
技術情報
インテル® Xeon® E5-2670 ベンチマーク結果
前世代CPU Xeon X5690(3.46GHz)と、Sandy BridgeマイクロアーキテクチャCPU Xeon E5-2670(2.60GHz)にてベンチマーク比較を行いました。
HPL 2.0
HPLはスーパーコンピュータの性能ランキング『Top 500 Supercomputer Sites』で用いられているベンチマークプログラムです。HPLは連立方程式の解を求めるプログラムで、浮動小数点演算の性能を計測することができます。計算機の性能比較に広く用いられており、CPU性能について把握することができます。FLOPS単位、つまり1秒間に処理できる浮動小数点演算命令の数で計測結果を比較します。
HPL 2.0をインテルコンパイラーのAVX最適化を有効にしてビルドし、その性能を測りました。従来から定点観測的に毎回測定しているN=20000の場合と、ピーク性能を引き出すためにより計算量の大きいN=81000の場合を測定しました。
| CPU | Xeon X5690 (3.46GHz,6コア,12MB Cache,6.4GT/s Intel QPI) | Xeon E5-2670 (2.60GHz,8コア,20MB Cache,8.4GT/s Intel QPI) |
|---|---|---|
| CPU搭載数 | 2(計12コア) | 2(計16コア) |
| OS | CentOS 5.6 | Red Hat Enterprise Linux 6.1 |
| M/B | HPC5000-1UTwin | X9DR6-F |
| Memory | 48GB | 64GB |
| Intel Compiler | 11.1 | 12.0 |
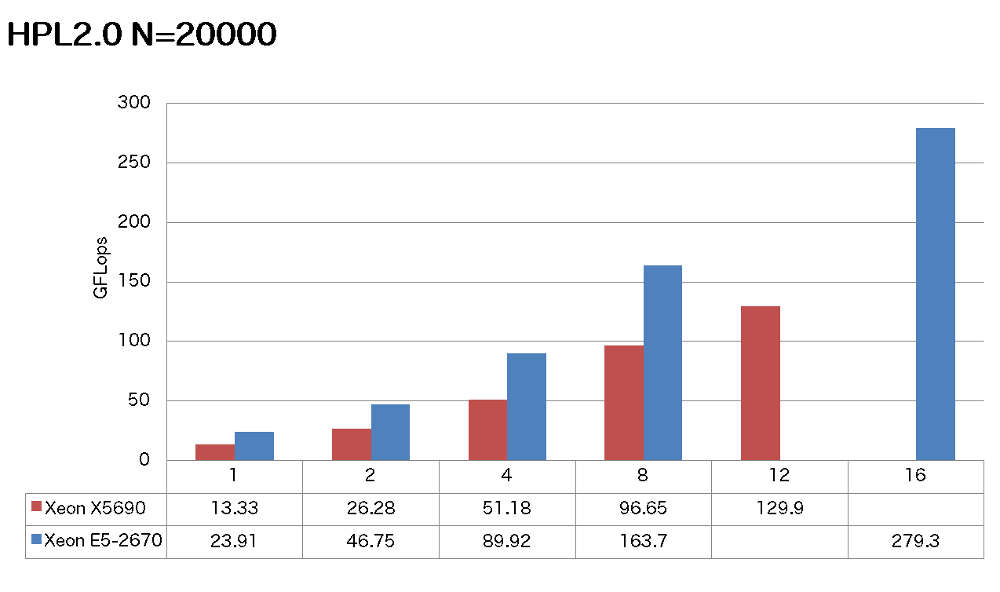
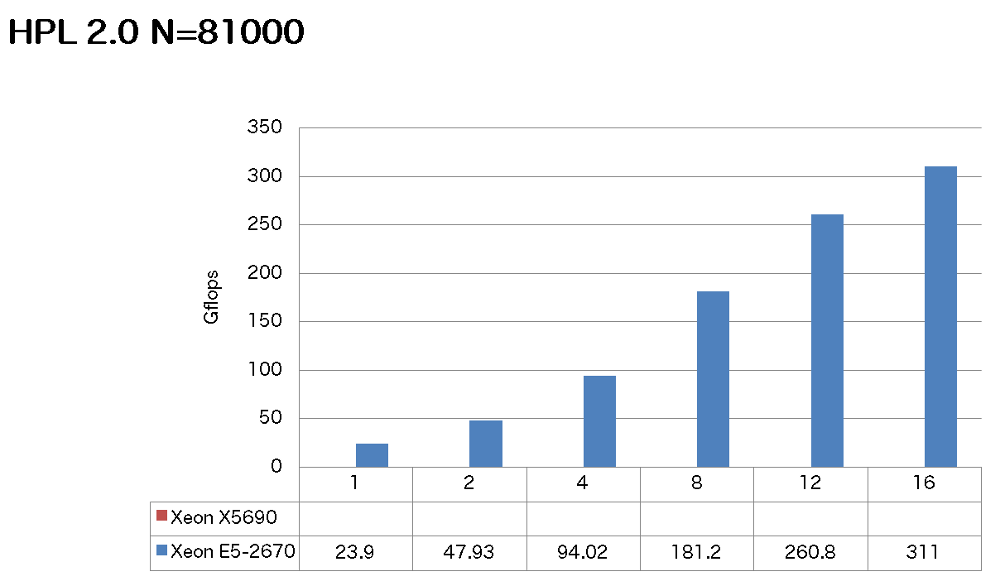
特長:AVXを活用してノードあたり2倍以上の性能向上を達成
HPLでは、AVXの効果が十分に発揮され、N=20000において X5690 12コアとE5-2670 16コアの比較で2.1倍以上の性能向上を達成しています。従来のノードあたりの性能の2倍以上を達成できるということは、お使いの実計算を2倍高速化する力を秘めていることを示唆しています。
またN=81000では、E5-2670の理論性能332.8GFlopsの93%の実行効率が得られています。高い実行効率に手が届きやすいCPUといえます。但しこれにはコンパイラーオプションをはじめ、高度なチューニング作業が求められます。弊社ではチューニング後の最速のバイナリをインテグレーションいたします。
