
技術情報
インテル® Xeon® E5-2600 v3 ファミリー ベンチマーク結果
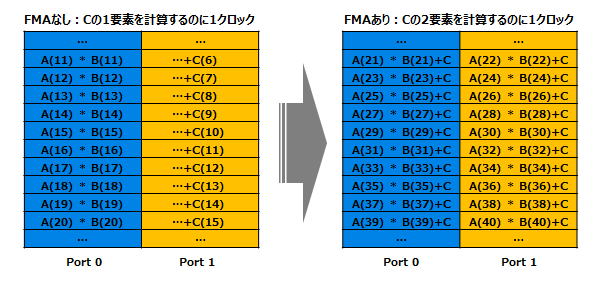
第4世代 Intel Core アーキテクチャのサーバ向けプロセッサー Intel Xeon E5-2600 v3 ファミリーがリリースされました。主な特徴はQPIリンク速度等のCPU性能が向上し、DDR4規格のメモリに対応したほか、2-wayモデルのプロセッサーでは初のAVX2 (Advanced Vector Extensions 2) が搭載されたモデルになります。積和算命令FMAの導入により浮動小数点演算性能が前世代から倍増しており、この機能を用いることでCPUの理論性能が前世代の2倍になります。科学技術計算用途では積和演算が重要となる行列演算が多用されるため、大幅な性能向上が見込めます。
Intel Xeon E5-2600 v3 ファミリーの性能を調査するため、E5-2697 v3と旧ファミリーのE5-2697 v2を搭載した2-wayマシンで各アプリケーションのベンチマークを実施して実効性能を比較しました。ベンチマークで使用した検証環境は次表のとおりです。
| CPU | Intel Xeon E5-2697 v3 | Intel Xeon E5-2697 v2 |
|---|---|---|
| アーキテクチャ | 第4世代Intel Coreプロセッサー | 第3世代Intel Coreプロセッサー |
| CPUクロック | 2.6GHz | 2.7GHz |
| AVX時CPUクロック | 2.2GHz | (同上) |
| CPUコア数 | 14core | 12core |
| CPUキャッシュ | 35MB | 30MB |
| 対応メモリ規格 | DDR4 | DDR3 |
| 対応メモリFSB | 2133 MHz | 1866 MHz |
| 理論性能 | 492.8 GFlops ( = 2.2GHz * 14core * 16 ) | 259.2 Gflops ( = 2.7GHz * 12core * 8 ) |
| CPU | Intel Xeon E5-2697v3 * 2CPU (計28core) | Intel Xeon E5-2697v2 * 2CPU (計24core) |
|---|---|---|
| メモリ | DDR4 128GB 2133MHz | DDR3 128GB 1866MHz |
| HDD | 2TB SATA600 7200rpm | 2TB SATA600 7200rpm |
| OS | CentOS 6.4 x86_64 | CentOS 6.4 x86_64 |
| コンパイラ | Intel Compiler 15.0.0.016 (Beta版) | Intel Compiler 13.1.3.192 |
| MPI | Intel MPI 4.1.3.048 | Intel MPI 4.1.3.048 |
HPL
