
技術情報
インテル® Xeon® プロセッサー E5-2600 v4 ファミリー ベンチマーク結果
第5世代 Intel Core アーキテクチャのサーバ向けプロセッサー Intel Xeon E5-2600 v4 ファミリーがリリースされました。前E5-2600 v3 ファミリーのHaswellマイクロアーキテクチャを継承し、DDR4規格の2400MHzメモリに新たに対応したほか、14nm製造プロセスによって1CPUで最大22コア搭載までコア数ラインアップが拡充されたモデルになります。E5-2600 v3 ファミリーと比べて、浮動小数点乗算のレイテンシが5から3サイクルへ高速化、L2 TLBのエントリ数が1Kから1.5Kへ拡大、TLBミスを処理するハードウェアの増設といった改良がなされ、IPC(Instruction per Clock、1クロックあたりの実行命令数)の性能向上にも期待が持てるハードウェアに成長しています。
Intel Xeon E5-2600 v4 ファミリーの性能を調査するため、E5-2699 v4と旧ファミリーのE5-2698v3を搭載した2-wayマシンで各アプリケーションのベンチマークを実施して実効性能を比較しました。ベンチマークで使用した検証環境は次表のとおりです。E5-2699 v4の検証環境では、複数ノードでのスケーラビリティを見るべく2ノードをInfiniBand FDR 56Gbpsで接続しています。
| CPU | Intel Xeon E5-2699 v4 | Intel Xeon E5-2698 v3 |
|---|---|---|
| アーキテクチャ | 第5世代 Intel Coreプロセッサー | 第4世代 Intel Coreプロセッサー |
| CPUクロック | 2.2GHz | 2.3GHz |
| AVX時CPUクロック | 1.8Hz | 1.9GHz |
| CPUコア数 | 22core | 16core |
| CPUキャッシュ | 55MB | 40MB |
| 対応メモリ規格 | DDR4 | DDR4 |
| 対応メモリFSB | 2400MHz | 2133MHz |
| 理論性能 | 633.6 GFlops ( = 1.8GHz × 22core × 16 ) | 486.4 GFlops ( = 1.9GHz × 16core × 16 ) |
| CPU | Intel Xeon E5-2699 v4 × 2CPU (計44core) | Intel Xeon E5-2698 v3 × 2CPU (計32core) |
|---|---|---|
| メモリ | DDR4 256GB 2133MHz | DDR4 128GB 2133MHz |
| HDD | 1TB SATA600 7200rpm | |
