
技術情報
インテル® Xeon® プロセッサー E5-2600 v2 ファミリー ベンチマーク結果
ベンチマーク結果
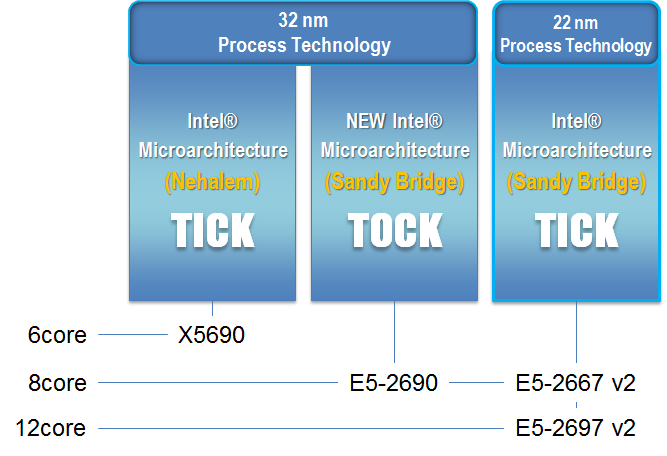
2013年Q3にリリースされるサーバ向けインテル® Xeon® プロセッサー E5-2600 v2 ファミリーについて、HPL及び各種実アプリケーションでベンチマークを取得しました。測定対象CPUは、8コア 3.30GHz の E5-2667 v2 、12コア 2.70GHz の E5-2697 v2 です。比較対象は、2011年の主流CPU Xeon X5690(3.46GHz 6core)と、2012年の主流CPU Xeon E5-2690(2.90GHz 8core)です。各CPUの製造プロセス、マイクロアーキテクチャー、コア数については右図を参考にしてください。
なお一部のベンチマーク結果には、計算時間に加えて計算を実行しているCPUコアの平均動作クロックを記載しています(観測には perf を用いました)※。測定対象CPUでは、電源・温度・電流仕様のTDPの限界未満で稼働している場合に、インテル® ターボ・ブースト・テクノロジーによって動作クロックが上昇する効果が得られます。ご利用ケースでの動作クロックの推測や、アプリケーションの計算速度メリットと照らし合わせたCPU選定などにご活用いただければ幸いです。
※検証環境の都合でX5690では動作クロックを観測できませんでした。代わりに参考として、CPU仕様の動作クロックとターボ・ブースト利用時の最大クロックを破線で記載しています。予めご了承ください。
HPL
HPLはスーパーコンピュータの性能ランキング『Top 500 Supercomputer Sites』で用いられているベンチマークプログラムです。HPLは連立方程式の解を求めるプログラムで、浮動小数点演算の性能を計測することができます。計算機の性能比較に広く用いられており、CPU性能について把握することができます。FLOPS単位、つまり1秒間に処理できる浮動小数点演算命令の数で計測結果を比較します。
HPLをインテルコンパイラーのAVX最適化を有効にしてビルドし、1ノード全コアを用いた場合の性能を測りました。グラフには各マシンのピーク性能値を記載しています。
| CPU | Xeon X5690 (3.46GHz, 6コア, 12MB Cache, 6.4GT/s Intel QPI, TDP130W) | Xeon E5-2690 (2.90GHz, 8コア, 20MB Cache, 8GT/s Intel QPI, TDP135W) | Xeon E5-2667 v2 (3.30GHz, 8コア, 25MB Cache, 8GT/s Intel QPI, TDP130W) | Xeon E5-2697 v2 (2.70GHz, 12コア, 30MB Cache, 8GT/s Intel QPI, TDP130W) |