HPLはスーパーコンピュータの性能ランキング『Top 500 Supercomputer Sites』で用いられているベンチマークプログラムです。連立方程式の解を求めるプログラムで、浮動小数点演算の性能をFLOPS単位、つまり1秒間に処理できる浮動小数点演算命令の数で性能を評価します。HPLでCPUの実効性能を計測し、理論性能どおりの実効性能の向上があるかを調査しました。 HPLはIntel ComposerでAVX2とAVXのCPU最適化オプションを有効にしてビルドしたものでベンチマークを実施しました。結果は以下図の通りとなりました。
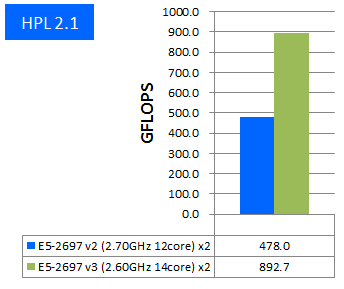
特長:1ノード当り1.85倍の実効性能に到達
1ノード当りの性能差が1.85倍という驚異的な実効性能が見られました。新しく追加されたAVX2やFMAの効果が非常に大きく現れたと言えます。
理論性能と実効性能の比で見るとE5-2697v2が92%に対してE5-2697v3では90%であり、従来どおり、HPLではCPUの理論性能がほぼそのまま実効性能として表れています。CPUボトルネックとなるプログラムについて、実効性能では最大でここまで出せるという一つの目安として捉えていただければと思います。
Amber12
Amberは生体分子シミュレーションソフトウェアのひとつです。Intel ComposerのAVX2とAVXのCPU最適化を有効にしてビルドをしたものでベンチマークを行いました。Amber公式サイトで配布されている408,000原子のCellulose NVEのインプットをpmemdで計算したときの経過時間を測定しました。
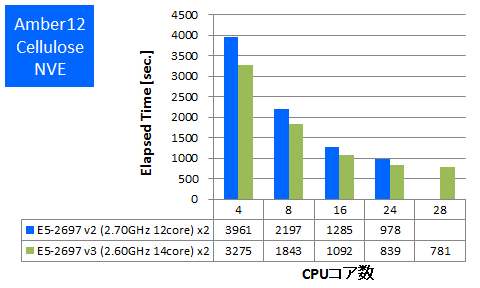
特長:1ノード当り1.25倍の性能向上
同時並列数で1.2倍、1ノード当りでは1.25倍ほどの性能向上がありました。また並列数が24コアから28コアに増えても性能の向上があることが確認できました。Amberは以前のベンチマークでもCPUの最適化オプションの効果が現れにくい傾向があり、HPLの実効性能ほどの大幅な伸びはありませんでした。それでも今回の結果からは大きな効果があると考えることができます。
VASP
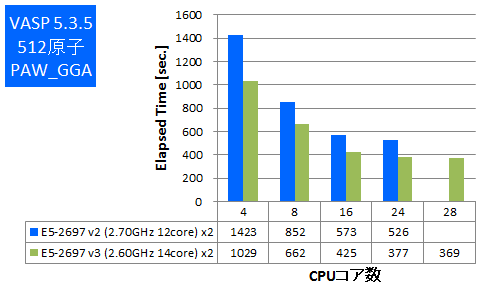
VASPは密度汎関数法による平面波・擬ポテンシャル基底を用いた第一原理電子状態計算プログラムパッケージです。このプログラムは並列実行時にCPU-メモリ間帯域を多く使用する傾向があります。 今回はIntel ComposerでAVX2とAVXのCPU最適化を有効にしてビルドをしたものでベンチマークを実施しました。512原子と1000原子でのPAW GGA計算とUSPP計算を行い、実行時間の比較をしました。
- ① 512原子 PAW_GGA
- ② 512原子 USPP
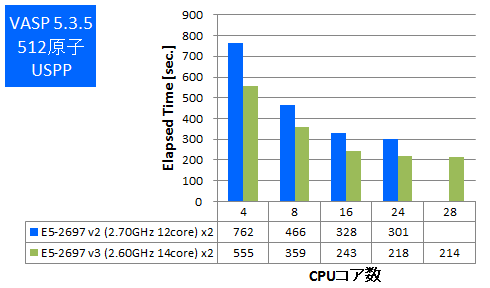
- ③ 1000原子PAW_GGA
- ④ 1000原子USPP
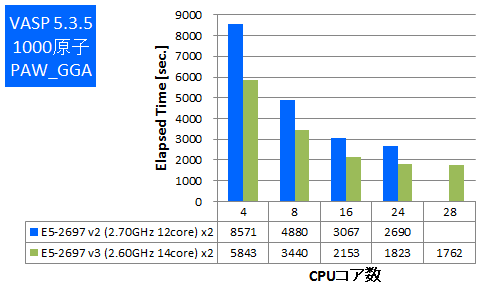
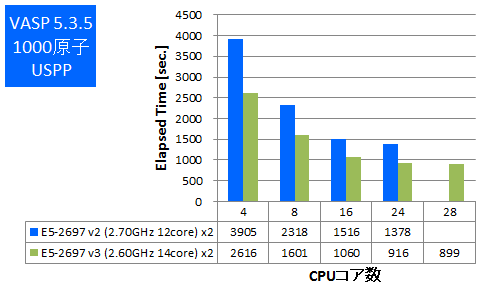
特長:最大で1.5倍の実効性能の向上
同時並列数で比較すると1.3倍~1.5倍の実効性能の向上がありました。この結果からは新しいCPUアーキテクチャの効果が表れていると言えます。ただし、多数のコアを使用したときは性能劣化が顕著になり、コア数を増やしても実効性能が伸びていません。この結果は上述のCPU-メモリ間帯域がボトルネックとして現れており、以前のモデルのCPUからも同様の傾向があります。このような傾向のアプリケーションではCPUコア数よりもCPUクロックの高いものほうが費用対効果が高いと考えられます。