| OS | CentOS 6.5 x86_64 | |
| コンパイラ | Intel Compiler 15.0.5 | |
| MPI | OpenMPI 1.8.8 | |
| ノード数 | 2 | |
| インターコネクト | InfiniBand FDR 56Gbps | |
HPL
HPLはスーパーコンピュータの性能ランキング『Top 500 Supercomputer Sites』で用いられているベンチマークプログラムです。連立方程式の解を求めるプログラムで、浮動小数点演算の性能をFLOPS単位、つまり1秒間に処理できる浮動小数点演算命令の数で性能を評価します。HPLでCPUの実効性能を計測し、理論性能どおりの実効性能の向上があるかを調査しました。
HPLはIntel ComposerでAVX2とAVXのCPU最適化オプションを有効にしてビルドしたものでベンチマークを実施しました。このHPL結果では1ノードのみでのピーク時の実効性能を記載しています。結果は以下図の通りとなりました。比較対象は2014年9月に掲載したE5-2697 v3の性能としています。
- HPL 2.1
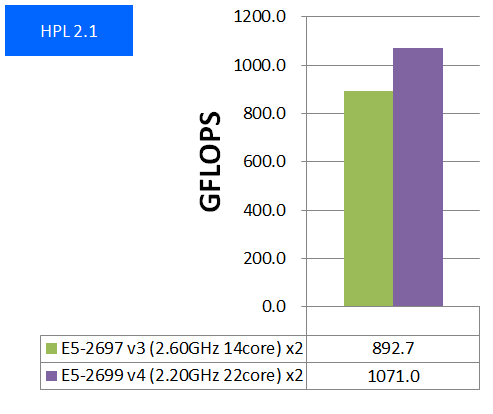
特長:1ノード2CPUで1TFLOPSに到達
1ノードでのCPUコア総数が44となり、並列性能スケーラビリティが良好なHPLにおいて、1ノード2CPUでついに1TFLOPSを超える性能を達成しました。Haswellマイクロアーキテクチャで追加されたAVX2やFMAの効果がE5-2600 v3と同様に大きく現れたと言えます。実効性能では最大でここまで出せるという一つの目安として捉えていただければと思います。
Amber14
Amberは生体分子シミュレーションソフトウェアのひとつです。Intel ComposerのAVX2とAVXのCPU最適化を有効にしてビルドをしたものでベンチマークを行いました。
> AmberのpmemdのGPU版公式サイトで配布されている408,000原子のCellulose NVEのインプットと、25,095原子のNucleosome GBのインプットを、pmemdで計算したときの経過時間を測定しました。4~44並列は1ノードでの経過時間を、64並列・88並列については2ノード並列での経過時間を記載しています。
- ① Cellulose NVE
- ② Nucleosome GB
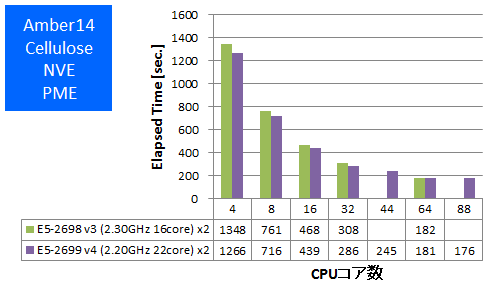
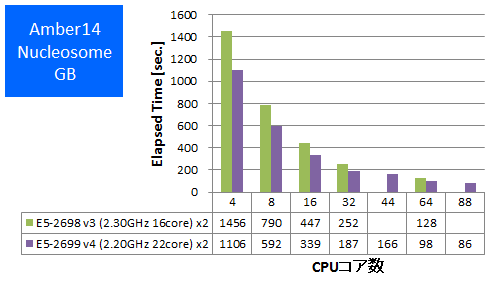
特長:2ノード88並列まで順調に性能向上、GB計算が特に高速化
従来のAmberベンチマークと同様に、増えたコア数分、並列数を大きくすると、並列性能がスケールすることが確認できました。CPUコア数の多いCPUを選択することが推奨されます。