|---|---|---|---|---|
| CPU数 | 2 (計12コア) | 2 (計16コア) | 2 (計16コア) | 2 (計24コア) |
| 理論性能 | 166.1GFlops | 371.2GFlops | 422.4GFlops | 518.4GFlops |
| メモリ | 48GB DDR3 1600MHz | 64GB DDR3 1600MHz | 128GB DDR3 1866MHz | 128GB DDR3 1866MHz |
| M/B | HPC5000-1UTwin | HPC5000-XS2UTwin+ | HPC5000-XI2UTwin+ | HPC5000-XI2UTwin+ |
| OS | CentOS 5.6 | CentOS 6.4 | CentOS 6.4 | CentOS 6.4 |
| インテル コンパイラー | 11.1 | 13.1 | 13.1 | 13.1 |
| MPI | OpenMPI 1.4.4 | OpenMPI 1.6.5 | OpenMPI 1.6.5 | OpenMPI 1.6.5 |
| HPL | 2.0 | 2.1 | 2.1 | 2.1 |
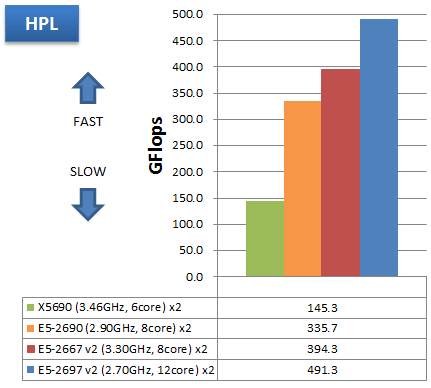
特長:コア数増とAVXにより、X5690に比べてノードあたり最大3.38倍の性能向上を達成
HPLでは、AVXの効果が十分に発揮され、X5690 12コア と E5-2697 v2 24コアの比較で3.38倍の性能向上を達成しています。これらの理論性能比は3.12倍ですが、それを上回る性能向上となった理由は X5690 のときよりも実行効率が87%から94%に向上したことです。HPLの性能を大きく左右するMKLが、Sandy BridgeマイクロアーキテクチャCPUの性能をより限界まで引き出すべくチューンアップされたことが窺われます。
2012年主流CPUの E5-2690 16コアと比較しても、E5-2697 v2 24コアで1.46倍となり、コア数にほぼ比例した性能向上を達成しています。
従来どおり、HPLではCPUの理論性能がほぼそのまま実効性能として表れる傾向が見てとれます。CPUボトルネックとなるプログラムについて、実効性能では最大でここまで出せるという一つの目安として捉えていただければと思います。
Amber
