
技術情報
インテル® Xeon® プロセッサー E7-8800 v2 ファミリー ベンチマーク結果
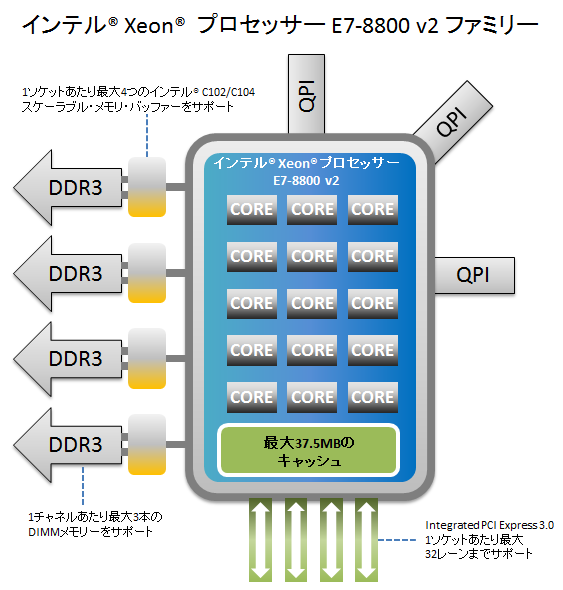
第3世代 Intel Core アーキテクチャのハイエンドサーバ向けプロセッサー Intel Xeon E7-8800 v2 ファミリーがリリースされています。従来製品のE7-8800 ファミリーと比較して、プロセス製造が32nmから22nmに微細化され、コア数は最大10コア/20スレッドから15コア/30スレッドへ増加、キャッシュは最大30MBから37.5MBへ増加しました。さらに、拡張命令セット インテル AVX(Advanced Vector Extensions)に対応し、E7-8800 ファミリーと比較してコアあたり2倍の理論演算性能が見込めます。1本あたり6.4GT/sから最大8.0GT/sに増大したQPIリンクを3本備えており、CPU上のスレッド間通信においてさらなる高速アクセスを実現します。
Intel Xeon E7-8800 v2 ファミリーの性能を調査するため、E7-8857 v2を8基搭載した8-wayマシンでHPLと各種実用アプリケーションのベンチマークを実施しました。
| CPU | Xeon E5-2697 v2 (2.70GHz, 12コア, 30MB Cache, 8GT/s Intel QPI, TDP130W) | Xeon E5-2697 v3 (2.60GHz, 14コア, 35MB Cache, 9.6GT/s Intel QPI, TDP145W) | Xeon E7-8857 v2 (3.00GHz, 12コア, 30MB Cache, 8.0GT/s Intel QPI, TDP130W) |
|---|---|---|---|
| CPU数 | 2 (計24コア) | 2 (計28コア) | 8 (計96コア) |
| 倍精度 理論性能 | 518.4GFLOPS ( = 2.70GHz * 12コア * 8 * 2 ) | 1164.8GFLOPS ( = 2.60GHz * 14コア * 16 * 2 ) | 2304GFLOPS ( = 3.0GHz * 12コア * 8 * 8) |
| メモリ | 128GB DDR3 1866MHz | 128GB DDR4 2133MHz | 3TB DDR3 1066MHz |
| OS | CentOS 6.4 x86_64 | CentOS 6.4 x86_64 | RedHat Enterprise Linux Server 6.4 x86_64 |
HPL
