
技術情報
1024コアインテル® Xeon® プロセッサー E5-2600 v2 クラスター ベンチマーク結果
弊社ラックマウントサーバ64ノード1024CPUコアからなるクラスタ計算機にて、各種ベンチマークを取得いたしました。インテル® Xeon® プロセッサー E5-2600 v2 ファミリーの大規模クラスタにおける実効性能・並列スケーラビリティを報告いたします。
STATUS
ベンチマーク環境
| 実行環境 | ||
|---|---|---|
| 製品 | HPC5000-XI2UTwin+ |  |
| ノード数 | 64 | |
| 総CPUコア数 | 1024 | |
| 総消費電力 | 62kW | |
| フォームファクター | ラックマウントタイプ (2Uに2ノード搭載) | |
| プロセッサー | インテル® Xeon® プロセッサー E5-2667 v2 (8コア, 3.30GHz) ×2CPUs | |
| メモリ | 128GB DDR3 1866MHz RDIMM | |
| OS | CentOS 6.4 x86_64 | |
| コンパイラー | インテル® Composer XE 2013 | |
| MPI | Intel MPI 1.6.5 および OpenMPI 1.6.5 | |
| インターコネクト | Infiniband FDR | |
| スクラッチ | インテル® SSD DC S3500 (120GB SATA 6Gb/s MLC) (2基をソフトウェアRAID0) | |
HPLで25TFlops達成!
HPL 2.1をOpenMPIおよびインテルMPIで1024並列実行させました。性能値を次グラフに示します。
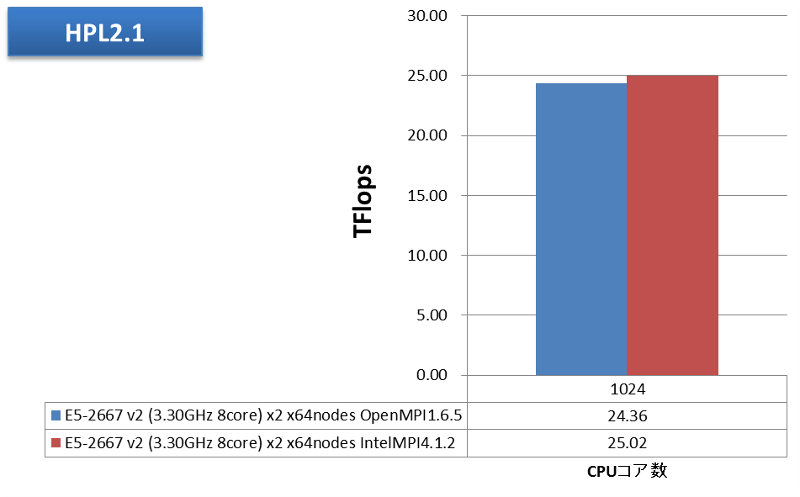
今回の64ノード全体の理論性能は422.4GFlops ×64=27.03TFlopsです。これに対し、最高で25.02TFlops、92.55%の実効効率を達成しました。