CPUボトルネックになるアプリケーションの例として、AmberをインテルコンパイラのAVX最適化を有効にしてビルドし、経過時間を測定しました。Amber公式サイトで入手できる408,000原子のCelluloseベンチマークをNVE・NVT・NPTで計算したときの経過時間を示します。
| CPU | Xeon X5690 (3.46GHz, 6コア, 12MB Cache, 6.4GT/s Intel QPI, TDP130W) | Xeon E5-2690 (2.90GHz, 8コア, 20MB Cache, 8GT/s Intel QPI, TDP135W) | Xeon E5-2667 v2 (3.30GHz, 8コア, 25MB Cache, 8GT/s Intel QPI, TDP130W) | Xeon E5-2697 v2 (2.70GHz, 12コア, 30MB Cache, 8GT/s Intel QPI, TDP130W) |
|---|---|---|---|---|
| CPU数 | 2 (計12コア) | 2 (計16コア) | 2 (計16コア) | 2 (計24コア) |
| メモリ | 48GB DDR3 1600MHz | 64GB DDR3 1600MHz | 128GB DDR3 1866MHz | 128GB DDR3 1866MHz |
| M/B | HPC5000-1UTwin | HPC5000-XS2UTwin+ | HPC5000-XI2UTwin+ | HPC5000-XI2UTwin+ |
| OS | CentOS 5.6 | CentOS 6.2 | CentOS 6.4 | CentOS 6.4 |
| インテル コンパイラー | 11.1 | 12.1 | 13.1 | 13.1 |
| MPI | OpenMPI 1.4.4 | OpenMPI 1.4.5 | OpenMPI 1.6.5 | OpenMPI 1.6.5 |
| Amber | 11 bugfix.20まで適用 | 12 bugfix.7まで適用 | 12 bugfix.19まで適用 | 12 bugfix.19まで適用 |
| AmberTools | 1.5 bugfix.26まで適用 | 12 bugfix.7まで適用 | 13 bugfix.16まで適用 | 13 bugfix.16まで適用 |
| ノード数 | 1 | 8 | 4 | 4 |
| インターコネクト | - | Infiniband FDR | Infiniband FDR | Infiniband FDR |
- Cellulose = 408,609原子

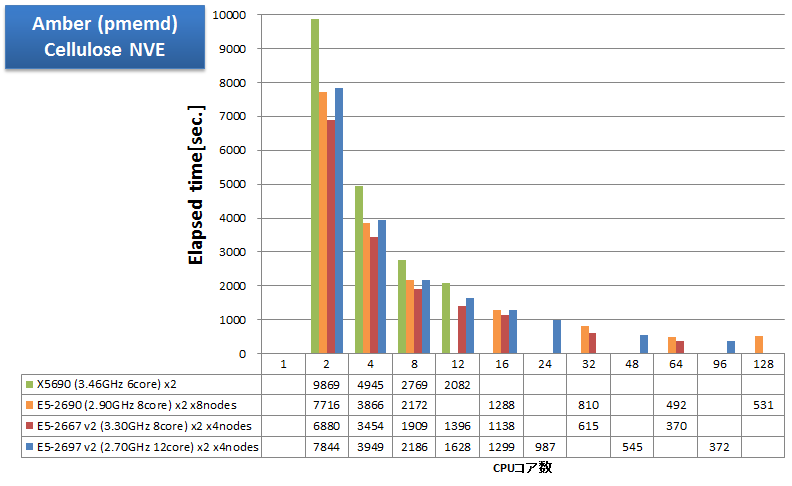
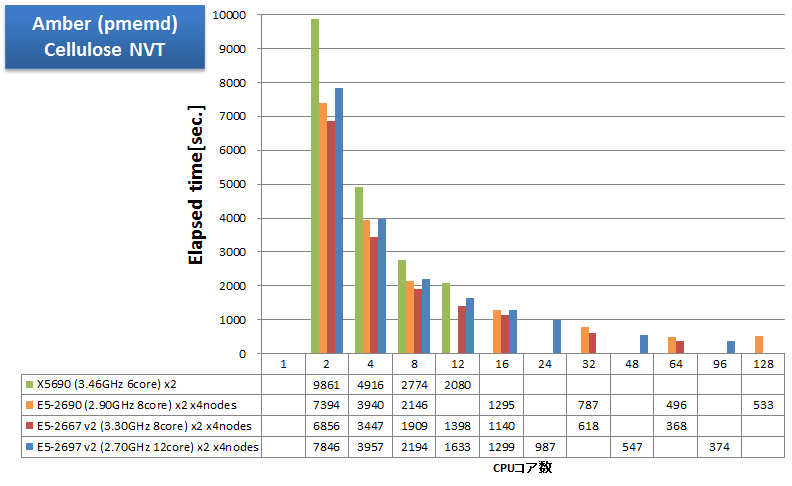
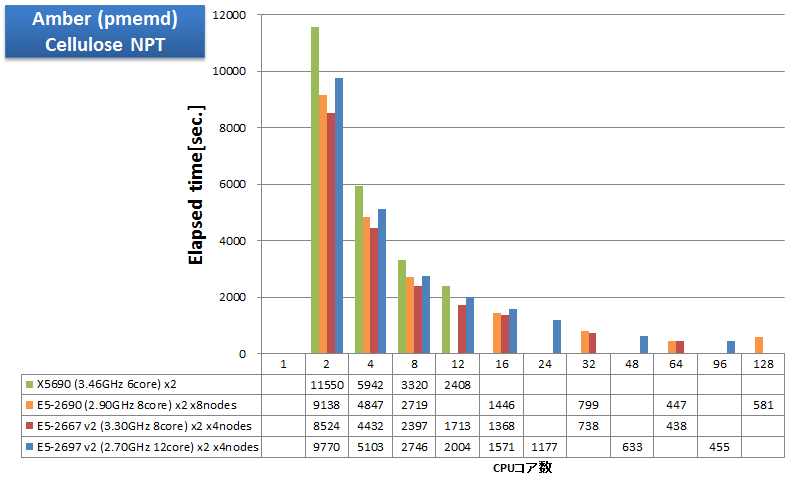
