
技術情報
NVIDIA® Tesla® K40 vs. インテル® Xeon Phi™ 7120P 粒子法ベンチマーク結果
SPH 法を基本とした粒子法の流体計算の、OpenCL による実装で Tesla および Xeon Phi の性能評価を行いました。
実装
SPH 法の重み関数には、以下の Gauss 関数を使いました。
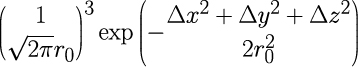
また、Boyle の法則で計算した圧力によって発生する粒子同士の相互作用に対しては、体積が前ステップより増加している場合にのみ引力として計算する(体積が前ステップから減少している場合は規定の体積より大きくても斥力として計算する)という補正を入れて計算します。
ベンチマーク環境
| 製品 | HPC5000-XIGPU4TS-KPL |
|---|---|
| CPU | Intel Xeon E5-2687W (8 cores, 3.1 GHz) × 2 |
| GPU アクセラレータ | NVIDIA Tesla K40 |
| MIC アクセラレータ | Intel Xeon Phi 7120P |
| OS | CentOS 6.4 |
| CUDA Toolkit | 6.0 |
| NVIDIA Driver | 331.62 |
| Manycore Platform Software Stack | 3.2.1 |
| Intel SDK for OpenCL Applications | XE 2013 R3 |
ベンチマーク結果
粒子の数を変えながら 10 ステップのシミュレーションを実行し、その速度を測定しました。また、LTPVを使ったプロファイルも行い、より詳細なデータも採取しました。
| 32×32× 32 = 32768 粒子 | 64×64× 64 = 262144 粒子 | 128×128×128 = 2097152 粒子 | ||||
| Tesla K40 | Xeon Phi 7120P | Tesla K40 | Xeon Phi 7120P | Tesla K40 | Xeon Phi 7120P | |
| 密度計算(s): | 0.567149 | 0.515777 | 22.85468 | 25.09974 | 1361.479 | 1610.943 |
| 圧力計算(s): | 1.157075 | 1.725624 | 61.3456 | 172.5543 | 3562.323 | 15328.74 |
| 座標計算(s): | 0.000115 | 0.005377 | 0.000916 | 0.039082 | 0.006952 | 0.047984 |
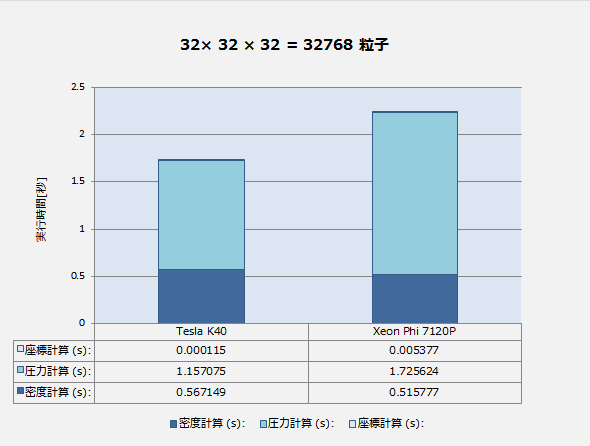
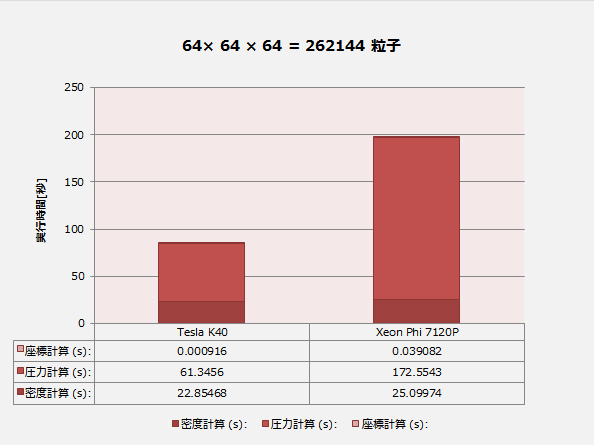
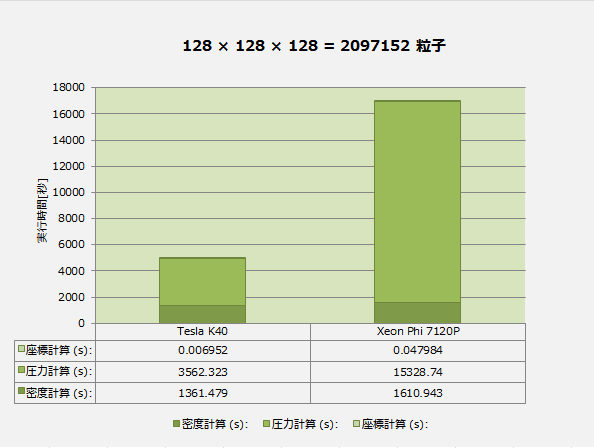
問題サイズが小さいときは Xeon Phi の性能が Tesla に迫ります。サイズが大きくなるとXeon Phi は性能が急速に劣化しますが、Teslaは理論通りの O(N2) に近いスケーラビリティを保ちます。処理内容が比較的単純な密度計算は Xeon Phi でも理論通りにスケーラブルですが、複雑度が増す圧力計算の性能劣化が Tesla に比べて Xeon Phi で大きくなっており、「単純なタスクに強いがタスクが複雑になると性能が落ちる」という GPGPUのイメージに近いのはむしろ Xeon Phi であると言える結果になっています。
今回の実装は枝刈りをしていない O(N2) の粒子法シミュレーションですが、このベクトルの要素同士の全ペアについて計算を行う性質は、分子動力学等の N 体問題一般の枝狩りをしないケースや、第一原理計算の二電子積分のダイレクト計算に近く、これらの性能評価においても似たような傾向が得られることが期待されます。
関連リンク
- Tesla/Xeon Phi搭載製品ラインナップ:Tesla K20/K20X搭載製品のご案内
- GPGPUソリューション:自作プログラムのCUDA化代行サービス
- GPUで最速を極めるブログ:並列化/GPGPUのスペシャリストによる検証ブログ
- GPGPU対応アプリケーション:CUDAに対応したアプリケーションの一例をご紹介します
- CUDA Zone:GPGPUの開発ツール、対応GPU、事例、イベント等の最新情報 (外部リンク)
- GPU対応 PGIアクセラレータコンパイラ:CUDA環境上のGPUコンパイル機能を備えたコンパイラー (外部リンク)
【免責事項:外部リンクについて】
弊社は本サイトへリンクを張っている第三者のサイト(以下、外部リンクといいます)の確認を行っておりません。また弊社は外部リンクの内容およびお客さまの外部リンクの使用に関連して発生したいかなる損害に対しても責任を負いません。 本サイトから第三者のサイトへリンクしていることが、当該サイトの商品やサービスを保証するものでもなく、また外部リンクにある情報は、 弊社が保証したものでも、認めたものでもありません。あらかじめご了承くださいますようお願いします。
・Intel、インテル、Intelロゴ、Xeon、Xeon Inside は、米国およびその他の国におけるIntel Corporationの商標です。
・NVIDIA、NVIDIAロゴ、CUDAおよびTeslaは、米国及びその他の国におけるNVIDIA Corporationの商標または登録商標です。
・その他、記載されている会社名、製品名、サービス名等は、各社の商標または登録商標です。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)