インテル®Xeon®E5-2600シリーズ搭載製品についてはこちらを参照ください。
同時実行
逐次計算、あるいは小さな並列数で計算を実行すべき状況では、同時に数多くの計算を高スループットにこなす能力がCPUに求められます。HPL、VASPについて、同一の計算ジョブを同時に複数実行し、プロセス数が増えた時の性能劣化率を測定しました。HPLではGflopsを、VASPでは経過時間を記していますので良悪の捉え方が逆となる点にご注意ください。
| CPU | Xeon X5680 (3.33GHz,6コア,12MB Cache,6.4GT/s Intel QPI) | Xeon E5-2670 (2.60GHz,8コア,20MB Cache,8.4GT/s Intel QPI) |
|---|---|---|
| CPU搭載数 | 2(計12コア) | 2(計16コア) |
| OS | CentOS 5.7 | Red Hat Enterprise Linux 6.1 |
| M/B | HPC5000-Z800 | X9DR6-F |
| Memory | 48GB | 64GB |
| Intel Compiler | 11.1 | 12.0 |
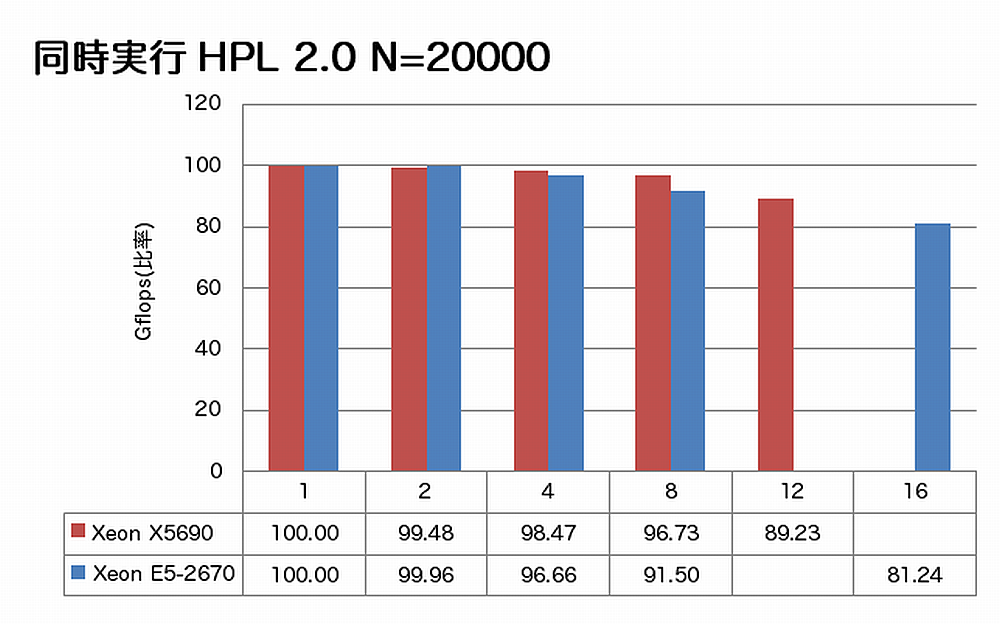