HPLはスーパーコンピュータの性能ランキング『Top 500 Supercomputer Sites』で用いられているベンチマークプログラムです。連立方程式の解を求めるプログラムで、浮動小数点演算の性能をFLOPS単位、つまり1秒間に処理できる浮動小数点演算命令の数で性能を評価します。HPLでCPUの実効性能を計測し、理論性能どおりの実効性能の向上があるかを調査しました。
HPLではIntel ComposerでAVX2とAVXのCPU最適化オプションが可能な場合は有効にしてビルドを行い、ベンチマークを実施しました。結果は以下図の通りとなりました。
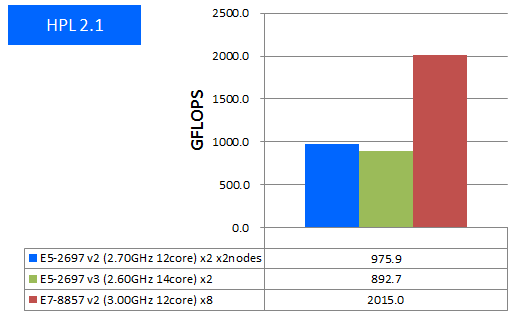
特長:1ノードで2TFLOPSの実効性能に到達
1ノードで2TFLOPSを超える高い実効性能が見られました。新しく追加されたAVXの効果が確かに現れたと言えます。2014年10月執筆時点で最新の第4世代 Intel CoreアーキテクチャのE5-2697 v3と比較して、ノードあたり2.26倍の実効性能となっており、OpenMP等を用いるノード内並列計算アプリケーションの最大性能を追求される方にお勧めいたします。実効性能では最大でここまで出せるという一つの目安として捉えていただければと思います。
Amber12
Amberは生体分子シミュレーションソフトウェアのひとつです。Intel ComposerのAVX2とAVXのCPU最適化オプションが可能な場合は有効にしてビルドをしたものでベンチマークを行いました。Amber公式サイトで配布されている408,000原子のCellulose NVEのインプットをpmemdで計算したときの経過時間を測定しました。
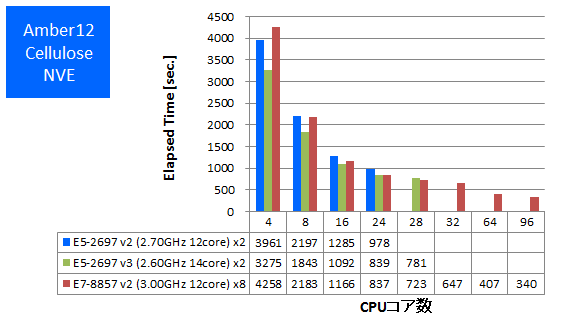
特長:フルコア96並列まで速度向上
E7-8857 v2では8CPUフルコア使用時96並列まで、Amberの計算速度が向上しました。フルコア並列時は24並列時の2.5倍の計算速度となっています。
VASP
VASPは密度汎関数法による平面波・擬ポテンシャル基底を用いた第一原理電子状態計算プログラムパッケージです。このプログラムは並列実行時にCPU-メモリ間帯域を多く使用する傾向があります。
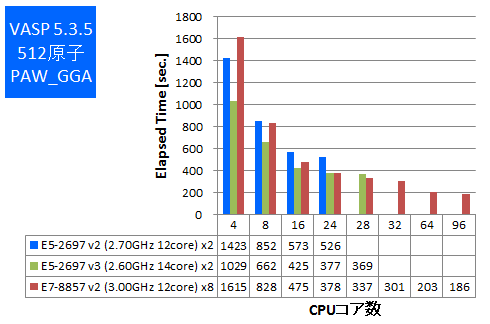
今回はIntel ComposerでAVX2とAVXのCPU最適化オプションが可能な場合は有効にしてビルドをしたものでベンチマークを実施しました。512原子と1000原子でのPAW GGA計算とUSPP計算を行い、実行時間の比較をしました。
※1000原子のPAW GGA計算の4,8,24並列は時間不足のため取得できておりません。予めご了承ください。
- ① 512原子 PAW_GGA
- ② 512原子 USPP
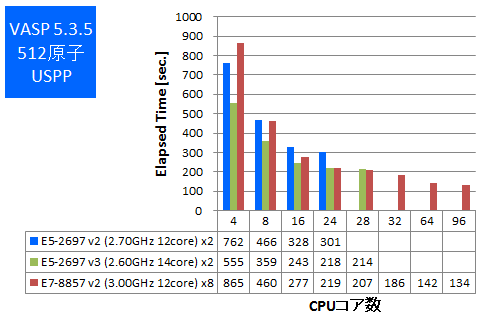
- ③ 1000原子PAW_GGA
