
技術情報
インテル® Xeon Phi™ 5110PとNVIDIA® Tesla® K20の行列積における実効性能比較 その②
インテル社からコプロセッサー「Xeon Phi™ 5110P」が、NVIDIA社からKeplerアーキテクチャーGPU「Tesla® K20」が発表され、いずれも高い浮動小数点数演算性能に注目が集まっています。これらの実効性能を明らかにするべく、弊社で以前より定点観測している行列積ベンチマークを行いました。結果、単精度・倍精度とも、NVIDIA社 K20に軍配が上がりました。
※CUDA5対応、2013年3月更新
ベンチマーク結果
Tesla® K20の評価環境は以下の通りです。
| 評価環境 | ||
|---|---|---|
| ノード数 | 1 |   |
| フォームファクター | タワー型 (4Uラックマウント対応) | |
| プロセッサー | インテル Xeon プロセッサー E5-2687W @ 3.10GHz x2CPUs | |
| メモリ | 64GB DDR3 | |
| GPGPUカード | NVIDIA® Tesla® K20M | |
| コンパイラー | PGI Accelerator Fortran/C/C++ Workstation 2013 (13.3) | |
| 数値演算ライブラリー | インテル MKL 11.0 Update 1 | |
| GPU用数値計算ライブラリ | CUBLAS (CUDA Toolkit 5.0付属) | |
| OS | CentOS 6.2 x86_64 | |
Xeon Phi™ 5110Pの測定時は、同マシンからTesla® K20Mを外し、Xeon Phi™ 5110P ×1を差して、Red Hat Enterprise Linux 6.3で測定を行いました。
| 評価環境 | ||
|---|---|---|
| ノード数 | 1 |   |
| フォームファクター | タワー型 (4Uラックマウント対応) | |
| プロセッサー | インテル Xeon プロセッサー E5-2687W @ 3.10GHz x2CPUs | |
| メモリ | 64GB DDR3 | |
| コプロセッサー | インテル® Xeon Phi™ 5110P | |
| コンパイラー | インテル Composer XE 13.0 Update 1 | |
| 数値演算ライブラリー | インテル MKL 11.0 Update 1 | |
| MPI | Intel MPI 4.1 | |
| OS | Red Hat Enterprise Linux 6.3 x86_64 | |
行列積プログラムでは、CUDA5で利用可能となったShared Memoryのバンクサイズを設定するcudaDeviceSetSharedMemConfig関数で、4バイト/8バイトの両方を試し、ベンチマーク測定では速い方を一貫して用いました。
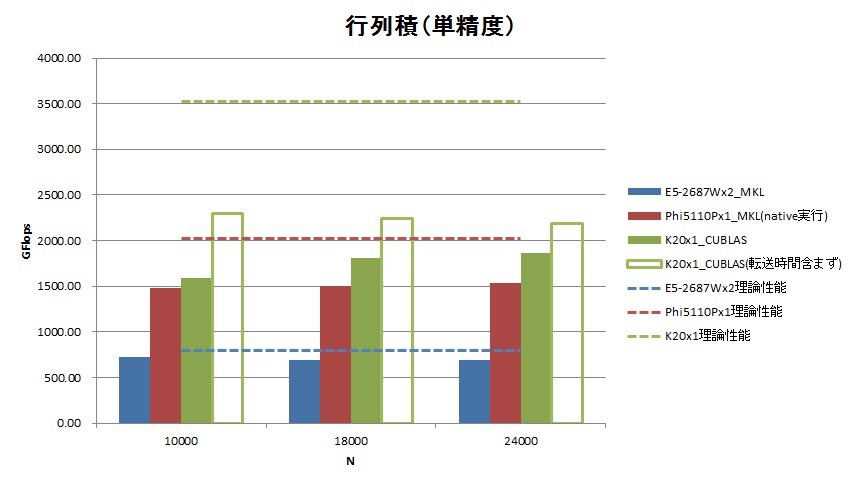
| 単精度 | N | 計算時間[秒] | GFlop | GFlops | 理論性能 | 実行効率 |
|---|---|---|---|---|---|---|
| E5-2687W x2 MKL | 10000 | 2.58 | 1863 | 722.12 | 793.60 | 91.0% |
| Phi 5110P x1 MKL(native実行) | 10000 | 1.25 | 1863 | 1486.28 | 2021.76 | 73.5% |
| K20 x1 CUBLAS | 10000 | 1.17 | 1863 | 1589.46 | 3520.00 | 45.2% |