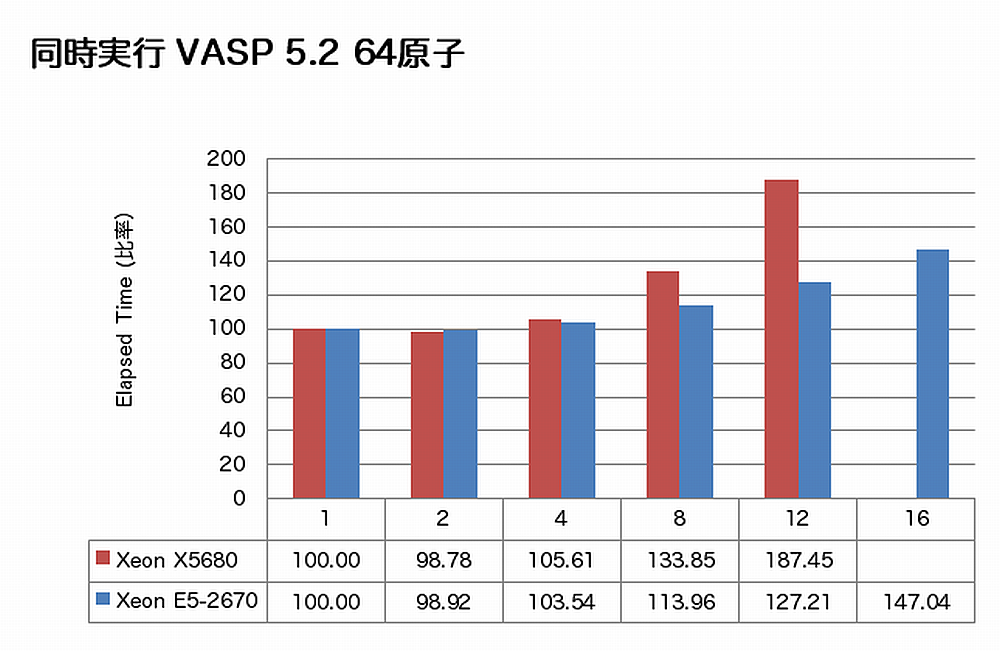
特長:コアを埋めても性能劣化ほとんどなし
HPLでは両CPU間の性能劣化率はほぼ同じです。一方、VASPでは、同時実行プロセス数を増やしてもE5-2670の経過時間の増加は微々たるもので、E5-2670ではコアを埋めても性能が劣化しづらい事を示しています。同時実行性能を維持する堅固な土台がE5-2670にはあります。
1ノードあたりの最大スループットで見ると、VASPでは、X5680の2CPUで12/1.8745=6.40個の計算を実行する間に、E5-2670の2CPUで16/1.4704=10.9個の計算を実行でき、すなわち1.7倍のスループットを達成しています。
インテル® Xeon® E5-2600シリーズ搭載製品についてはこちらを参照ください。
Amber11
AVXを適用可能なアプリケーションの例として、AmberをインテルコンパイラのAVX最適化を有効にしてビルドし、経過時間を測定しました。従来から測定しているPMEのfactor_ixとhb、Generalized Bornのgb_alpとgb_mb、さらにAmber公式サイトで入手できる408,000原子のCelluloseベンチマークをNVE・NVT・NPTで計算したときの経過時間を示します。
