
NVIDIA DGX Series
完全無欠な AI プラットフォーム NVIDIA DGX H200

エンタープライズ AI 向けの、世界で実証された選択
NVIDIA H200 GPU x8、合計 GPU メモリ 1,128GB
GPU あたり 18 NVIDIA® NVLinks®、GPU 間の双方向帯域幅 900GB/秒NVIDIA NVSWITCHES™ x4
7.2 テラバイト/秒の GPU 間双方向帯域幅 、前世代比 1.5 倍以上NVIDIA CONNECTX®-7 x10 および、NVIDIA BLUEFIELD® DPU 400Gb/秒 ネットワーク インターフェイスx2
ピーク時の双方向ネットワーク帯域幅 1TB/秒デュアル Intel Xeon Platinum 8480C プロセッサ、合計 112 個のコア、2TB システム メモリ
H100から大幅に増量したメモリ、AI への依存が非常に高い仕事を可能にするパワフルな CPU30TB NVMe SSD
最高のパフォーマンスを実現するための高速ストレージ 製品概要
製品概要
NVIDIA DGX H200システムは、大規模言語モデル、レコメンダー システム、ヘルスケア研究および気候科学に必要とされる、膨大な演算性能要件に対応できるスケールを備えています。1 台のシステムには8 基の NVIDIA H200 GPU が搭載され、これらの GPU が NVIDIA NVLink® で 1 つに接続されています。DGX H200 アーキテクチャでは、32 petaFLOPS の AI パフォーマンス、前世代と比較して2 倍の速度になったネットワーク、高速のスケーラビリティを利用可能。生成 AI、自然言語処理、ディープラーニングによるレコメンデーション モデルなどの大規模なワークロードに対応できるよう強化されています。
DGX H200は、オンプレミス、コロケーション、マネージド サービス プロバイダーからのレンタルなど様々な環境で利用可能です。
 主な特長
主な特長
卓越したAIセンターを構築
DGX H200 は、NVIDIA Base Command™ や NVIDIA AI Enterprise ソフトウェア スイートが含まれた、完全統合型のハードウェア/ソフトウェア ソリューションです。

画期的なAIスケーリング
DGX H200 アーキテクチャでは、32 petaFLOPS の AI パフォーマンスや、前世代と比較して2 倍の速度になったネットワーク、高速スケーラビリティを利用可能。生成 AI、自然言語処理、ディープラーニングによるレコメンデーション モデルなどの様々な大規模なワークロードに対応できるように強化されています。
最先端のインフラを利用可能
Llama 2 70Bの事前トレーニングとSFTが最大4.2倍高速化
Llama 2 は、Meta が開発した人気の高いオープンソースの大規模言語モデルです。NeMo の今後のリリースには、Llama 2 のパフォーマンスを向上させる多くの改善が含まれています。A100 GPU で実行される以前の NeMo リリースと比較して、H200 GPU で実行される今後の NeMo リリースでは、Llama 2 の事前トレーニングと、教師ありファインチューニング (SFT : Supervised Fine-Tuning) のパフォーマンスが最大 4.2 倍高速化 * されます。