注目すべきことに、同並列数で比較して、E5-2698 v3よりE5-2699 v4が速い結果となりました。TurboBoostを考慮したCPUクロック最大値は、4, 8, 16コア使用時のいずれにおいてもE5-2698 v3よりE5-2699 v4の方が低いです。つまりクロック差を上回る速度向上がE5-2699 v4で得られています。速度向上の要因として、E5-2600 v3のマイクロアーキテクチャに比べて、E5-2600 v4のマイクロアーキテクチャにIPCを向上させる類の改良を加えられていることが挙げられます。
E5-2698 v3とE5-2699 v4の速度差は、Cellulose NVE PMEでは1~8%程度ですが、Nucleosome GBではなんと31~35%程度もあります。GB計算で大きく速度差が見られたことについては、後述のVASPで、512原子PAW GGA計算よりも計算負荷の大きな40原子DFT: PAW PBE計算の方で大きな速度差が出た傾向が、PMEとGBという計算条件・計算手法の違いにおいても起こり、VASPよりもステップ数と計算対象が格段に多い分子動力学計算において、より顕著に表れたのではないかと推測しています。
Gaussian 09
量子化学計算のデファクトスタンダードであるGaussianでのベンチマークを行いました。使用したGaussianは、SSE4に最適化されたGaussian社標準のBinary版パッケージ、そしてAVXに最適化された同パッケージです(AVX2は未対応です)。
Gaussianパッケージに付属のtest0397に加えて、分子数や基底関数数の異なるいくつかのDFT計算について実行時間を比較しました。比較するE5-2600 v3ファミリーとしては2014年9月に掲載したE5-2697 v3の性能を用いています(SSE4に最適化されたGaussian09 Rev. D.01を使用したものです)。E5-2699 v4ではGaussian09 Rev. E.01のSSE4版とAVX版についてそれぞれ取得しました。AVX版の効果もあわせてご覧ください。
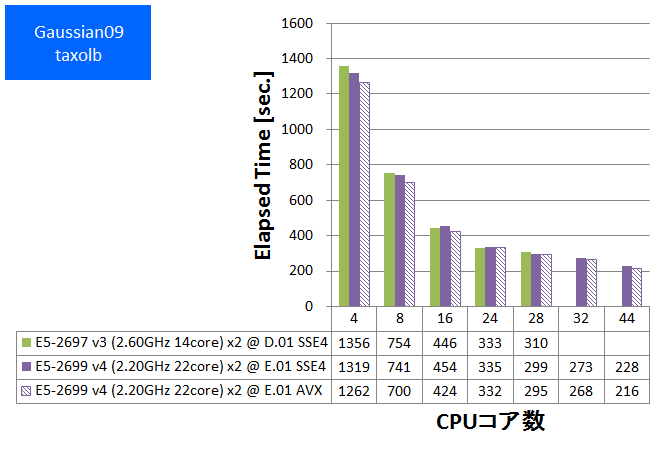
- ① taxolb (基底関数数:1123, SP, RB3LYP/6-31G(D,P))
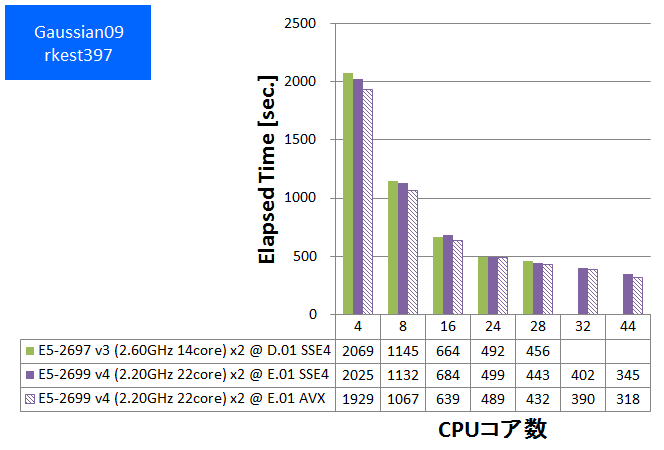
- ② rkest (基底関数数:1620, SP ,RB3LYP/6-31G(D,P))
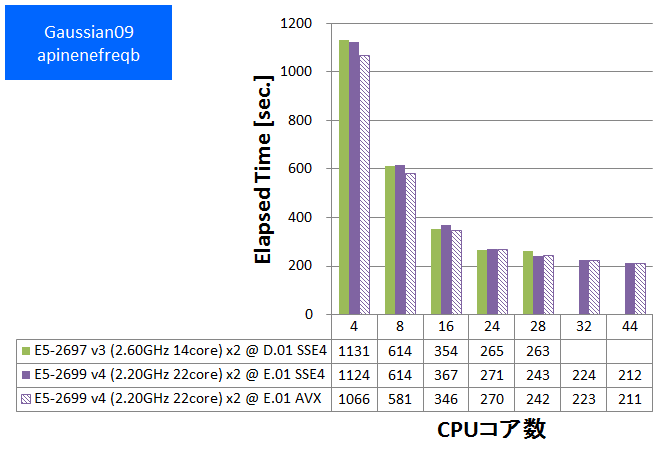
- ③ apinenefreqb (基底関数数:346, FREQ, RB3LYP/6-311G(DF,P))
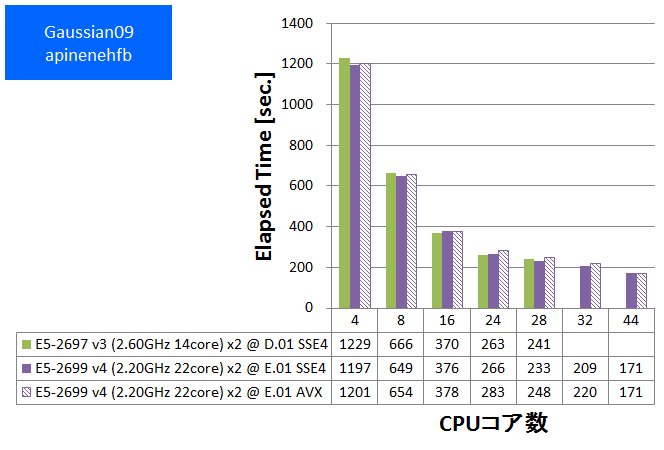
