
技術情報
インテル® Xeon Phi™ 5110Pでの行列積ベンチマーク結果
弊社検証用Phi 5110Pにて、行列積のベンチマークを取得しました。2012年11月13日の弊社検証結果よりもさらに高性能となりました(前回遅かった原因は、搭載コア数の違いもありますが、主に省電力モードで動作していたことによります)。
ベンチマーク結果
評価環境
次の環境でベンチマークを実行しました。
| 評価環境 | ||
|---|---|---|
| ノード数 | 1 |   |
| フォームファクター | タワー型 (4Uラックマウント対応) | |
| プロセッサー | インテル Xeon プロセッサー E5-2687W @ 3.10GHz x2CPUs |
|
| メモリ | 64GB DDR3 | |
| コプロセッサー | インテル Xeon Phi 5110P (1.053GHz, 60core / 240threads) | |
| コンパイラー | インテル Composer XE 13.0 Update 1 | |
| 数値演算ライブラリー | インテル MKL 11.0 Update 1 | |
| MPI | Intel MPI 4.1 | |
| OS | RedHat Enterprise Linux 6.3 x86_64 | |
行列積ベンチマーク結果
MKLのGEMMを用いる行列積プログラムを、行列サイズを変えながらPhi 5110P上で実行し(Compiler Assisted Offload)、ベンチマーク取得しました。
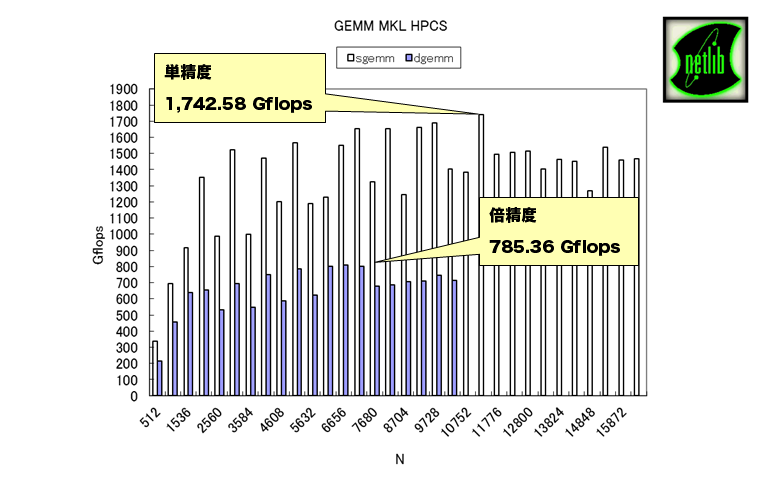
最高で、単精度では1741.58Gflops、倍精度では785.36GflopsをPhi 5110Pの1枚で達成しました。
実行効率について
Phi 5110Pの倍精度浮動小数点数演算の理論性能は、60core × 1.053GHz × 16flops/clock/core = 1010.88Gflopsです。したがって上記行列積の実行効率は単精度86.1%、倍精度77.7%です。本ベンチマークではGEMM関数のみの経過時間を計測していますので、この実行効率はPhi 5110Pに対するMKLの最適化度合いと換言できます。 これに対しCUBLASを用いたTesla M2090では実行効率が50%程度となっています(ベンチマークページ)。 Phiの実行効率の高さは、プロセッサー、コンパイラー、さらに数値演算ライブラリーを一手に開発しているがゆえのインテルの強みの表れと言えるかもしれません。弊社では引き続きPhiの実アプリケーション性能評価を進めてまいります。
★続報はこちらから
・Intel、インテル、Intelロゴ、Xeon、Xeon Inside は、米国およびその他の国におけるIntel Corporationの商標です。
・NVIDIA、NVIDIAロゴ、CUDAおよびTeslaは、米国及びその他の国におけるNVIDIA Corporationの商標または登録商標です。
・その他、記載されている会社名、製品名、サービス名等は、各社の商標または登録商標です。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)