最初の改善点は、モデル オプティマイザーの状態の混合精度実装の追加です。これにより、モデル容量要件が削減され、モデル状態とやり取りする操作の有効メモリ帯域幅が 1.8 倍向上します。
最近の多くの LLM アーキテクチャで採用されている最先端のアルゴリズムである回転位置埋め込み (RoPE) 操作のパフォーマンスも向上しました。さらに、最新の LLM でガウス誤差線形ユニット (GELU) の代わりに使用されることが多い Swish-Gated Linear Unit (SwiGLU) アクティベーション関数のパフォーマンスが最適化されています。
最後に、テンソル並列処理の通信効率が大幅に向上し、パイプライン並列処理の通信チャンク サイズが調整されました。
これらの改善により、NVIDIA Hopper アーキテクチャに基づく GPU での Tensor Core の使用率が劇的に向上し、Llama 2 70B 事前トレーニングと教師あり微調整で H200 GPU あたり最大 836 TFLOPS を達成しました。
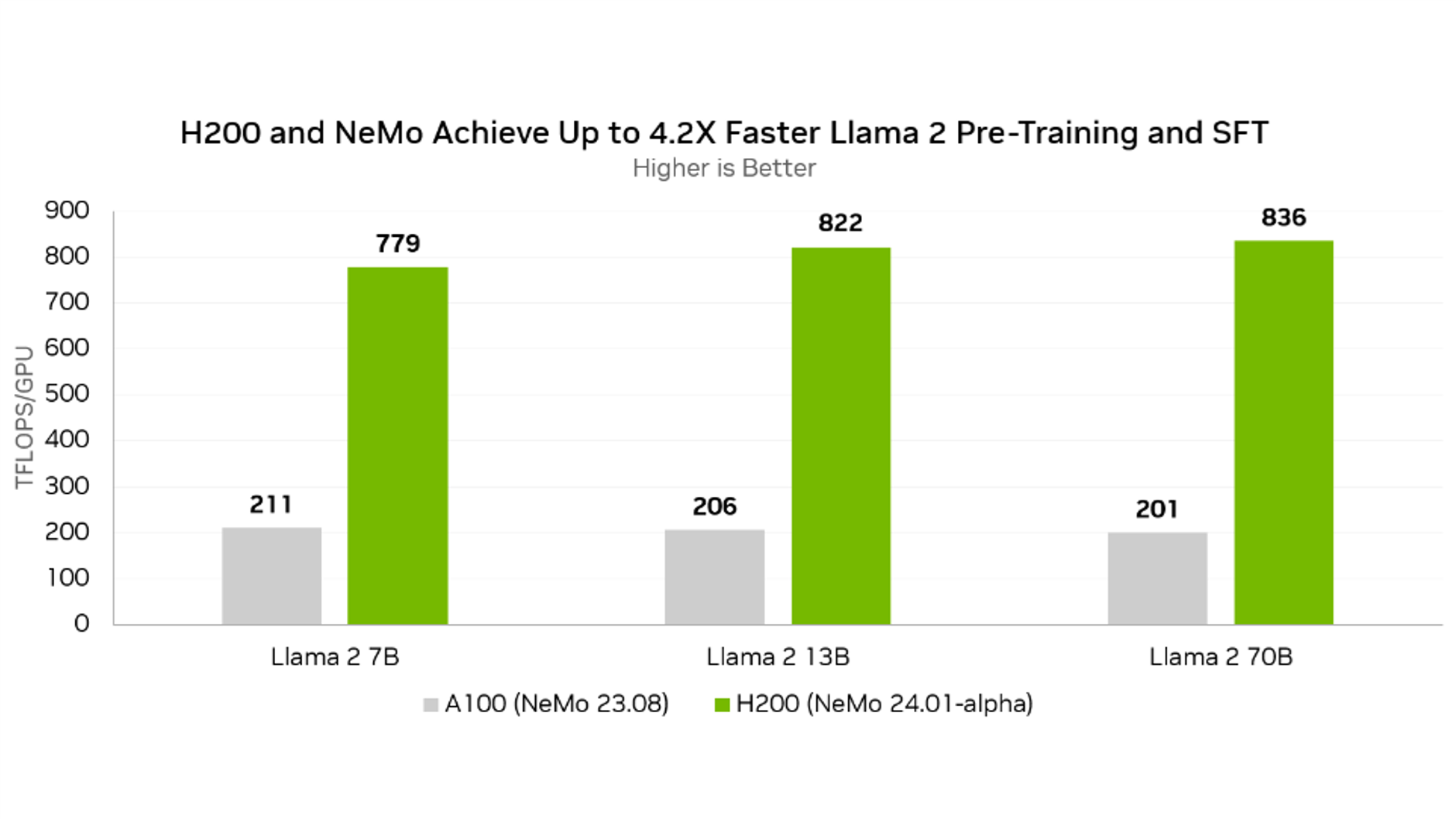
*次期 NeMo リリースを使用した H200 上の Llama 2 (7B/13B/70B) でのトレーニング 性能 (GPU あたりのモデル TFLOPS) と、以前の NeMo リリースを使用した A100 の性能の比較です。
[GPU あたりの測定パフォーマンス]
グローバル バッチ サイズ = 128
Llama 2 7B: シーケンス長 4096 | A100 8x GPU、NeMo 23.08 | H200 8x GPU、NeMo 24.01-alpha
Llama 2 13B: シーケンス長 4096 | A100 8x GPU、NeMo 23.08 | H200 8x GPU、NeMo 24.01-alpha
Llama 2 70B: シーケンス長 4096 | A100 32x GPU、NeMo 23.08 | H200 8x GPU、NeMo 24.01- -alpha
H200 GPU を NeMo の次期バージョンと組み合わせると、卓越した Llama 2 トレーニング スループットを実現でき、以前の NeMo リリースを実行する A100 GPU と比較して最大 4.2 倍の向上が実現します。
| Training Tokens/Sec/GPU | Llama 2 7B | Llama 2 13B | Llama 2 70B |
|---|---|---|---|
| H200 (Latest NeMo) | 16,913 | 9,432 | 1,880 |
| A100 (Prior NeMo) | 4,583 | 2,357 | 451 |
| Speedup | 3.7X | 4.0X | 4.2X |
 仕様・スペック
仕様・スペック
DGX H200
| SYSTEM | NVIDIA DGX H200 |
| GPU | 8x NVIDIA H200 Tensor Core GPUs(メモリ141GB/1GPU) |
| GPU memory | 1,128GB total |
| Performance | 32 petaFLOPS FP8 |
| NVIDIA® NVSwitch™ | 4 x |
| System power usage | ~10.2kW max |
| CPU | Dual Intel® Xeon® Platinum 8480C Processors 112 Cores total, 2.00 GHz (Base), 3.80 GHz (Max Boost) |
