
技術情報
複数枚インテル® Xeon Phi™ 5110Pでのインテル® MKL行列積ベンチマーク結果
インテル社からコプロセッサー Xeon Phi 5110Pが発表され、高い浮動小数点数性能に注目が集まっています。
しかし、コプロセッサーやアクセラレータでは、それらに向けて既存のアプリケーションソースコードを書きなおす手間が導入障壁として問題視されます。その中で、インテルMKL 11.0の一部の関数ではソースコードを修正することなくホストCPUとXeon Phiデバイスを自動的に併用して計算を高速化する「Automatic Offload」機能が利用可能になっています。この実効性能を明らかにするべく、行列積(gemm)ベンチマークを行いました。結果、ソースコード修正することなく、複数枚のXeon Phiデバイスを併用して計算が大きく高速化されることを確認できました。
コンパイルリンク手順
ソースコードには、sgemm/dgemm関数を実行する既存のCPU向け行列積ソースコードをそのまま用います。
そして、インテルMKL 11.0(マルチスレッド版)を従来通りリンクします。リンクのコマンドオプションは従来と何ら違いありません。
$ icc -O2 -Wall -Werror -std=c99 -I/opt/intel/composer_xe_2013.2.146/mkl/include -openmp -no-offload dgemm.c -L/opt/intel/composer_xe_2013.2.146/mkl/lib/intel64 -lmkl_intel_lp64 -Wl,–start-group -lmkl_intel_thread -lmkl_core -Wl,–end-group -o dgemm.exe
※「-no-offload」はAutomatic Offloadを使うには必須ではありません。ソースコード中に含まれる(Compiler Assisted Offload機能向けの)オフロード指示子をコンパイラが無視するように指定するオプションです。今回はAutomatic Offloadの評価ですので、Compiler Assisted Offloadを使っていないことを明示するために付加しています。
実行手順
MKLのAutomatic Offload機能を使うには、MKLを使う前に、環境変数MKL_MIC_ENABLEの値を1に設定します。
$ setenv MKL_MIC_ENABLE 1
これにより、MKL内の関数を呼び出したときに、セットアップ済みのXeon Phiデバイスを自動的に併用するようになります。つまり、ホストCPUとXeon Phiデバイスのコアの間で、dgemm等の関数の計算タスクが自動的に分散されて、協調して途中計算データをやり取りしながら、並列計算されるようになります。
Automatic Offload関連では、他にも、以下の環境変数を使用して振る舞いを制御できます。
| OFFLOAD_DEVICES | 使用させるXeon Phiデバイスを指定する |
| OFFLOAD_REPORT | オフロード時の動作レポートを出力させるレベル |
| MKL_HOST_WORKDIVISION | Automatic Offload時のホストのタスク担当割合 |