- ④ 1000原子USPP
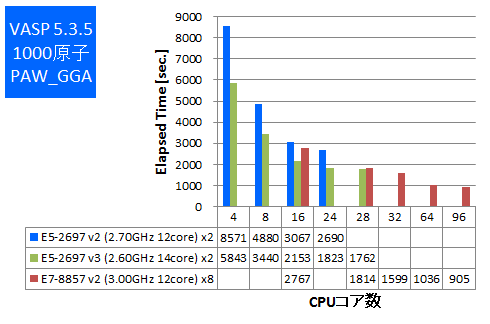
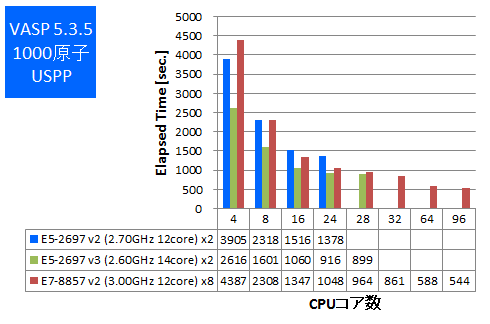
特長:メモリ帯域要求の強いVASPにおいてもフルコア96並列まで速度向上
VASPにおいても、E7-8857 v2で8CPUフルコア使用時96並列まで計算速度が向上しました。PAW GGA計算において、28並列時の約2倍の計算速度が96並列で得られています。8CPU環境では単に並列動作させると後述のGaussianのように遠いメモリアクセスによって計算速度が低下することが懸念されますが、それにもかかわらずメモリ帯域要求の強いVASPで律速していないことについては、Intel MPIのスケーラビリティ向上技術が功を奏していると考えられます。
Gaussian 09 ※AVX,AVX2未対応
量子化学計算のデファクトスタンダードであるGaussianでのベンチマークを行いました。今回使用したものはSSE4に最適化されたGaussian社標準のBinary版パッケージでAVX2やAVXは未対応のものになります。Gaussianパッケージに付属のtest0397と、その基底関数系を大きくしたインプットについて実行時間を比較しました。
- ① test0397 (RB3LYP/3-21G)
- ② rkest (RB3LYP/6-31G(D,P))
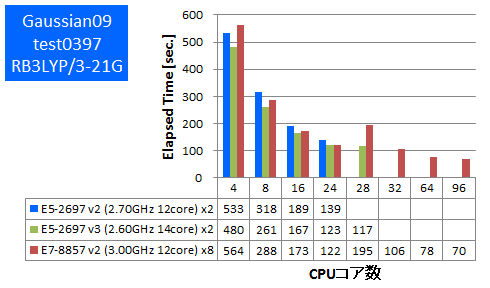
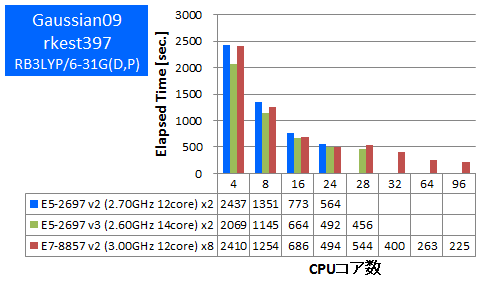
特長:コア-スレッド割り当て最適化後、フルコア96並列まで並列スケーラビリティを達成
Gaussian 09では既定のインプットのままでは28並列以上でCPU使用率の低下・速度低下が見られましたが、スレッドとCPUコアへの割り当てを固定化するLink 0コマンドを指定したところ、フルコア96並列までスケーラビリティが得られました(使用したLink 0コマンドについては本稿では割愛いたします)。28並列時に特異的に遅いのは、スレッド群が8個のCPUに均等に割り当たらなかったためと考えられます。今回のような多CPU構成のNUMA(Non-Uniform Memory Access)型並列計算機では、CPUから他CPUに属するメモリへのアクセスにおける遅延が並列計算時の性能ボトルネックとして顕著化しやすいため、メモリアクセスやコア-スレッド割り当てを制御する技術が重要となってきます。
複数ジョブ同時実行
逐次計算、あるいは小さな並列数で計算を実行すべき状況では、同時に数多くの計算を高スループットにこなす能力がCPUに求められます。HPL、VASPについて、同一の計算ジョブを同時に複数実行し、プロセス数が増えた時の性能劣化率(1プロセス実行時を100%とします)を測定しました。HPLではGFLOPSを、VASPでは経過時間を記していますので良悪の捉え方が逆となる点にご注意ください。
