AlexNetはGooglenetに比べて、モデルが小さく、GPUの負荷がかなり低いことが観測されました。このことから、AlexNetではGPU上のメモリ帯域幅がボトルネックとなっていると考えられます。Tesla K80が他のGPUカードの倍近い性能が出ていることも、メモリ帯域幅ボトルネックを示唆していると言えます。Tesla K80はカード内で2つのGPUチップを持ち、今回は並列計算しているため、カードあたりのメモリ帯域幅は、実質、他のカードの2倍近くなるためです。
ベンチマーク実行中のGPUメモリ消費量は、batch size 256の時、GTX 1080は98%、M40は60%、batch size 128の時は、GTX 1080は58%、M40は38%となっていました。青色とオレンジ色の棒の比較から、batch size(GPUメモリ消費量)によってGPUカード間の性能差に大きな変化は見られませんでした。
※ AlexNetとは
ILSVRC2012において、前年の優勝データを大きく上回る画像認識率を示し、Deep Learningの火付け役となったニューラルネットワークモデル。5層の畳み込み層と、3層の全結合層の8層からなります。現在でも、画像認識に関わらず、多くの分野で、このモデルと同じようなモデルをよく目にします。
Googlenet (without cuDNN, batch size: 60)
cuDNN無しでCaffe-nvをビルドし直し、GooglenetのベンチマークをGTX 1080とTesla M40でとりました。性能を次図に示します。cuDNN有りと比べて、GTX 1080の速度が、Tesla M40を逆転しました。巷で言われている性能差を、ここで確認できました。
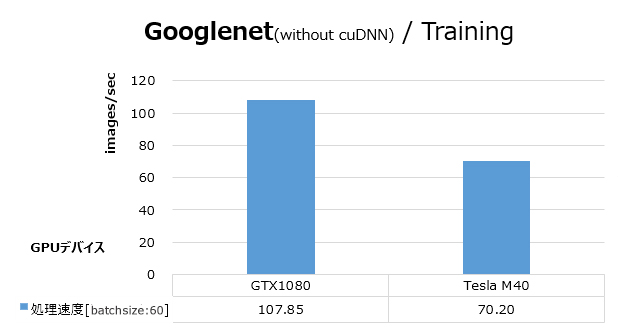
cuDNNを使った場合にはTesla M40の方がGTX 1080よりも高い性能となっていました(最初のグラフ)。cuDNNを用いることで、Tesla M40は3倍に性能向上していますが、GTX 1080では2倍の性能向上にとどまっています。このことから、cuDNNライブラリにおけるPascalアーキテクチャー向けの最適化度合いがMaxwellに比べると低いのではないかと推察されます。今後のcuDNNのさらなる最適化に期待が高まります。
追記(2016/6/24)
cuDNN v5.0 for CUDA 8.0rc が公開されました。このcuDNNでCaffe-nvをビルドし、前回(上記)のベンチマークのcuDNN v5.0 for CUDA7.5における性能と比較しました。
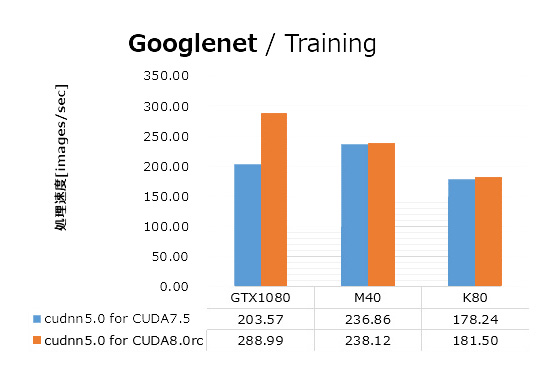
Googlenetでは、GTX 1080が、前回のベンチマークよりも40%処理速度が向上し、M40を追い抜き、M40と比較して20%ほど速い結果となりました。
AlexNetのベンチマークでは、目立った変化はありませんでした。前回も言及したように、AlexNetではGPU上のメモリ帯域幅がボトルネックとなっていると考えられるため、ソフトウェアの変更に関わらず性能に大きな変化が無いのは妥当と言えます。
今回も前回の結果と同様に、Googlenetのベンチマーク中、GPU負荷率は100%に張り付いていました。GPU演算処理が速度のボトルネックとなっていると推察されるGooglenetにおいて、Maxwell、KeplerアーキテクチャーGPUで処理速度に目立った変化が無いにも関わらず、PascalアーキテクチャーGPUの処理速度が大きく改善したことから、cuDNN v5.0 for CUDA 8.0rcは、特にPascalアーキテクチャー向けのチューニングが施されていると推察されます。
まとめると、cuDNNのアップデートにより、GTX 1080での処理速度が向上し、前世代よりも速い結果となりました。

注記事項
※掲載されている情報は発表日時点のものです。閲覧時点では情報が異なっている場合がございます。
※NVIDIA® GeForce® GTX シリーズは、これから Deep Laerning を始める方に適したコンシューマ向け製品です。研究開発現場での運用には、24時間連続稼働を想定したプロフェッショナル向け製品であるNVIDIA® Tesla® シリーズの導入を推奨いたします。
関連リンク



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)