| CPU | Xeon X5690 (3.46GHz,6コア,12MB Cache,6.4GT/s Intel QPI) | Xeon E5-2670 (2.60GHz,8コア,20MB Cache,8.4GT/s Intel QPI) |
|---|---|---|
| CPU搭載数 | 2(計12コア) | 2(計16コア) |
| OS | CentOS 5.6 | Red Hat Enterprise Linux 6.1 |
| M/B | HPC5000-1UTwin | X9DR6-F |
| Memory | 48GB | 64GB |
| Intel Compiler | 11.1 | 12.0 |
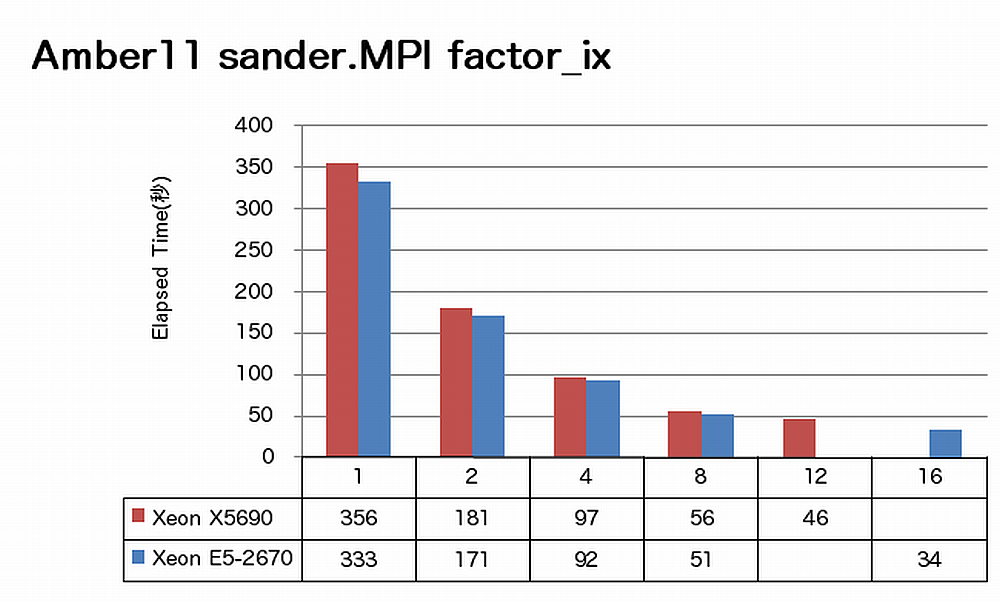
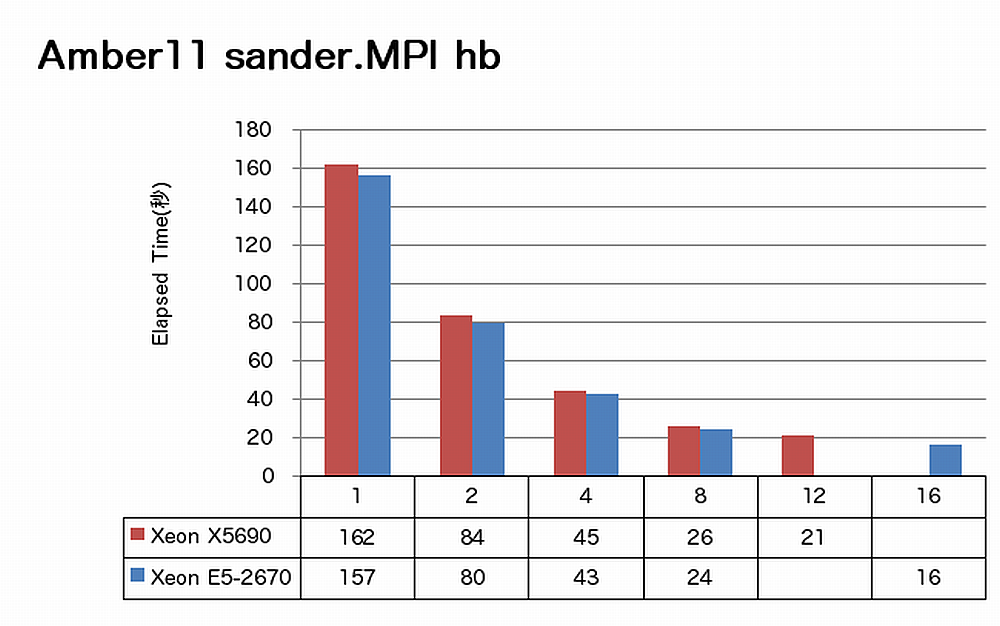
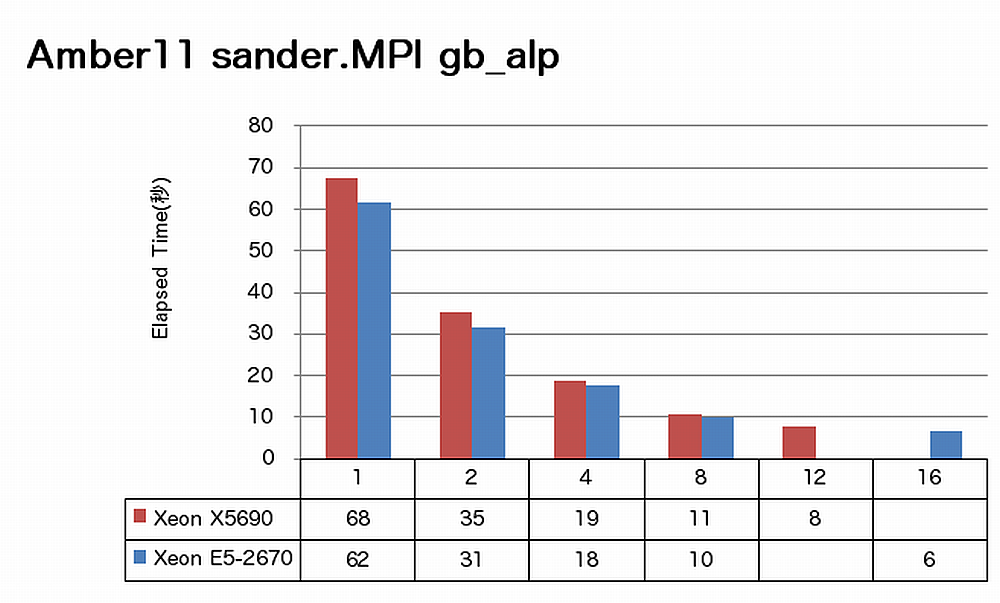
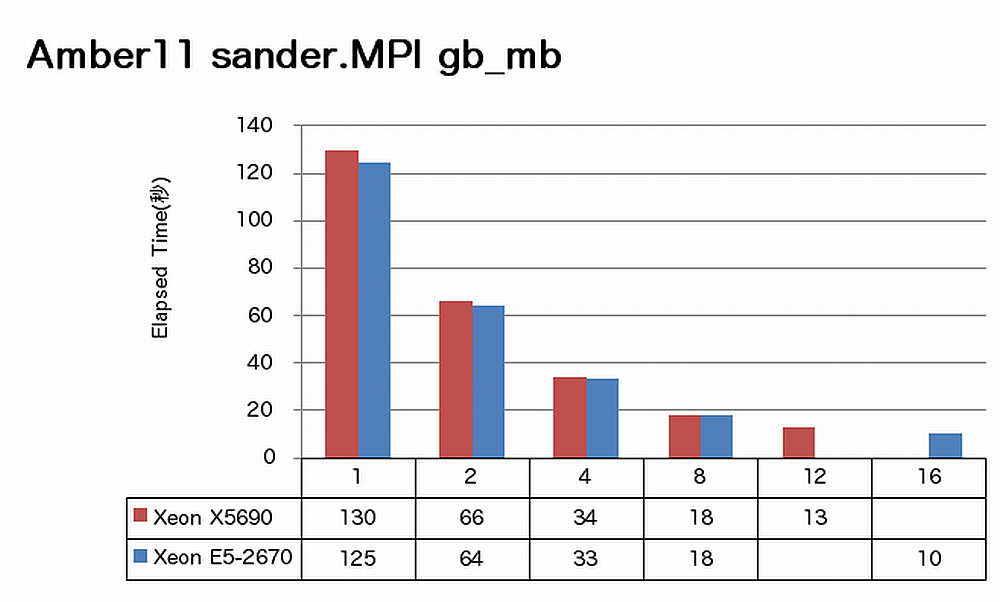
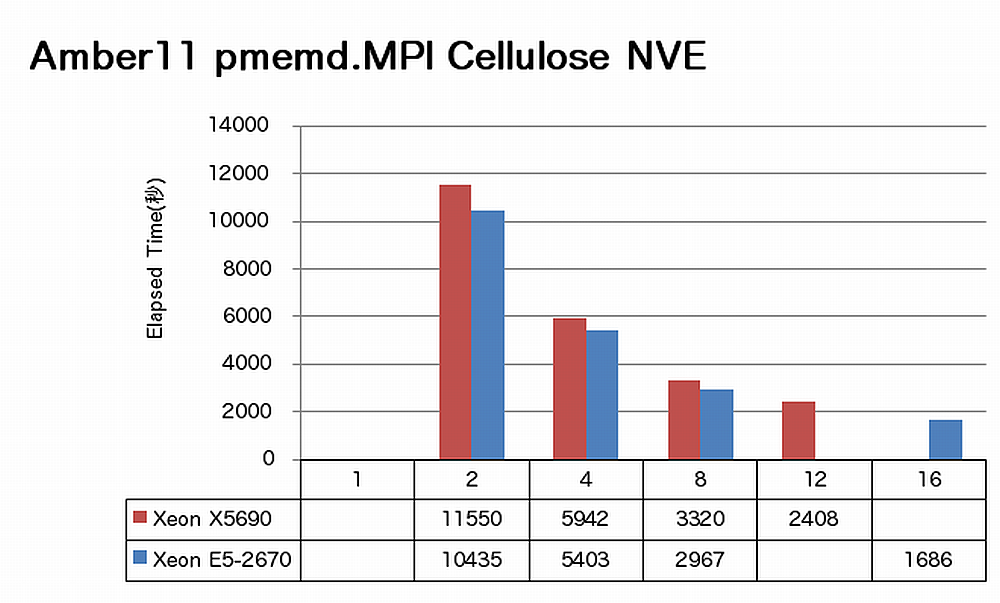
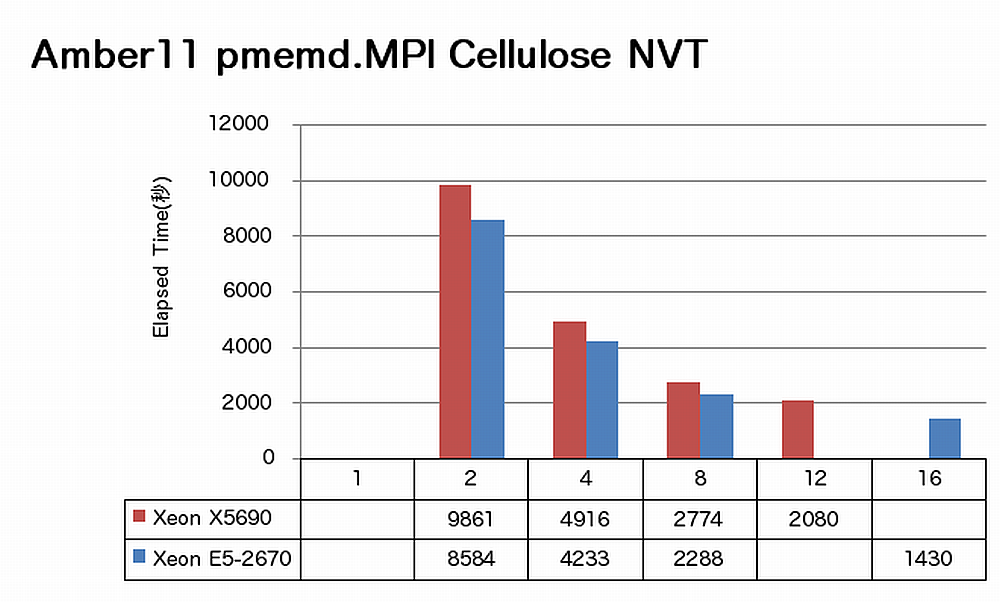
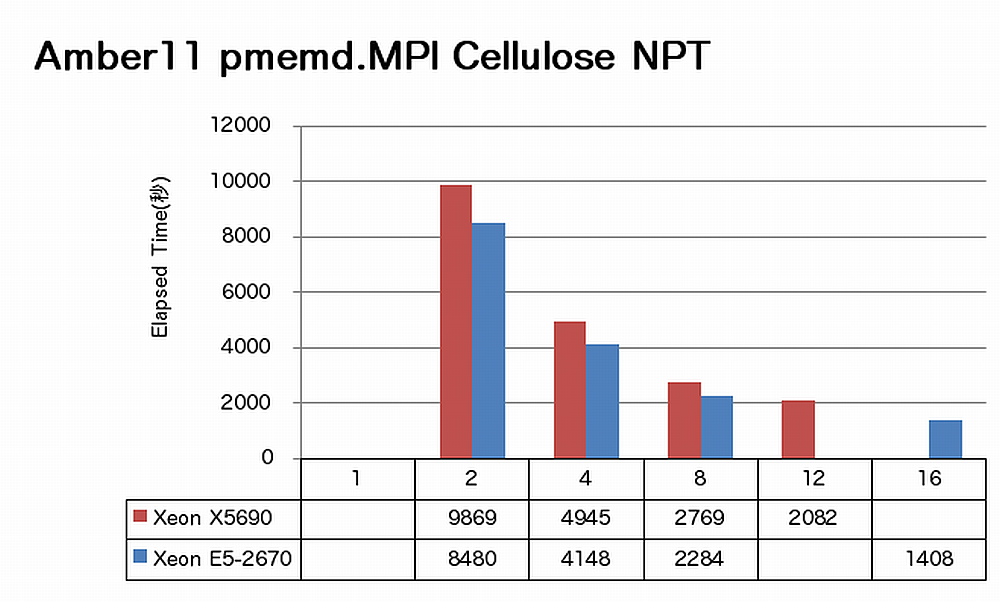