特長:AVXが威力を発揮、4ノード64コア並列まで順調に速度向上
Sandy BridgeマイクロアーキテクチャでSSEの2倍の演算幅のSIMD命令AVXを利用可能になったことで、同じ並列数においても、X5690 よりもクロックの低い E5-2600 シリーズの方が速い結果となっています。Amberのように、CPUボトルネックの傾向が強いアプリケーションでは、特に、AVXの使用が高速化に大変有効です。
並列スケーラビリティについては、1ノード内16コア・24コアまではもちろんのこと、4ノード64コアまで順調に速度向上が得られています。しかし、E5-2697 v2 の4ノード96コア並列になると速度向上が得られにくくなり、E5-2667 v2 の4ノード64コア並列よりも遅い結果となっています。これは、E5-2690 8ノード128並列時に逆に遅くなっていることから、計算インプットの性質である可能性が考えられます。
VASP
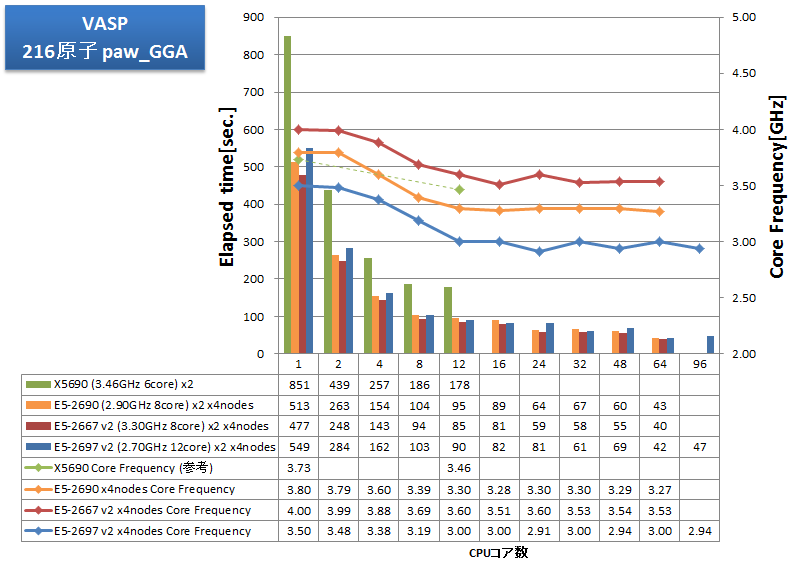
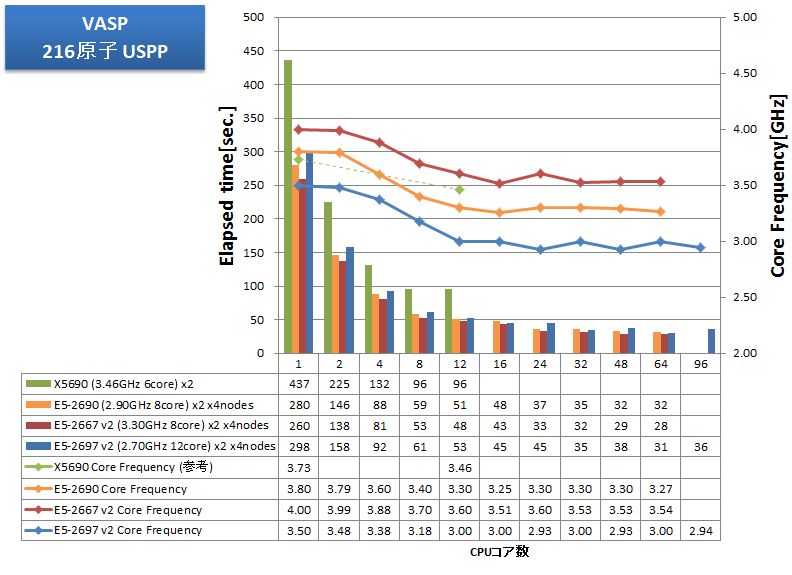
CPU-メモリ間の通信がボトルネックとなるアプリケーションの例として、VASPをインテルコンパイラのAVX最適化を有効にしてビルドし、その経過時間を測定しました。従来から測定している216原子のPAW GGA計算とUSPP計算に加えて、512原子のPAW GGA計算とUSPP計算を実施しました。
| CPU | Xeon X5690 (3.46GHz, 6コア, 12MB Cache, 6.4GT/s Intel QPI, TDP130W) | Xeon E5-2690 (2.90GHz, 8コア, 20MB Cache, 8GT/s Intel QPI, TDP135W) | Xeon E5-2667 v2 (3.30GHz, 8コア, 25MB Cache, 8GT/s Intel QPI, TDP130W) | Xeon E5-2697 v2 (2.70GHz, 12コア, 30MB Cache, 8GT/s Intel QPI, TDP130W) |
|---|---|---|---|---|
| CPU数 | 2 (計12コア) | 2 (計16コア) | 2 (計16コア) | 2 (計24コア) |
| メモリ | 48GB DDR3 1600MHz | 64GB DDR3 1600MHz | 128GB DDR3 1866MHz | 128GB DDR3 1866MHz |
| M/B | HPC5000-1UTwin | HPC5000-XS2UTwin+ | HPC5000-XI2UTwin+ | HPC5000-XI2UTwin+ |