MPIの違いについては、このHPLベンチマークでは、ほとんどの時間がCPU上の計算で費やされ、通信の占める割合は相対的に小さいと考えられますが、それでも、大規模並列向けのチューニングに力を入れているインテルMPIの方が、わずかながら高い計算性能を引き出した結果となっています。
VASP大並列にはインテルMPIが大変良好
通信負荷の高いアプリケーション例として、弊社で継続的にベンチマークを取得しているVASPで評価しました。弊社では、VASP計算内の通信においてFFTのための全体全通信が支配的で、プロセス間通信のレイテンシの影響が大きいことを掴んでいます。2013年12月執筆時点の主流CPUの1024コアとInfiniband FDRの組み合わせでどこまでスケールするか、大変興味深いところです。VASP5.3.3にて、512原子および1000原子についてPAW GGA計算とUSPP計算を実施しました。並列数に応じた経過時間を次グラフに示します。
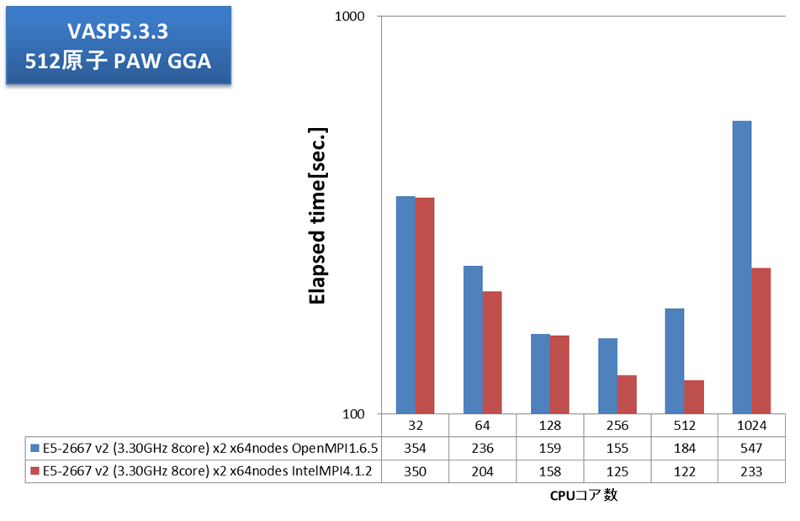
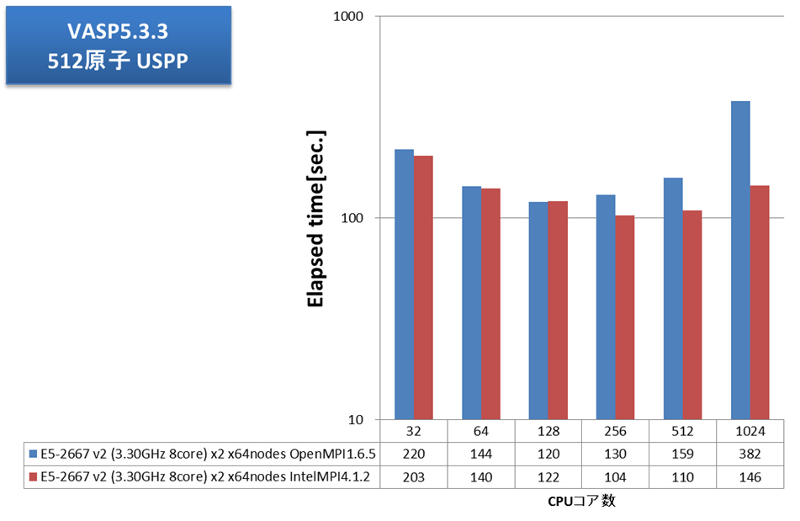
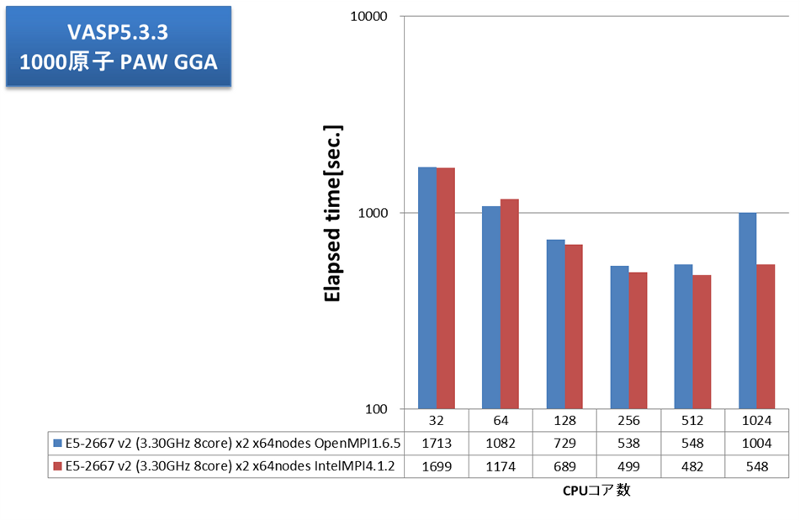
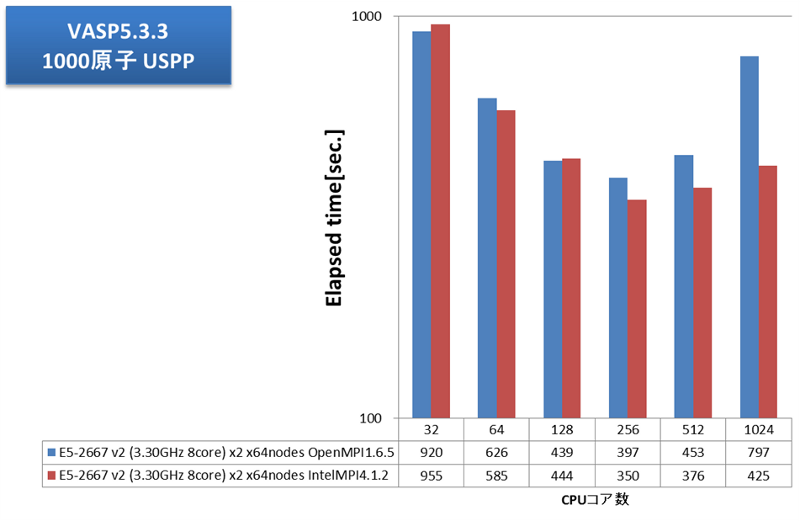
OpenMPIとインテルMPIとでVASP実効性能に大きな差が見られました。OpenMPIでは256コア(16ノード)並列で実効性能が頭打ちですが、インテルMPIでは512コアまで性能が伸びました。大規模並列向けのチューニングに力を入れているインテルMPIが功を奏しています。VASP用途クラスタにおける、MPIライブラリの選択、効率的な並列数の選択の指針として、大変参考になる結果が得られました。
ライセンスをまだお持ちでなくても、弊社のライセンスを使ってVASPをご評価いただけます
弊社では、材料科学分野のお客様の利便のため、2008年4月よりVASPベンチマークライセンスを導入しております。お客様のシステム選定やベンチマーク取得にと、大変ご好評を頂いております。VASPのベンチマーク評価をご希望のお客様は、是非ご検討ください。
GromacsはインテルMPIで1024並列まで性能向上を維持