| CPU | Xeon E5-2697 v2 (2.70GHz, 12コア, 30MB Cache, 8GT/s Intel QPI, TDP130W) | Xeon E5-2697 v3 (2.60GHz, 14コア, 35MB Cache, 9.6GT/s Intel QPI, TDP145W) | Xeon E7-8857 v2 (3.00GHz, 12コア, 30MB Cache, 8.0GT/s Intel QPI, TDP130W) |
|---|---|---|---|
| CPU数 | 2 (計24コア) | 2 (計28コア) | 8 (計96コア) |
| メモリ | 128GB DDR3 1866MHz | 128GB DDR4 2133MHz | 3TB DDR3 1066MHz |
| OS | CentOS 6.4 | CentOS 6.5 | Red Hat Enterprise Linux Server 6.4 |
| インテル コンパイラー | 13.1 | 13.1 | 13.1 |
| MPI | Open MPI 1.6.5 | Open MPI 1.6.5 | Intel MPI 4.1.3 |
| HPL | 2.1 | 2.1 | 2.1 |
| VASP | 5.3.3 22May2013 | 5.3.5 | 5.3.5 |
- ① 同時実行:HPL 2.1
- ② 同時実行:VASP 64原子 PAW_GGA
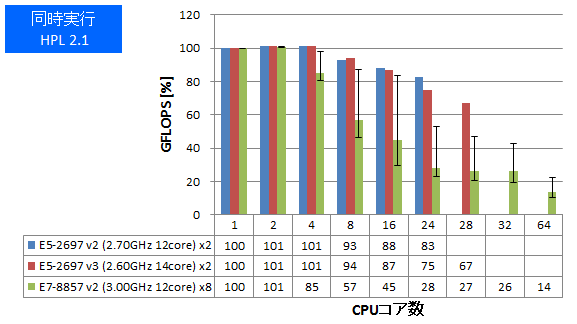
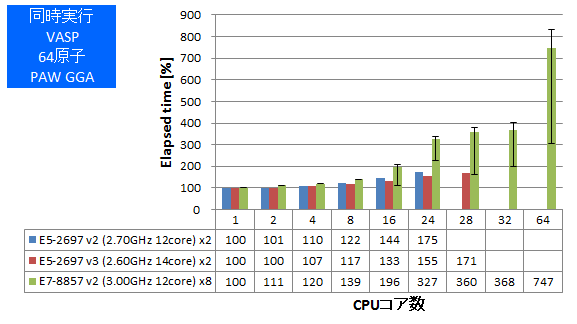
特長:2ソケット製品と比べて複数ジョブ同時実行時の性能劣化が顕著
E7-8857 v2ではHPL・VASPともに、複数ジョブ同時実行時の性能劣化率が、2ソケット製品よりも大幅に大きいことがわかりました。また、エラーバーで示しますように、ジョブ間の性能のばらつきも大きくなっていました。今回の測定では単にジョブプロセスを複数バックグラウンド起動させただけでしたので、コア-スレッド割り当てがOS任せとなり、遅いメモリアクセスが発生して大きな性能劣化につながった可能性が考えられます。
関連リンク
・Intel、インテル、Intelロゴ、Xeon、Xeon Inside は、米国およびその他の国におけるIntel Corporationの商標です。
・その他、記載されている会社名、製品名、サービス名等は、各社の商標または登録商標です。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)