| OS | CentOS 5.6 | CentOS 6.4 | CentOS 6.4 | CentOS 6.4 |
| インテル コンパイラー | 11.1 | 13.1 | 13.1 | 13.1 |
| MPI | OpenMPI 1.4.4 | OpenMPI 1.6.5 | OpenMPI 1.6.5 | OpenMPI 1.6.5 |
| VASP | 5.2.12 11Nov2011 Bugfix適用版 | 5.3.3 22May2013 Bugfix適用版 | 5.3.3 22May2013 Bugfix適用版 | 5.3.3 22May2013 Bugfix適用版 |
| ノード数 | 1 | 4 | 4 | 4 |
| インターコネクト | - | Infiniband FDR | Infiniband FDR | Infiniband FDR |
- 216原子 paw_GGA, USPP
- 512原子 paw_GGA, USPP
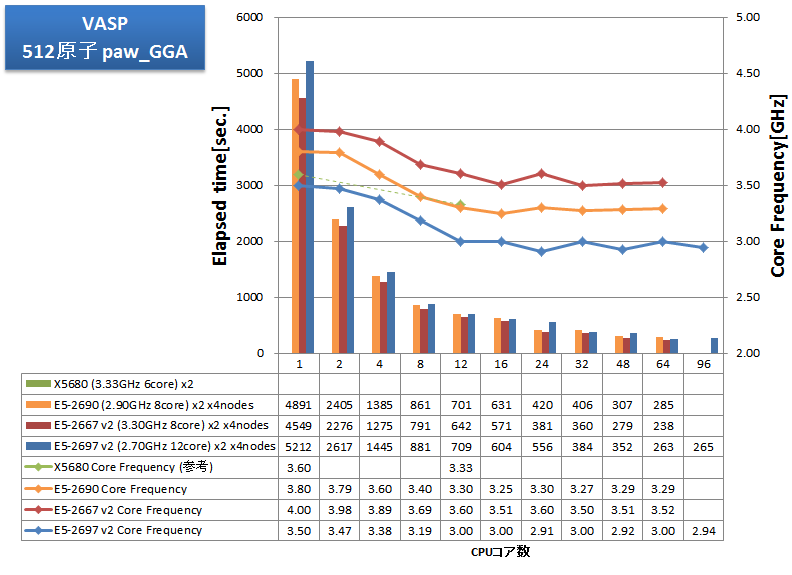
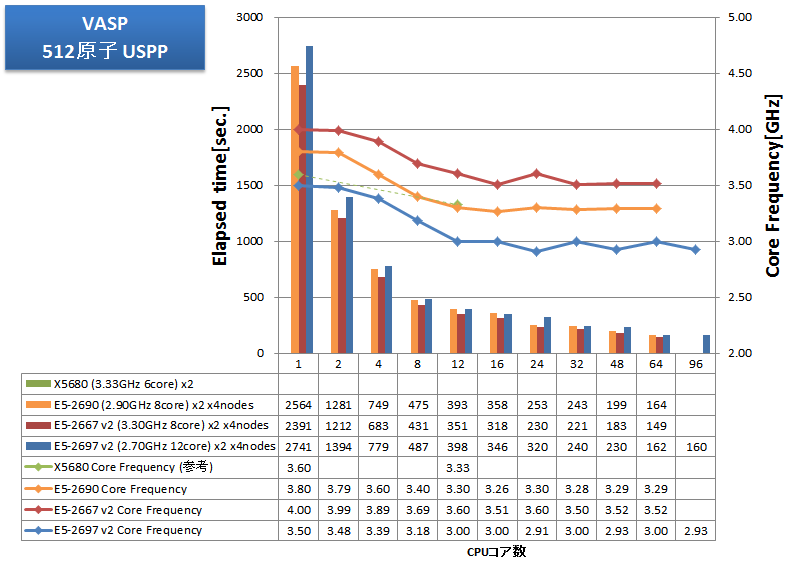
特長:メモリ帯域律速傾向から、12coreCPUよりも、8core高クロックCPUが効果的
E5-2600シリーズでは、v2 ファミリーの登場により、利用可能なコア数が1.5倍(8から12)に増大しましたが、メモリ帯域はわずか1.17倍(1600MHzから1866MHz、同チャネル数)に増えたのみでした。VASPのようにメモリ帯域を強く要求するアプリケーションでは、よりメモリアクセスに足を引っ張られCPU性能を出しにくい状況になったと言えます。
VASPでは、E5-2697 v2 の24並列に比べて、E5-2667 v2 の16並列の方が速い結果となりました。2ノード、4ノードにおいても同様の結果となっており、12コアCPUよりも8コアの高クロックCPUの使用が強く推奨されるアプリケーションと言えます。
HPCシステムズでは、材料科学分野のお客様の利便のため、VASPのベンチマークライセンスを導入しております。本記事のVASP 5.3についてもご利用可能です。お客様のシステム選定やベンチマーク取得にご活用ください。
Gaussian09 ※AVX未対応
AVXに未対応のバイナリアプリケーションのベンチマーク実行例です。SSE4に最適化されたGaussian社製バイナリを用いて恒例のtest397ベンチマークを測定しました。さらに、昨今の計算機性能の向上によって身近になってきた選択肢として、test397で基底関数系を6-31G(d,p)に変えた場合も測定しました。この他、シングルポイントエネルギー計算の例としてtest385の構造最適化結果を用いたTAXOL、および振動数計算の例としてα-Pineneについても経過時間を取得しました。計算時間の類推に参考にしていただければ幸いです。