分子動力学アプリケーションの例として、Gromacsのベンチマークを取得しました。指定サイズのボックスを水分子で満たして分子動力学計算を行う、弊社独自のインプットになります。水のみの系では実用的な計算結果にはなりませんが、弊社では様々なベンチマーク取得を実施し、Gromacsでは水のみの系であっても実効性能の傾向の予測に十分であると掴んでいます。6,417,942原子からなる、この水分子インプットについて、ノード数を変えながら経過時間とns/dayを測定しました。測定結果を次グラフに示します。ns/dayのグラフでは、性能劣化を見やすくするため、インテルMPIを用いた1ノード16コア並列時を基準とした理想的な性能向上を灰色点線で補記しています。
ns/dayは、Gromacsベンチマーク結果の性能比較用の単位です。 計算時間を基に、「1日あたり何ns分の分子動力学計算を実行可能か」を示した数字です(数字が大きいほど、高性能、高速となります)。
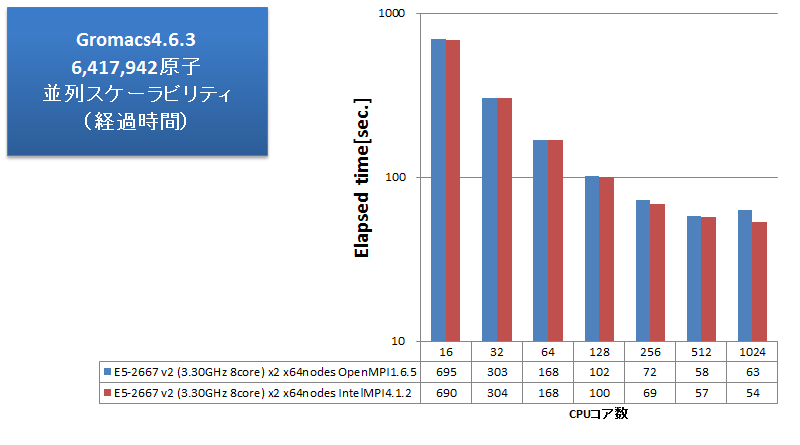
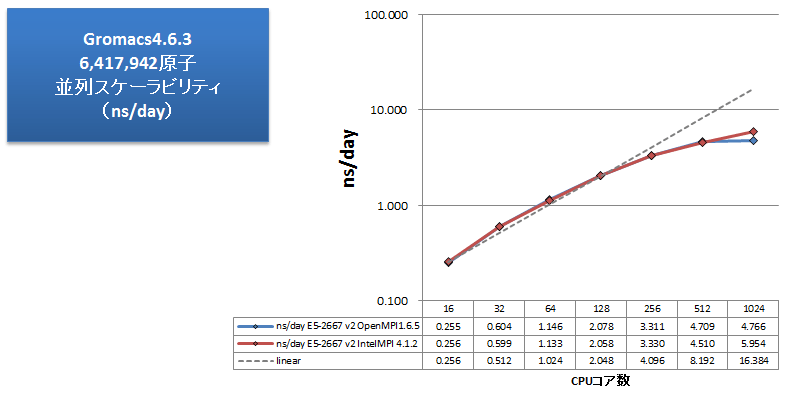
ns/dayのグラフより、Gromacsでは128コア並列まで理想的な性能向上を示し、この規模の系では数百並列まで十分な並列スケーラビリティが得られることを確認できました。OpenMPIとインテルMPIの比較では、512並列まではほぼ同等の性能となっています。1024並列時には、OpenMPIでは性能悪化になっていますが、インテルMPIではかろうじて性能向上を維持できています。VASPほどの顕著な差にはなりませんでしたが、大並列向けのチューニングに力を入れているインテルMPIの効果がここでも確認できる結果となりました。
Gaussian09 Lindaでは128並列で頭打ち
量子化学計算アプリケーションの例として、Gaussian09のベンチマークを取得しました。以前より多用してきたtest397はもはや小さすぎるインプットとなるため、より大きなインプットを用いました。詳細は明かせませんが、MP2/6-311G(d,p)で基底関数数900程度のシングルポイントエネルギー計算のインプットです。