- ④ apinehfb (基底関数数:678 ,SP ,HF/6-311++G(3DF,3PD))
- ⑤ apinedftb (基底関数数:678, SP, B3LYP/6-311++G(3DF,3PD))
- ⑥ test0397 (基底関数数:882, SP, RB3LYP/3-21G ) (Gaussian09パッケージ付属)
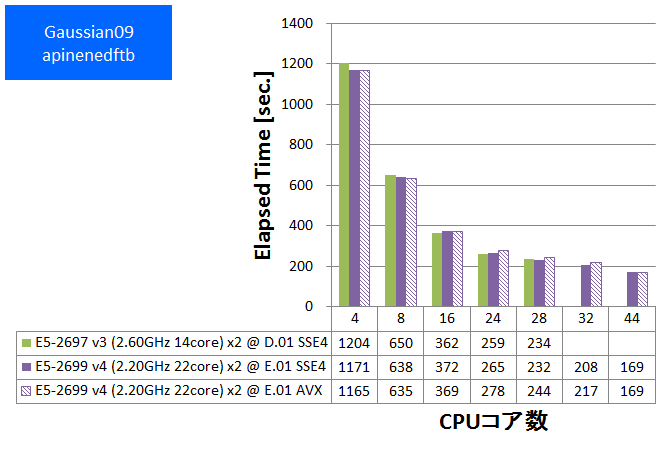
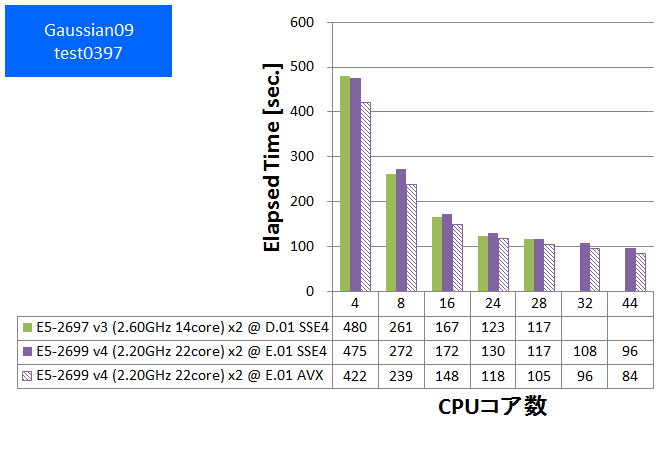
特長:44スレッド並列まで順調な性能向上を発揮
HPLと同様に、CPUバウンドな性質が度々観察されてきたGaussianでは、スレッド並列数を44に増やしても順調な性能向上が得られました。CPUコア数に注目したハードウェア構成が望ましいと言えます。
Gaussian09 Rev. E.01で新たに提供されるようになったAVX版は、SSE4版に比べて数%~10%速い傾向が見られました。ただし今回のベンチマークでは基底関数数が小さい系で加速効果が小さい傾向も見られました。これはSIMD演算の効く行列演算のボリュームに起因すると推測されます。SSE4版・AVX版の選択においては基底関数数を含めた注意深い検討が望ましいと言えます。
複数ジョブ同時実行
逐次計算、あるいは小さな並列数で計算を実行すべき状況では、同時に数多くの計算を高スループットにこなす能力がCPUに求められます。HPLとVASPについて、同一の計算ジョブを同時に複数実行し、プロセス数が増えた時の性能劣化率(1プロセス実行時を100%とします)を測定しました。HPLではGFLOPSを、VASPでは経過時間を記していますので良悪の捉え方が逆となる点にご注意ください。
- ① 同時実行:HPL 2.1
- ② 同時実行:VASP (64原子 PAW_GGA)
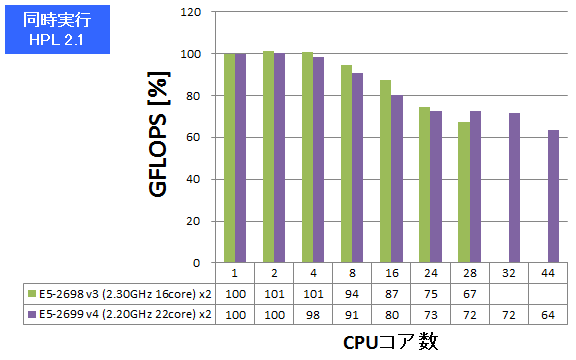
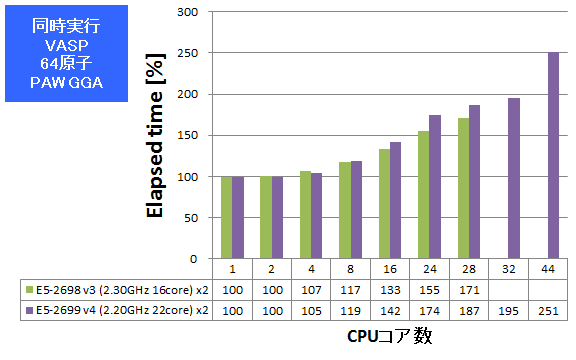
特長:ジョブ数が多くとも同時実行を苦にしないスループット
E5-2698 v3とほぼ同様の性能劣化率で複数ジョブをこなせている傾向が見られました。同時実行における性能劣化率を考慮して仮にVASP 64原子PAW GGAのジョブを1024個完了させるケースを仮定すると、所要時間の比は、32ジョブ時で(1024÷32)×195%=62.4、44ジョブ時で(1024÷44)×251%=60.24となり、44ジョブまで同時実行させても全体スループットを向上できると算出できます。まさに増えたコアを有効活用するのに適したCPUとなっていると言えます。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)