| CPU | Xeon X5690 (3.46GHz, 6コア, 12MB Cache, 6.4GT/s Intel QPI, TDP130W) | Xeon E5-2690 (2.90GHz, 8コア, 20MB Cache, 8GT/s Intel QPI, TDP135W) | Xeon E5-2667 v2 (3.30GHz, 8コア, 25MB Cache, 8GT/s Intel QPI, TDP130W) | Xeon E5-2697 v2 (2.70GHz, 12コア, 30MB Cache, 8GT/s Intel QPI, TDP130W) |
|---|---|---|---|---|
| CPU数 | 2 (計12コア) | 2 (計16コア) | 2 (計16コア) | 2 (計24コア) |
| メモリ | 48GB DDR3 1600MHz | 64GB DDR3 1600MHz | 128GB DDR3 1866MHz | 128GB DDR3 1866MHz |
| M/B | HPC5000-1UTwin | HPC5000-XS2UTwin+ | HPC5000-XI2UTwin+ | HPC5000-XI2UTwin+ |
| OS | CentOS 5.6 | CentOS 6.4 | CentOS 6.4 | CentOS 6.4 |
| Gaussian09 | Rev. C.01 SSE4有効 | Rev. D.01 SSE4有効 | Rev. D.01 SSE4有効 | Rev. D.01 SSE4有効 |
- Valinomycin Force RB3LYP/3-21G, RB3LYP/6-31G(d,p)
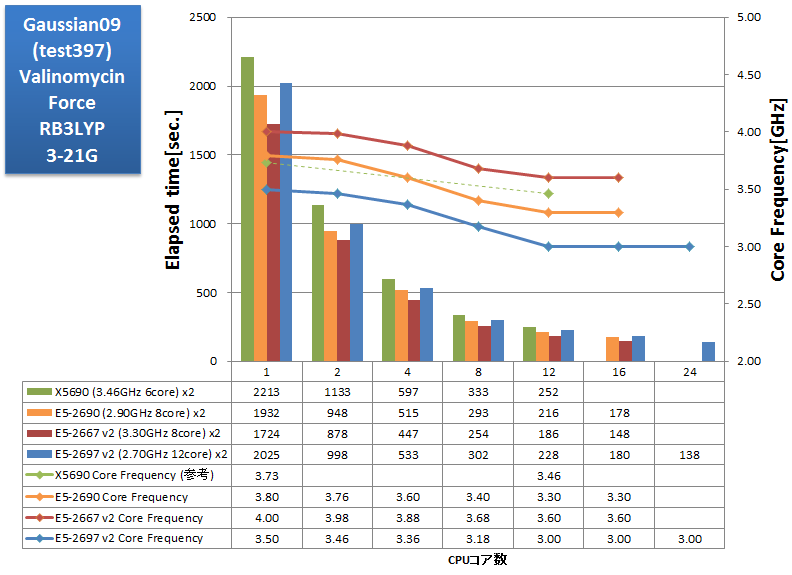 基底関数数:882
基底関数数:882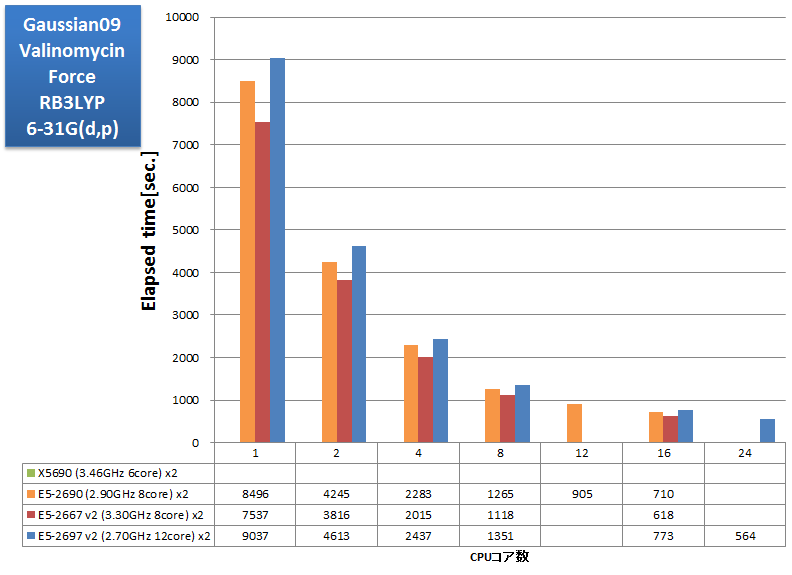 基底関数数:1620
基底関数数:1620
- TAXOL SP RB3LYP/cc-pVDZ
 TAXOL (C47H51NO14)
TAXOL (C47H51NO14)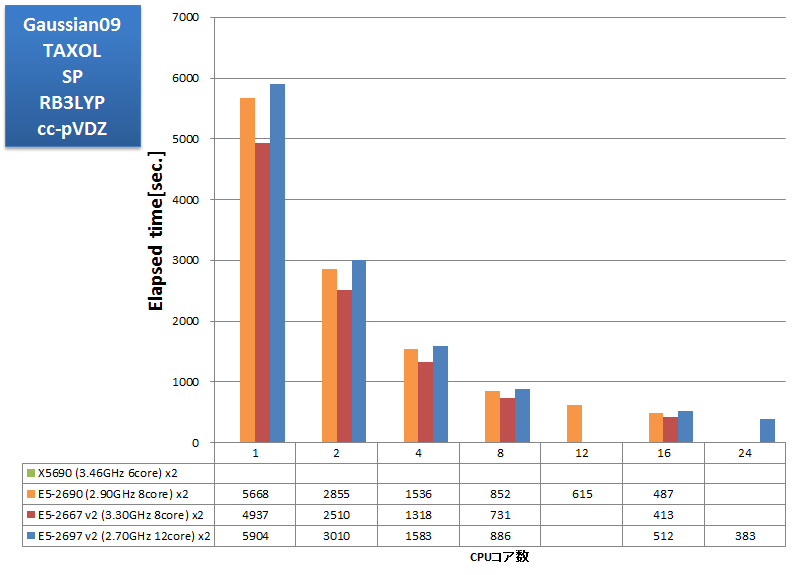 基底関数数:1123
基底関数数:1123
- α-Pinene Freq RB3LYP/6-311G(df,p)
 α-Pinene (C10H16)
α-Pinene (C10H16)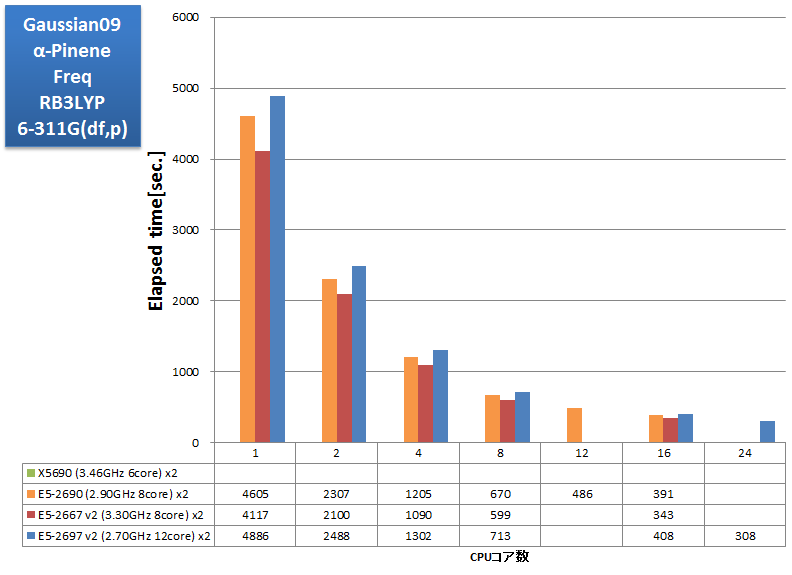 基底関数数:346
