
技術情報
NVIDIA® Tesla® K20でのGromacs 4.6 GPUベンチマーク結果
フリーの分子動力学アプリケーションとしてGromacs(グローマックス)が存在します。2013年1月に新しくVer. 4.6がリリースされました。Gromacsは、Ver. 4.5よりGPU対応になりましたが、Ver. 4.6では、MPIを介してGPUへジョブを流す事が可能になりました。
Gromacsの特徴は、CPUのアーキテクチャにあわせたアセンブラコードが用意されている点です。Ver. 4.6では、SSEに加えて、AVXにも対応したアセンブラコードが実装されています。これらの点から、CPU性能を限界まで引き出した性能とGPUの性能とを比較可能ではないかと考え、NVIDIA Tesla K20Mでの性能調査と併せて、Gromacsのホームページに記載されているGPU用のベンチマークを実行しました。
Ver. 4.6に実装された新しい仕様として、GPUで使用可能な cut off schemes が verlet に変更されました。 それにより、dhfr solv のシリーズのインプットだけを実行出来ました。MPIを介してK20Mを複数枚で実行したところ、使用するK20Mの数に比例して直線的に速度向上が認められました。しかし、Xeon CPUの性能も高いため、K20M 4枚使用の場合の性能は、 E5-2687W 16コアと比較して同程度から最大で2倍強に留まりました。
評価環境
| フォームファクター | タワー型(4Uラックマウント対応) |   |
|---|---|---|
| プロセッサー | インテル Xeon プロセッサー E5-2687W(8コア,3.10GHz) ×2 | |
| メモリ | 64GB DDR3 1600MHz | |
| GPGPUカード | NVIDIA Tesla K20M ×4 | |
| コンパイラー | インテル Composer XE 2011 sp1.11.339 | |
| 数値演算ライブラリー | インテル MKL 10.3 Update 11 | |
| CUDA | CUDA Toolkit 5.0 | |
| OS | CentOS 6.2 x86_64 | |
| Gromacs | 4.6 |
ベンチマーク結果
Gromacs公式サイトのベンチマークページ にある6種のベンチマークインプットのうち、-testverlet オプションを付けて実行可能な dhfr-solv-PME・dhfr-solv-RF-1nm・dhfr-solv-RF-2nm を実行しました。 「ns/day」はGromacsのベンチマーク結果の性能比較用の単位です。 計算時間を基に、1日あたり何ns分の分子動力学計算を実行可能かを示した数字です(数字が大きいほど、高性能、高速となります)。
- ■ dhfrベンチに含まれる全分子(vmd 1.9.1で可視化)
- ■ dhfr分子のみをリボン表示(vmd 1.9.1で可視化)
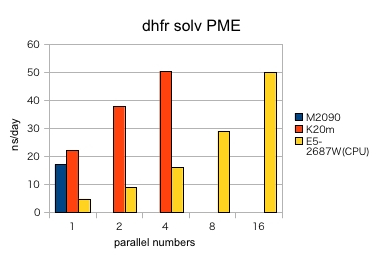
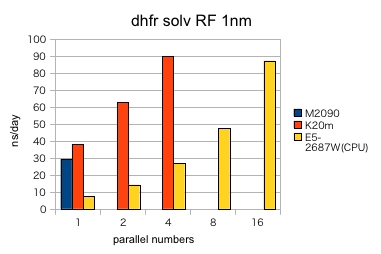
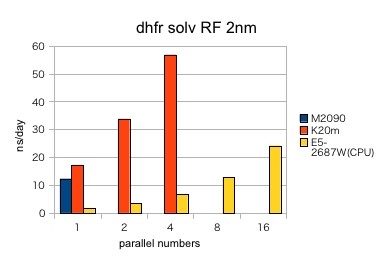
- K20M では、並列数に比例して、ほぼ直線に速度が向上していました。
- K20M は M2090 と比較した場合、30%程度、高性能でした。
- PME では、E5-2687Wの16並列で 49.94 ns/day に対して、K20Mx4並列 で 50.31 ns/day となり、 E5-2687W 16並列 と K20M 4並列 はほぼ同等の速度でした。
- RF 1nm では、E5-2687Wの16並列で 87.16 ns/day に対して、K20M 4並列 で 89.65ns/day となり、 E5-2687W 16並列 と K20M 4並列 はほぼ同等の速度でした。
- RF 2nm では、E5-2687Wの16並列で 24.19 ns/day に対して、K20M 4並列 で 56.81ns/day と2倍強となり、高速でした。
- PME・RF 1nm と RF 2nm との違いのように、GPUで、より効果的なインプットとそうでないインプットが存在しました。
-
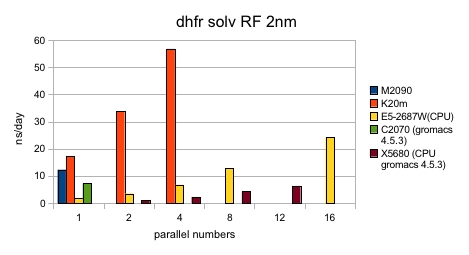
さらに、以前に弊社ウェブサイトで公開した Gromacs Ver. 4.5.3 での C2070 と X5680 の ベンチマーク結果と、今回の solv RF 2nm の結果を重ねたグラフを右に示します。
Gromacs Ver. 4.5.3 と 4.6 とでは cut off schemes が異なるので単純に比較は出来ませんが、性能の変化が読みとれると思います。
