
技術情報
インテル® Xeon® E5-2600シリーズ 8ノードクラスターでのAmber12ベンチマーク
HPC5000-XS2UTwinのようにサーバーの高集積化が進み、4ノードを超えるクラスターを省スペースで利用できるようになりました。また複数ノード並列計算のための高速インターコネクトスイッチは依然として高価で、その費用対効果がシステム構成のポイントの一つです。一方、ソフトウェア面ではSandyBridgeマイクロアーキテクチャでAVXが利用可能となりました。しかし、AVXではコンパイラーによって適応的に高速化が行われるため、実アプリケーションの実効性能を掴みにくくなっています。そこで、実アプリケーションを対象とした安価かつ高性能なシステム構成を明らかにするべく、弊社内8ノードベンチマーク環境を用いてGbEとInfiniband FDR構成にてAmber12のベンチマークを取得しました。
検証環境
評価環境は次表のとおりです。
| 検証環境 | ||
|---|---|---|
| 製品 | HPC5000-XS2UTwin |  |
| ノード数 | 8ノード | |
| フォームファクター | 8U | |
| 各ノードの構成は以下の通り | ||
| プロセッサー | インテル® Xeon® プロセッサー E5-2690 (8コア,2.9GHz) ×2 | |
| メモリ | DDR3-1600 RDIMM 64GB | |
| コンパイラー | インテルComposer XE 2011 update 10 | |
| MPI | OpenMPI 1.4.5 | |
| OS | CentOS 6.2 x86_64 | |
| Amber | Amber12 patch 7 | |
| AmberTools | AmberTools12 patch 7 | |
ベンチマーク結果
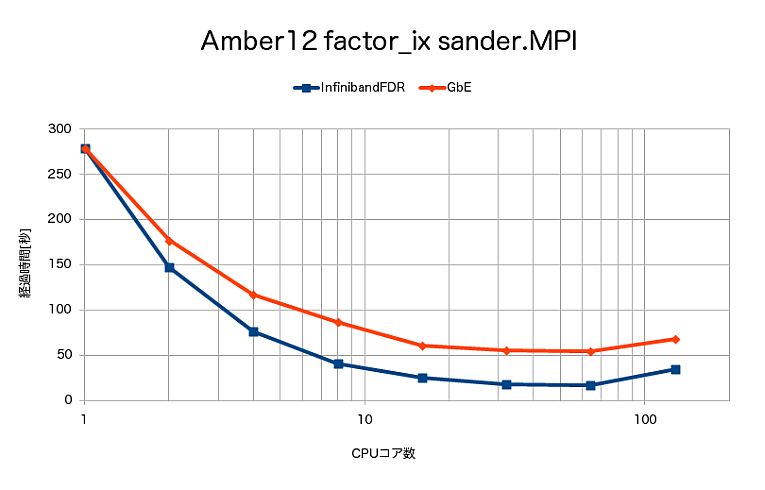
sander.MPIによるfactor_ixの計算時間は、次となりました。
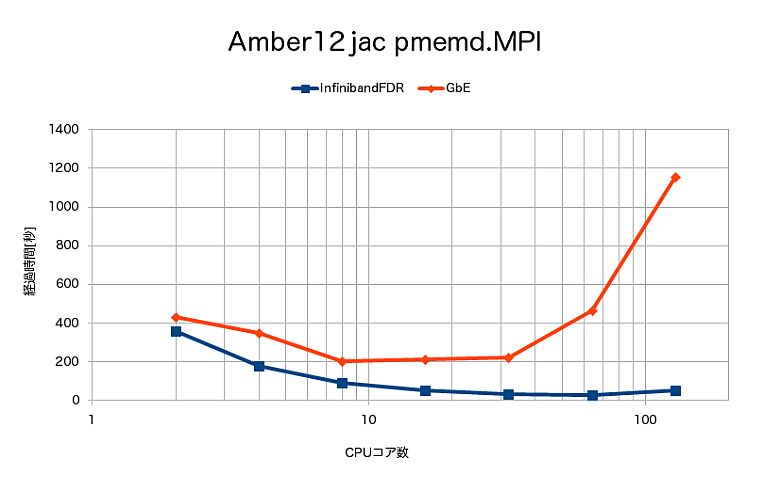
pmemd.MPIによるjacの計算時間は、次となりました。
この結果、次のことがわかりました。
- sander.MPIでは、期待通りGbEに比べてInfiniband FDRの方が大きく速度向上しました。
- 高速で計算を行うpmemd.MPIでは、計算方式の特性からインターコネクトの影響が大きく、GbEでは非常に強く性能劣化が見られ、16並列程度で限界となりました。一方、Infiniband FDRでは64並列まで速度向上が見られました。128並列ではいずれも性能劣化が見られました。
結論
Amber12の場合は、GbEでノード間並列を行って並列数を増やすよりも、GbEしかない場合には、複数ノード並列を行わずに、ジョブ管理ソフトを併用して各ノードに異なるジョブを割り当てて、システム全体のトータルスループットを向上させる、といった利用が費用対効果として有効と考えられます。弊社はこのような実アプリケーションの実効性能に基づくシステム提案を得意としております。高性能計算システムをご要望の場合、是非弊社にお問い合わせください。
インテル® Xeon® E5-2600シリーズ搭載製品についてはこちらを参照ください。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)