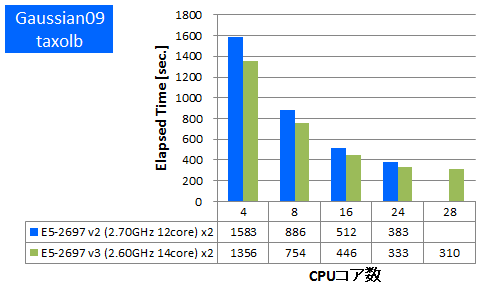
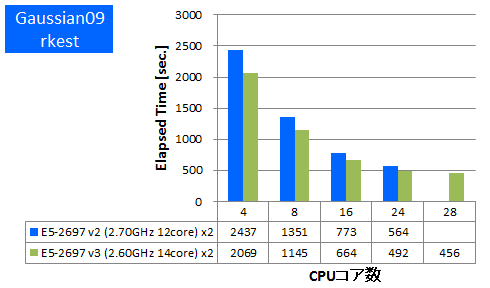
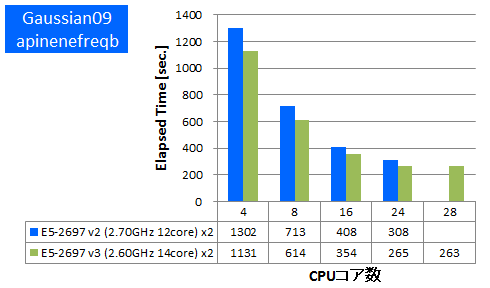
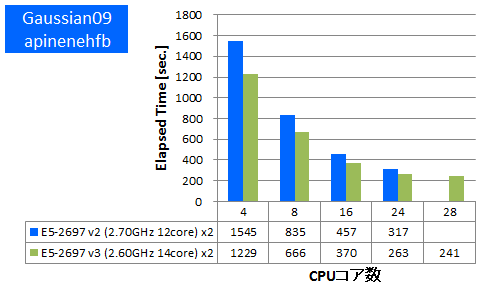
Gaussian 09 ※AVX,AVX2未対応
量子化学計算のデファクトスタンダードであるGaussianでのベンチマークを行いました。今回使用したものはSSE4に最適化されたGaussian社標準のBinary版パッケージでAVX2やAVXは未対応のものになります。Gaussianパッケージに付属のtest0397に加えて、分子数や基底関数数の異なるいくつかのDFT計算について実行時間を比較しました。
- ① taxolb (基底関数数:1123, SP, RB3LYP/6-31G(D,P))
- ② rkest (基底関数数:1620, SP ,RB3LYP/6-31G(D,P))
- ③ apinenefreqb (基底関数数:346, FREQ, RB3LYP/6-311G(DF,P))
- ④ apinehfb (基底関数数:678 ,SP ,HF/6-311++G(3DF,3PD))
- ⑤ apinedftb (基底関数数:678, SP, B3LYP/6-311++G(3DF,3PD))
- ⑥ test0397 (基底関数数:882, SP, RB3LYP/3-21G ) (Gaussian09パッケージ付属)
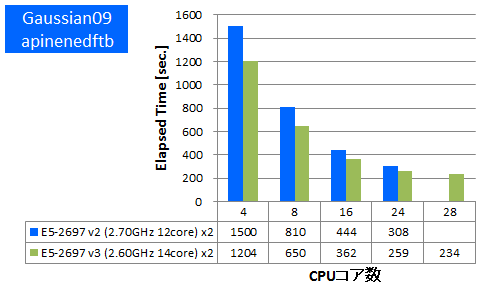
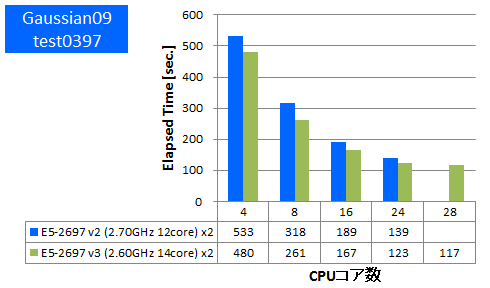
特長:AVX,AVX2非対応バイナリでも1.15倍以上の性能向上を達成
1ノードあたり1.15倍~1.3倍の実効性能が向上しました。AVX2やAVXの最適化がされていないため他のアプリケーションほどの向上はありませんでしたが、それでもCPUの命令発行ポートの増加等によりCPUの基本的な処理性能は上がったと考えられます。この結果よりAVX2やAVXに未対応のアプリケーションでも少なからず実効性能が上がることがわかりました。
複数ジョブ同時実行
逐次計算、あるいは小さな並列数で計算を実行すべき状況では、同時に数多くの計算を高スループットにこなす能力がCPUに求められます。HPL、VASPについて、同一の計算ジョブを同時に複数実行し、プロセス数が増えた時の性能劣化率(1プロセス実行時を100%とします)を測定しました。HPLではGFLOPSを、VASPでは経過時間を記していますので良悪の捉え方が逆となる点にご注意ください。
| CPU | Xeon E5-2667 v2 (3.30GHz, 8コア, 25MB Cache, 8GT/s Intel QPI, TDP130W) | Xeon E5-2697 v2 (2.70GHz, 12コア, 30MB Cache, 8GT/s Intel QPI, TDP130W) | Xeon E5-2697 v3 (2.60GHz, 14コア, 35MB Cache, 9.6GT/s Intel QPI, TDP145W) |