考察
GPUによる性能向上は大きなものですが、Xeonの性能向上も非常に大きなものでした。最後のグラフで見ると、C2070とX5680の時代では、GPU1枚とノード内フルコアの性能が同程度でした。しかしK20MとE5-2687Wとを比較すると、1ノード内の全コアを使用した場合、CPUがGPU1枚の性能を凌駕しています。GPUの性能はC2070当時に比べて倍程度向上していますが、Xeonは倍以上向上しています。これはAVXの効果が大きく、さらにコア数の増加も相まって、 単純にGPUさえ使用したら高速になるとは言えなくなってきていると考えられます。
さらに、PME・RF 1nm と RF2nm との違いのように、アプリケーションの対応に加えてGPUに向いたインプットとそうではないインプットが存在する事も事実です。GPUの性能を引き出すには、インプットデータの性質の把握が重要な要因と言えるでしょう。
今後の展開
GPUでアプリケーションを動作させる為には、(Gromacsでアーキテクチャに合せたコードを作成しているように)GPU用にコードを最適化しなくてはなりませんが、それと同じ様にソースコードを見直す事で、GPUに比べて遅いと思われていた他のアプリケーションもCPUで更に高速化する余地が以前より大きくなったかもしれません。
一方、MPIを使用した複数GPU並列に対応したアプリケーションが、GromacsやAmberなどのように増加していますから、GPUにおいても多数並列によりシステム全体の能力向上が可能になりつつあります。今回のベンチマークでは、複数ノードで並列させた場合にGPUでどの程度まで性能が直線的に向上するかは評価していませんが、CPUでの場合、高速なインターコネクトなどが重要な要因である事から、同じような傾向がある事も予想されます。
インプットデータによっても、GPUを使用した方がより高速なもの、性能が向上したCPUの存在により、GPUを使うまでもない場合などの違いがあります。研究や計算のトータルワークスループットを向上させるには、最適なシステム構成やアプリケーションのチューニングに加えて、ジョブの割り振りなど、ワークフローのチューニングも重要になってくると思われます。
MPIを利用したGPUへのジョブの投入がCPUと同じように可能になりつつあるという事は、LSFのようなリソース管理能力の高いジョブ管理システムとの親和性が高く、高度なワークフローの実行を、よりサポート可能になってゆくと考えられます。
Gromacs計算環境のセットアップ承ります
弊社では、更新の多いGromacsの最新版に追随し、最新ハードウェアにて動作検証とチューニングを行っています。弊社の計算機をお買い上げいただきますと、高速、かつ、計算精度を保持した Gromacs計算環境を、すぐにお使いいただける状態でお届けいたします。一秒でも多く大切なご研究・ご業務にご注力いただけますように、Gromacs計算環境のセットアップは弊社にお任せください。
関連リンク
- Tesla/Xeon Phi搭載製品ラインナップ:Tesla K20/K20X搭載製品のご案内
- GPGPUソリューション:自作プログラムのCUDA化代行サービス
- GPGPU対応アプリケーション:CUDAに対応したアプリケーションの一例をご紹介します
- CUDA Zone:GPGPUの開発ツール、対応GPU、事例、イベント等の最新情報 (外部リンク)
- GPU対応 PGIアクセラレータコンパイラ:CUDA環境上のGPUコンパイル機能を備えたコンパイラー (外部リンク)
【免責事項:外部リンクについて】
弊社は本サイトへリンクを張っている第三者のサイト(以下、外部リンクといいます)の確認を行っておりません。また弊社は外部リンクの内容およびお客さまの外部リンクの使用に関連して発生したいかなる損害に対しても責任を負いません。 本サイトから第三者のサイトへリンクしていることが、当該サイトの商品やサービスを保証するものでもなく、また外部リンクにある情報は、 弊社が保証したものでも、認めたものでもありません。あらかじめご了承くださいますようお願いします。
・Intel、インテル、Intelロゴ、Xeon、Xeon Inside は、米国およびその他の国におけるIntel Corporationの商標です。
・NVIDIA、NVIDIAロゴ、CUDAおよびTeslaは、米国及びその他の国におけるNVIDIA Corporationの商標または登録商標です。
・その他、記載されている会社名、製品名、サービス名等は、各社の商標または登録商標です。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)