基底関数数:346
特長:24コア並列まで順調に並列スケーラビリティを達成、12coreCPUが活きる
Gaussian09 test397では、X5690 12コアに比べて E5-2697 v2 24コアで1.83倍の性能向上を得る事が出来ました。
並列スケーラビリティについては、上記いずれのインプットにおいても24コア並列まで順調な伸びが見られます。また、Sandy Bridgeマイクロアーキテクチャどうし(E5-2690、E5-2667 v2、E5-2697 v2)を比べると、同じ並列数において動作クロックにほぼ比例した計算速度となっています。
コアをつぎ込んだだけ性能がスケールし、動作クロックに応じて計算速度が向上することから、Gaussian用途の計算機には、コア数が多く、クロックの高い E5-2697 v2 をお勧めいたします。また、CPUが主なボトルネックと推測され、AVXの導入による性能向上に期待が持てます。今後AVX対応バイナリが発表されるのを期待して止みません。
複数ジョブ同時実行
逐次計算、あるいは小さな並列数で計算を実行すべき状況では、同時に数多くの計算を高スループットにこなす能力がCPUに求められます。HPL、VASPについて、同一の計算ジョブを同時に複数実行し、プロセス数が増えた時の性能劣化率(1プロセス実行時を100%とします)を測定しました。HPLではGflopsを、VASPでは経過時間を記していますので良悪の捉え方が逆となる点にご注意ください。
| CPU | Xeon X5690 (3.46GHz, 6コア, 12MB Cache, 6.4GT/s Intel QPI, TDP130W) | Xeon E5-2690 (2.90GHz, 8コア, 20MB Cache, 8GT/s Intel QPI, TDP135W) | Xeon E5-2667 v2 (3.30GHz, 8コア, 25MB Cache, 8GT/s Intel QPI, TDP130W) | Xeon E5-2697 v2 (2.70GHz, 12コア, 30MB Cache, 8GT/s Intel QPI, TDP130W) |
|---|---|---|---|---|
| CPU搭載数 | 2 (計12コア) | 2 (計16コア) | 2 (計16コア) | 2 (計24コア) |
| メモリ | 48GB DDR3 1600MHz | 64GB DDR3 1600MHz | 128GB DDR3 1866MHz | 128GB DDR3 1866MHz |
| M/B | HPC5000-1UTwin | X9DR6-F | HPC5000-XI2UTwin+ | HPC5000-XI2UTwin+ |