特長:16コアでも順調に速度向上
Amberでは、16コアまで順調に速度向上が得られています。ノードあたりで見ると、X5690に比べてE5-2670は、sanderの場合1.3倍、pmemdの場合1.4倍の速度向上を達成しています。
インテル®Xeon®E5-2600シリーズ搭載製品についてはこちらを参照ください。
VASP 5.2
AVXを適用可能なアプリケーションの例として、VASPをインテルコンパイラのAVX最適化を有効にしてビルドし、その性能を測定しました。従来から測定している216原子のPAW GGA計算とUSPP計算、およびお客様よりご依頼のありました実材料の計算インプットファイル(詳細は明かせませんが、40原子数における DFT:PAW-PBE)の計算の経過時間を示します。
| CPU | Xeon X5690 (3.46GHz,6コア,12MB Cache,6.4GT/s Intel QPI) | Xeon E5-2670 (2.60GHz,8コア,20MB Cache,8.4GT/s Intel QPI) |
|---|---|---|
| CPU搭載数 | 2(計12コア) | 2(計16コア) |
| OS | CentOS 5.6 | Red Hat Enterprise Linux 6.1 |
| M/B | HPC5000-1UTwin | X9DR6-F |
| Memory | 48GB | 64GB |
| Intel Compiler | 11.1 | 12.0 |
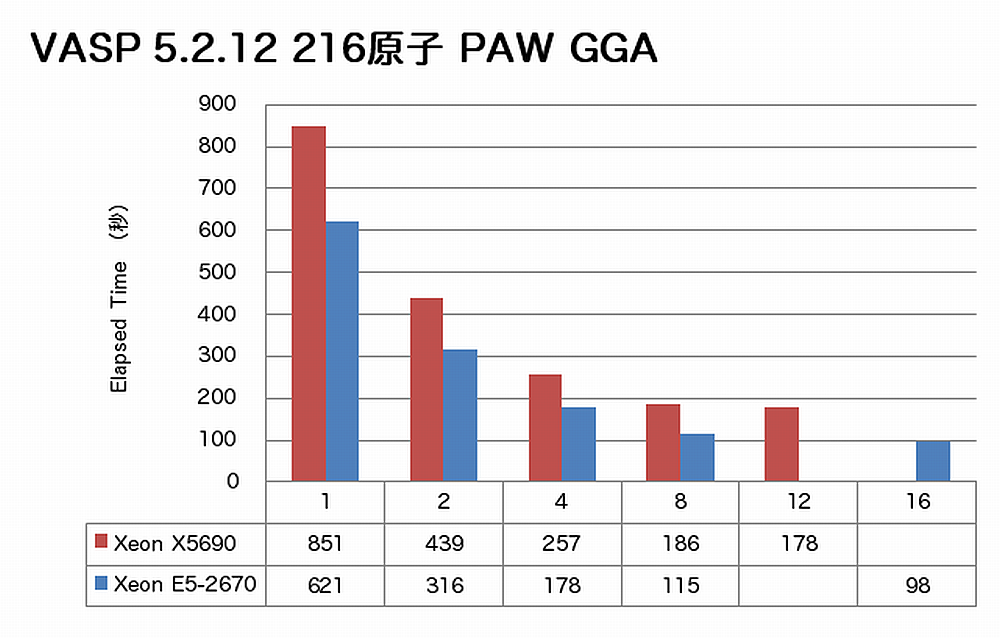
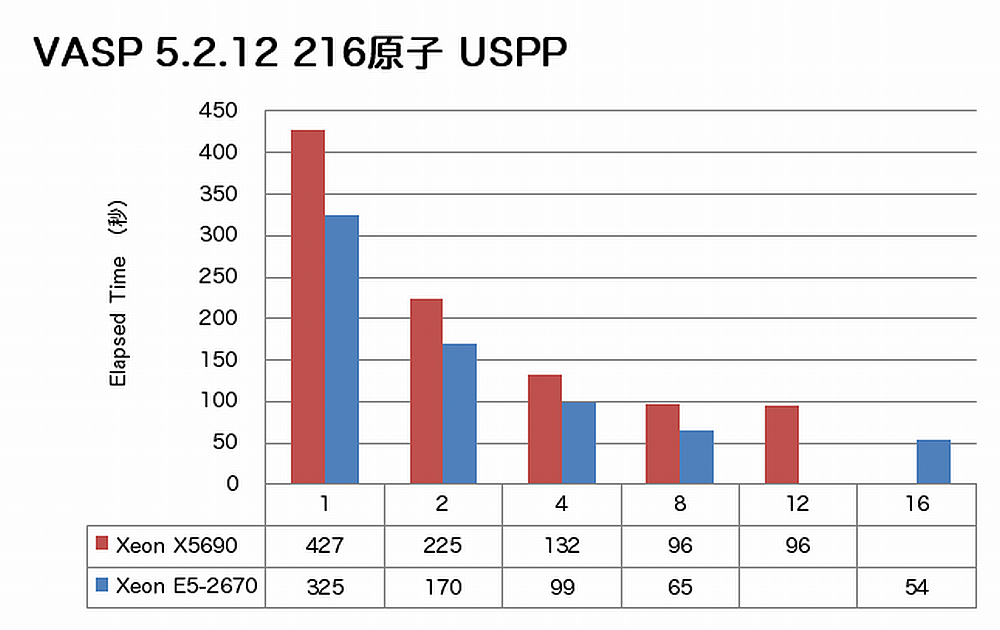
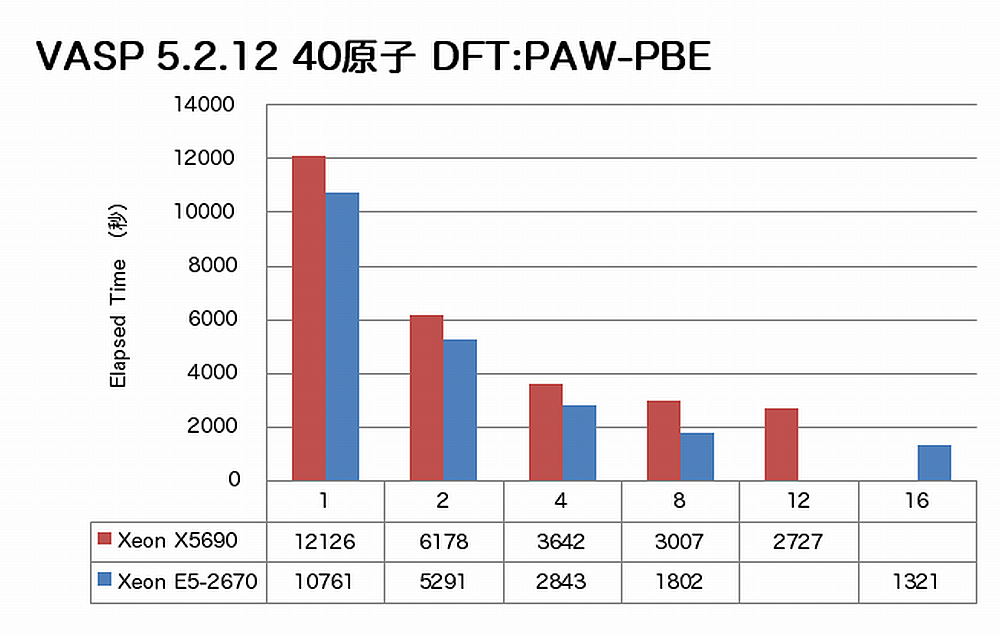
特長:絶対速度と並列性能の両方が大きく向上
VASPでは、現行CPU X5690に比べていずれの並列度でも大きく速度向上が得られています。また216原子 USPPのように、従来12コアで性能向上が止まっていた計算でも16コアまで速度向上が得られています。メモリバンド幅が性能に大きく影響するとなるVASP計算に対して、CPU-メモリ間転送速度1.6倍、CPU間転送速度2.5倍というプラットフォームの進化が大きく寄与しています。
インテル®Xeon®E5-2600シリーズ搭載製品についてはこちらを参照ください。
Gaussian 09 Rev. C01 ※AVX未対応
AVXに未対応のバイナリアプリケーションのベンチマーク実行例です。SSE4に最適化されたGaussian社製バイナリを用いてtest397ベンチマークを測定しました。