| MKL_MIC_0_WORKDIVISION | Automatic Offload時の0番目のXeon Phiデバイスのタスク担当割合 |
| MKL_MIC_1_WORKDIVISION | Automatic Offload時の1番目のXeon Phiデバイスのタスク担当割合 |
| MIC_ENV_PREFIX | Xeon Phiデバイス上で適用させる環境変数の、ホスト上で付けるプレフィックスを指定する (ここでは例として"MIC”) |
| MIC_OMP_NUM_THREADS | Xeon Phiデバイス上で適用させるOpenMPスレッド数 |
| MIC_KMP_AFFINITY | Xeon Phiデバイス上で適用させるKMP_AFFINITY環境変数の値 |
ベンチマーク結果
評価環境を次表に示します。
| 製品名 | HPC5000-XSPHI4R2S |   |
|---|---|---|
| プロセッサー | インテル Xeon E5-2680(8コア、2.70GHz)×2CPU | |
| コンパイラー | インテル Composer XE 2013 Linux版 | |
| 数値演算ライブラリー | インテル MKL 11.0 Update 1 | |
| コプロセッサー | インテル® Xeon Phi™ 5110P ×2基 | |
| OS | Red Hat Enterprise Linux 6.3 x86_64 |
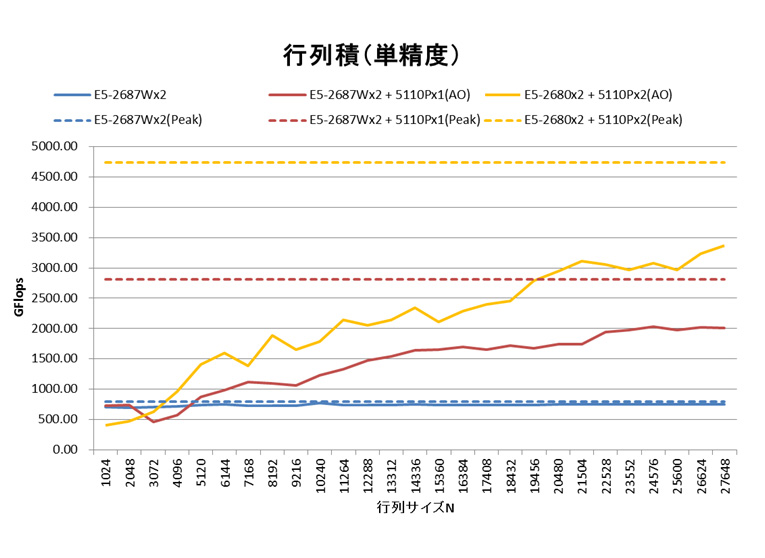
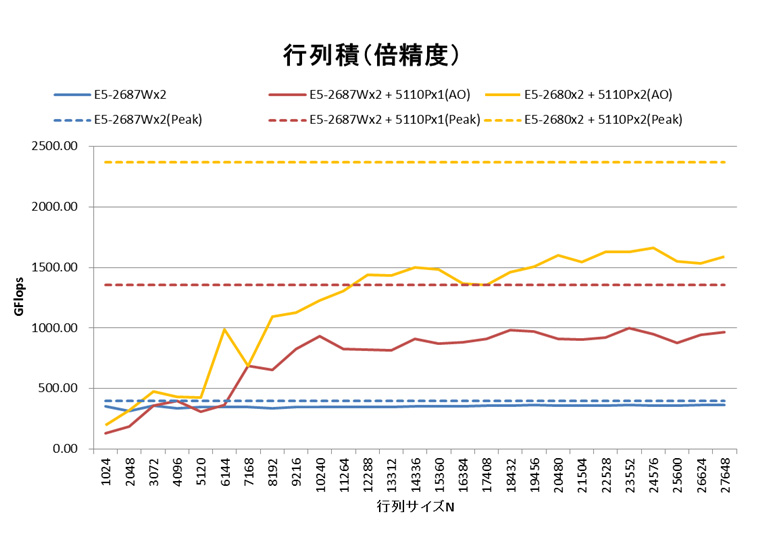
インテルMKLのAutomatic Offload機能により、行列積の性能がXeon Phiデバイスの追加分向上しているとわかります。行列サイズ15,000以上の範囲では、性能増加分はおおよそXeon Phi 5110Pの理論性能の50%となっています。CPU向けのソースコードを変えることなく、MKL11.0をリンクして実行時に環境変数を設定するだけで、これだけの性能向上が得られることは、既存のCPU向けソースコード使用者にとって大変魅力的と言えるでしょう。
注意事項
sgemm/dgemm関数では、Automatic Offload機能が働く条件に「行列サイズが2048より大きいこと」という制限があります(行列サイズが小さい場合、データ転送オーバーヘッドがXeon Phiの高速化効果を見劣りさせてしまうため)。
小さい行列サイズで行列積を実行するアプリケーションでは、この制限のためにAutomatic Offloadの恩恵を受けられないことがあります。また、すべてのMKL内関数がAutomatic Offloadに対応しているわけではありません。MKLのリリースノート等を参照いただき、Automatic Offloadが働く条件を事前にご確認いただくことをお勧めいたします。
関連リンク
・Intel、インテル、Intelロゴ、Xeon、Xeon Inside は、米国およびその他の国におけるIntel Corporationの商標です。
・その他、記載されている会社名、製品名、サービス名等は、各社の商標または登録商標です。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)