| System memory | 2TB |
| Cluster Network | 4 x OSFP ports (各 OSFPポートは NVIDIA ConnectX-7s (400Gb/s InfiniBand/Ethernet) 2ポートに接続) |
| Storage Network | 2 x dual-port NVIDIA ConnectX-7 (400Gb/s InfiniBand/Ethernet) |
| Management Network | 10Gb/s onboard NIC with RJ45 100Gb/s Ethernet NIC Host baseboard management controller (BMC) with RJ45 |
| Storage | OS: 2x 1.9TB NVMe M.2 Internal storage: 8x 3.84TB NVMe U.2 |
| System software | NVIDIA AI Enterprise – Optimized AI software NVIDIA Base Command – Orchestration, scheduling, and cluster management DGX OS / Ubuntu / Red Hat Enterprise Linux / Rocky – Operating System |
| System weight | 130.45kg |
| Packaged system weight | 170.45kg |
| System dimensions | Height: 14.0in (356mm) Width: 19.0in (482.2mm) Length: 35.3in (897.1mm) |
| Operating temperature range | 5–30°C (41–86°F) |
NVIDIA Partner Network(NPN)に認定されました
HPCシステムズは、NVIDIA社のパートナー認定制度 “NVIDIA Partner Network (NPN)” において、「DGX AI Compute System」 「Networking」 「Compute」 の3つのコンピテンシーで最上位レベルのELITE PARTNER に認定されています。
HPC システムズは、Solution Provider と Solutions Integration Partner の二つのパートナーカテゴリーをカバーする製品知識と、長年培ってきた高度な HPC-AI システムインテグレーション技術を掛け合わせることで、お客様の研究・開発の加速化、効率化に対する最適解を提供してまいります。
※ NVIDIA パートナー ネットワーク (NPN) は、NVIDIA が展開するパートナープログラムです。 2024年7月現在、日本国内の企業が約80社加入しています。 NVIDIA パートナー ネットワーク (NPN) は、13種類のパートナーのタイプと、11種類のコンピテンシーで構成されています。
ご参考: NVIDIA パートナー ネットワーク (NPN)
お問い合わせ
お客様に最適な製品をご提案いたします。まずはお気軽にお問い合わせください。
03-5446-5531
平日9:00~18:00(土・日・祝日は除きます)
※土曜日、日曜日、祝日、年末年始は、休日とさせていただきます。