| CPU | Xeon X5690 (3.46GHz,6コア,12MB Cache,6.4GT/s Intel QPI) | Xeon E5-2670 (2.60GHz,8コア,20MB Cache,8.4GT/s Intel QPI) |
|---|---|---|
| CPU搭載数 | 2(計12コア) | 2(計16コア) |
| OS | CentOS 5.6 | Red Hat Enterprise Linux 6.1 |
| M/B | HPC5000-1UTwin | X9DR6-F |
| Memory | 48GB | 64GB |
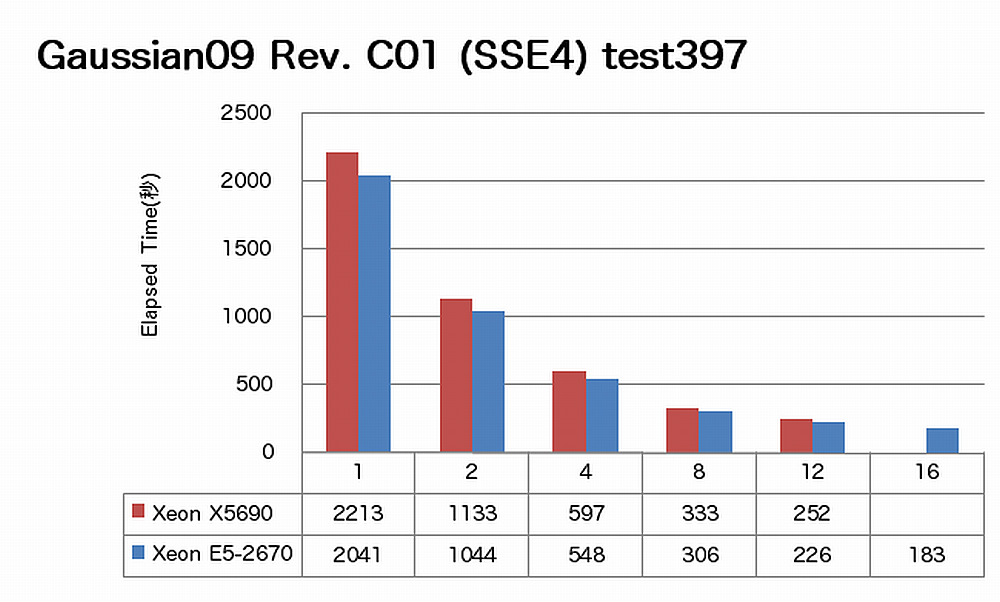
特長:従来バイナリのままでもノードあたり1.4倍の性能向上を達成
Gaussian 09では、E5-2670環境で実行するだけで、X5690 12コアに比べてE5-2670 16コアで1.38倍の性能を得る事が出来ました。8コアを超え、16コアまで順調な伸びが見られます。AVXに非対応でここまでの性能向上が得られていますので、今後AVX対応バイナリが発表されるのが待ち遠しいところです。
インテル®Xeon®E5-2600シリーズ搭載製品についてはこちらを参照ください。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)