| K20 x1 CUBLAS(転送時間含まず) | 10000 | 0.81 | 1863 | 2292.49 | 3520.00 | 65.1% |
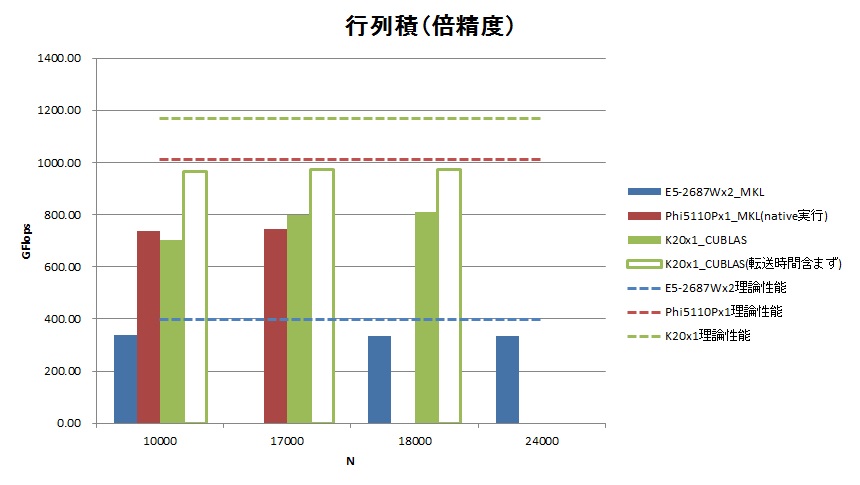
| 倍精度 | N | 計算時間[秒] | GFlop | GFlops | 理論性能 | 実行効率 |
|---|---|---|---|---|---|---|
| E5-2687W x2 MKL | 10000 | 5.53 | 1863 | 336.91 | 396.80 | 84.9% |
| Phi 5110P x1 MKL(native実行) | 10000 | 2.53 | 1863 | 736.95 | 1010.88 | 72.9% |
| K20 x1 CUBLAS | 10000 | 2.64 | 1863 | 704.34 | 1170.00 | 60.2% |
| K20 x1 CUBLAS(転送時間含まず) | 10000 | 1.93 | 1863 | 965.26 | 1170.00 | 82.5% |
この結果、次がわかりました。
- 単精度行列積では、K20がN=24,000時1.864TFlopsを達成しました。これはXeon Phi™ 5110Pに比べ1.22倍高速です。またホスト-K20間のデータ転送時間を含めない場合、2.191TFlops(5110Pの1.43倍)を達成したことになります。
- 倍精度行列積では、K20がN=17,000時に799.28GFlopsを達成しました。これはXeon Phi™ 5110Pに比べ1.07倍高速です。またホスト-K20間のデータ転送時間を含めない場合、974.5GFlops(5110Pの1.31倍)を達成したことになります。
- 理論性能に対する実行効率はE5-2687W + MKLが84~91%程度、Xeon Phi™ 5110P + MKLが73~76%程度に対し、K20は倍精度で60%(ホスト-K20間のデータ転送時間を含めなければ82%)となりました。
結論
単精度計算・倍精度計算の両方において、K20がPhi 5110Pよりも高い実効性能となりました。特に倍精度では、前回のCUDA4.2でのベンチマーク と比べて1.59倍の実効性能向上となっています。Kepler向けの最適化が図られたCUDA5(PGIコンパイラでは2013以降で対応)は、K20を使う上で不可欠と言えるでしょう。
K20、Phi 5110Pのいずれも、CPU(E5-2687W)を大きく引き離す性能を示しています。お使いのアプリケーションをコプロセッサー/アクセラレータ向けにプログラミングする工数と、それによって得られる計算速度を再検討してみる良いきっかけとなるのではないでしょうか。
今後の展開
2013年のサーバー向けCPUの話題として、SandyBridgeマイクロアーキテクチャーの22nmプロセス品 IvyBridgeシリーズのリリースが噂されています。K20に追い抜かれたE5-2600シリーズが後継品でどう挽回してくるか、興味深いところです。
関連リンク
・Intel、インテル、Intelロゴ、Xeon、Xeon Inside は、米国およびその他の国におけるIntel Corporationの商標です。
・NVIDIA、NVIDIAロゴ、CUDAおよびTeslaは、米国及びその他の国におけるNVIDIA Corporationの商標または登録商標です。
・その他、記載されている会社名、製品名、サービス名等は、各社の商標または登録商標です。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)