ノード数を変えながらLindaでノード間並列を行い、各ノードでは並列スレッド数16(%NProcShared=16)を指定しました。スクラッチにはSSD 2基をソフトウェアRAID0構成で使用しました。並列スケーラビリティを折れ線グラフで示します。また、長時間要したLinkであるl502(SCF方程式の反復的解法)・l906(Semi-direct MP2)・l1002(CPHF方程式の反復解法;様々なプロパティの計算(NMRを含む))について経過時間の占める割合を棒グラフに示します。
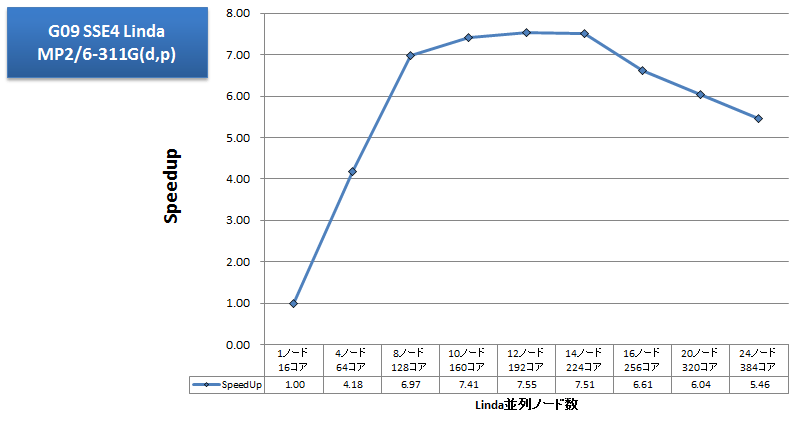
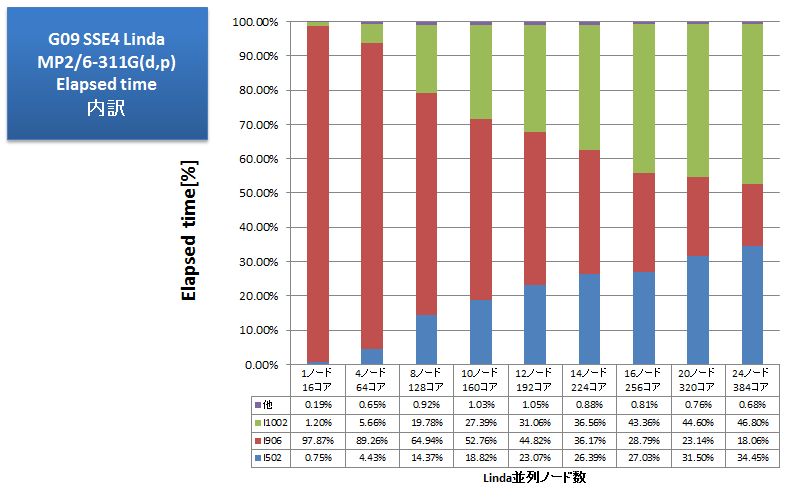
Linda並列では、1ノード16コア並列時に比べて、8ノード128コア並列時まで順調な速度向上が得られましたが、その後はノードを費やしても性能悪化する結果となりました。経過時間の割合を見ると、1ノードでは97%以上の時間を費やしたl906は、24ノード並列まで良好なスケーラビリティを示しています。一方、l502・l1002(いずれもLinda並列対応)の計算時間が徐々に膨らみ、14ノード以上でl906を追い越しています。性能悪化の原因は、Lindaでは1 Gigabit Ethernet上のTCP通信を行っているため通信ボトルネックかと考えがちですが、timeコマンドの計測の結果、16ノードから24ノード並列までsystem時間は短くなる一方で、user時間が長くなっていましたので、Linda並列時のGaussianの計算アルゴリズム側がボトルネック原因として推測されます。効率的なLinda並列数の選択の指針として、大変参考になる結果が得られました。
・Intel、インテル、Intel ロゴ、Xeon、Xeon Inside は、アメリカ合衆国及びその他の国における Intel Corporation の商標です。
・その他、記載されている会社名、製品名、サービス名等は、各社の商標または登録商標です。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)