|---|---|---|---|
| CPU数 | 2 (計16コア) | 2 (計24コア) | 2 (計28コア) |
| 理論性能 | 422.4GFLOPS | 518.4GFLOPS | 985.6GFLOPS |
| メモリ | 128GB DDR3 1866MHz | 128GB DDR3 1866MHz | 128GB DDR4 2133MHz |
| OS | CentOS 6.4 | CentOS 6.4 | CentOS 6.5 |
| インテル コンパイラー | 13.1 | 13.1 | 13.1 |
| MPI | OpenMPI 1.6.5 | OpenMPI 1.6.5 | OpenMPI 1.6.5 |
| HPL | 2.1 | 2.1 | 2.1 |
| VASP | 5.3.3 22May2013 | 5.3.3 22May2013 | 5.3.5 |
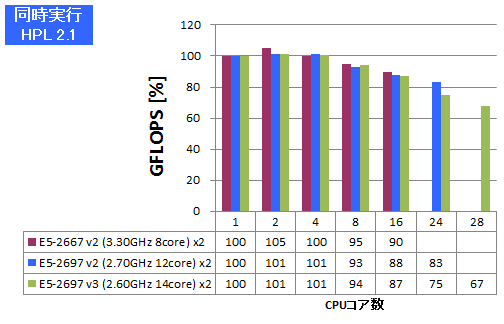
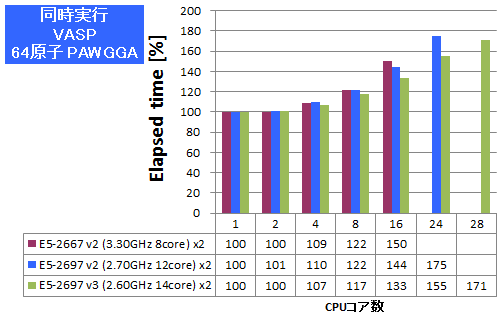
特長:Sandy Bridgeマイクロアーキテクチャを上回る堅持さを達成
HPLでは、E5-2697 v3 の16ジョブ投入時の性能劣化率が、E5-2667 v2・E5-2697 v2のコア数分ジョブ投入時の劣化率とほぼ同じとなっており、ここまではSandy Bridgeマイクロアーキテクチャの堅持さが維持されていると言えます。24ジョブ投入時ではE5-2697 v2と比べて陰りが見られ、28ジョブでは67%までジョブ性能が落ちていますが、Sandy Bridgeに比べて2倍のCPU理論性能向上・1.14倍のメモリ性能向上というCPU性能発揮には厳しい条件となった中、この程度の性能劣化率に留めているのは高く評価できます。
VASPでは、全並列数においてE5-2667 v2・E5-2697 v2よりも性能劣化率が低く抑えられており、Sandy Bridgeマイクロアーキテクチャを上回る堅持さを達成しています。Haswellマイクロアーキテクチャで追加された命令発行ポートによってIPC(Instruction-per-Cycle)が向上したことが、多数のジョブを同時に捌くのに功を奏したと考えられます。搭載コア数が増えたインテル® Xeon プロセッサー E5-2600 v3 ファミリーCPUを複数ジョブで稼働率高く運用できる裏付けとなる結果と言えます。
インテル® Xeon® E5-2600 v3 ファミリー 搭載製品「XHシリーズ」
・Intel、インテル、Intelロゴ、Xeon、Xeon Inside は、米国およびその他の国におけるIntel Corporationの商標です。
・NVIDIA、NVIDIAロゴ、CUDAは、米国及びその他の国におけるNVIDIA Corporationの商標または登録商標です。
・その他、記載されている会社名、製品名、サービス名等は、各社の商標または登録商標です。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)