| OS | CentOS 5.6 | RHEL 6.1 | CentOS 6.4 | CentOS 6.4 |
| インテル コンパイラー | 11.1 | 12.0 | 13.1 | 13.1 |
| MPI | OpenMPI 1.4.4 | OpenMPI 1.4.4 | OpenMPI 1.6.5 | OpenMPI 1.6.5 |
| HPL | 2.0 | 2.0 | 2.1 | 2.1 |
| VASP | 5.2.12 11Nov2011 Bugfix適用版 | 5.2.12 11Nov2011 Bugfix適用版 | 5.3.3 22May2013 Bugfix適用版 | 5.3.3 22May2013 Bugfix適用版 |
- 複数ジョブ同時実行 HPL, VASP
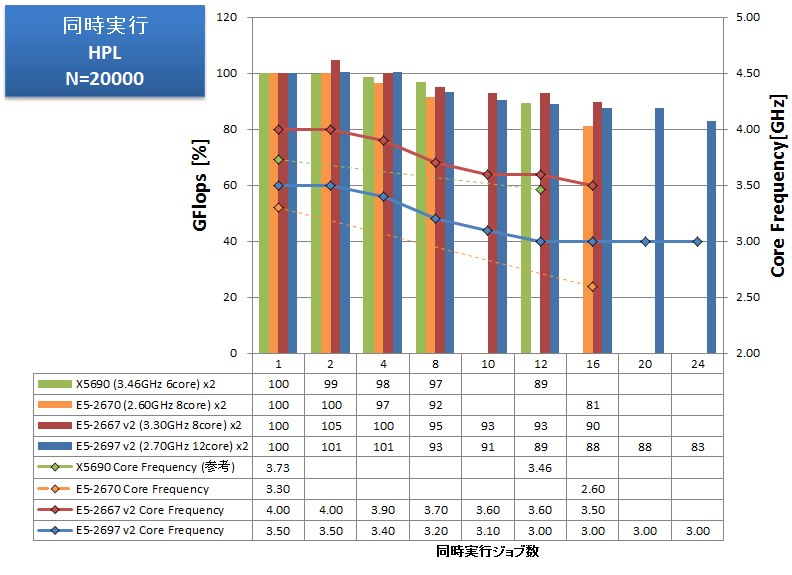
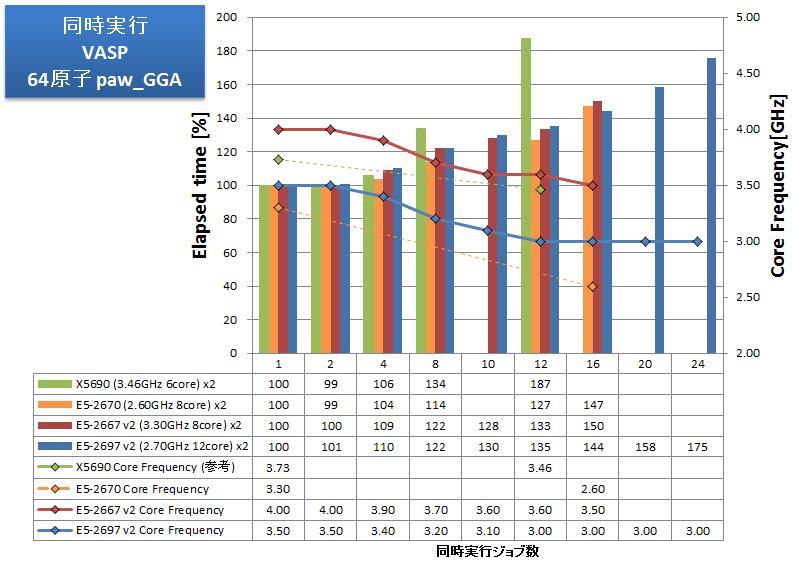
特長:Sandy Bridgeマイクロアーキテクチャの堅固さを維持
HPLでは X5690、E5-2670、E5-2667 v2、E5-2697 v2 とも性能劣化率はほぼ同じです。E5-2697 v2 で24ジョブを投入しても、各ジョブは1ジョブ単体実行時の83%の性能を維持できています。
VASPでは、X5690 と比べればSandy Bridgeマイクロアーキテクチャで劇的に性能劣化しにくくなりましたが、それでも16ジョブを超えたあたりから性能劣化を無視できず、24ジョブでは175%の経過時間となっています。メモリ帯域律速が原因として考えられ、VASP同様にメモリ帯域を強く要求するアプリケーションでは、複数ジョブ同時実行時の性能劣化に注意すべきです。
1ノードあたりの最大スループットで見ると、VASPでは、X5680の2CPUで12/1.8745=6.40個の計算を実行する間に、E5-2697 v2 の2CPUで24/1.75=13.7個の計算を実行でき、すなわち2.14倍のスループットを達成しています。また、E5-2667 v2 の2CPUでは16/1.44=11.1個 となり、E5-2697 v2 の2CPUが1.23倍のスループットとなっています。
インテル® Xeon® プロセッサー E5-2600 v2 ファミリー 搭載製品
・Intel、インテル、Intel ロゴ、Xeon、Xeon Inside は、アメリカ合衆国及びその他の国における Intel Corporation の商標です。
・その他、記載されている会社名、製品名、サービス名等は、各社の商標または登録商標です。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)