
技術情報
インテル® Xeon® プロセッサー E5-4600 v3 ファミリー ベンチマーク結果
第4世代 Intel Coreアーキテクチャのハイエンドサーバー向けプロセッサー Intel Xeon E5-4600 v3 ファミリーがリリースされました。この製品はHaswell-EPに準じたAVX2やFMA機能を実装しており、2014年にリリースされたDDR4規格のメモリに対応した4ソケットサーバー向けCPUです。2014年にリリースされた2ソケットサーバー向けのE5-2600 v3 ファミリーと同じ特長を有するため、HPC用途に高性能が期待できます。このシステムでは1台のサーバーに対して最大48枚までDIMMを搭載することができ、大容量メモリを使用する解析計算にも対応が可能です。
各アプリケーションのベンチマークを実施して、同アーキテクチャのE5-2600 v3の2ソケットサーバーと実効性能を比較しました。
ベンチマークで使用した検証環境は次表のとおりです。
| CPU | Intel Xeon E5-4667 v3 | Intel Xeon E5-2667 v3 |
|---|---|---|
| アーキテクチャ | 第4世代Intel Coreプロセッサー | 第4世代Intel Coreプロセッサー |
| CPUクロック | 2.0GHz | 3.2GHz |
| AVX時CPUクロック | 1.7~2.3GHz | 2.7GHz |
| CPUコア数 | 16 | 8 |
| CPUキャッシュ | 40MB | 20MB |
| QPI性能 | 9.6GT/s | 9.6GT/s |
| 対応メモリ規格 | DDR4 | DDR4 |
| 対応メモリFSB | 2133MHz | 2133MHz |
| 理論性能 | 435.2 GFlops ( = 1.7GHz × 16core × 16 ) | 345.6 GFlops ( = 2.7GHz × 8core × 16 ) |
| 理論性能 [フルコア使用TurboBoost時最大時] | 588.8 GFlops ( = 2.3GHz × 16core × 16 ) | 同上 |
| 製品 | HPC5000-XH448R2S | HPC5000-XH2UTwin-D24 |
|---|---|---|
| CPU | Intel Xeon E5-4667v3 × 4CPU (計64core) | Intel Xeon E5-2667v3 × 2CPU (計16core) |
| メモリ | DDR4 512GB 2133MHz | DDR4 128GB 2133MHz |
| HDD | 1TB SATA 6Gb/s | 1TB SATA 6Gb/s |
| OS | CentOS 6.5 x86_64 | CentOS 6.5 x86_64 |
| コンパイラ | Intel Compiler 13.1 | Intel Compiler 13.1 |
| MPI | Intel MPI 4.1.3、Open MPI 1.6.5 | Intel MPI 4.1.3、Open MPI 1.6.5 |
HPL
HPLはスーパーコンピュータの性能ランキング『Top 500 Supercomputer Sites』で用いられているベンチマークプログラムです。連立方程式の解を求めるプログラムで、浮動小数点演算の性能をFLOPS単位、つまり1秒間に処理できる浮動小数点演算命令の数で性能を評価します。HPLでCPUの実効性能を計測し、理論性能どおりの実効性能の向上があるかを調査しました。
HPLはIntel ComposerでAVX2とAVXのCPU最適化オプションを有効にしてビルドしたものでベンチマークを実施しました。MPIにはIntel MPIを使用しました。結果は以下図の通りとなりました。
- HPL 2.1
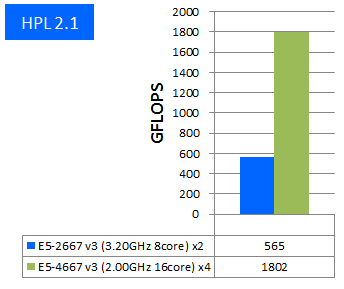
特長:1ノード当り1.8TFlopsの実効性能に到達
1ノード当りの性能が1.8TFlopsという目覚ましい実効性能が達成されました。2014年リリースのE7-8800 v2 8ソケットサーバーのベンチマーク結果(こちら、約2TFlops)と近い実効性能を4CPUで達成しています。新しく追加されたAVX2やFMAの効果が、4つのCPUそれぞれで発揮され、高い総合性能として現れたと言えます。実効性能では最大でここまで出せるという一つの目安として捉えていただければと思います。
Amber12
Amberは生体分子シミュレーションソフトウェアのひとつです。Intel ComposerのAVX2とAVXのCPU最適化を有効にしてビルドをしたものでベンチマークを行いました。Amber公式サイトで配布されている408,000原子のCellulose NVEのインプットをpmemdで計算したときの経過時間を測定しました。MPIにはOpen MPIを使用しました。
- 408,000原子 Cellulose NVE
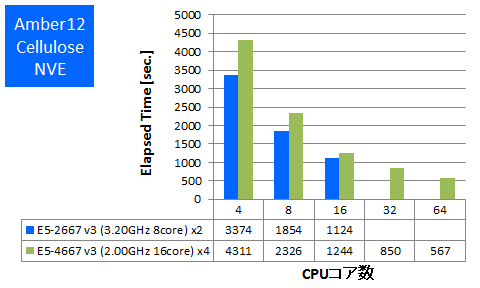
特長:4CPUフルコアまで順調に性能向上
32並列時に比べ64並列時の経過時間が1.5倍も短縮され、順調な性能向上が達成されました。既存の8ソケットベンチマークでも比較的Amberは並列性能スケーラビリティが出やすい傾向があり、E5-4600 v3 4ソケットサーバーにおいてもそれが見受けられました。
VASP
VASPは密度汎関数法による平面波・擬ポテンシャル基底を用いた第一原理電子状態計算プログラムパッケージです。このプログラムは並列実行時にCPU-メモリ間帯域を多く使用する傾向があります。
今回はIntel ComposerでAVX2とAVXのCPU最適化を有効にしてビルドをしたものでベンチマークを実施しました。512原子でのPAW GGA計算とUSPP計算を行い、実行時間の比較をしました。MPIには、大規模並列時の性能向上が弊社で確認されているIntel MPIを使用しました。
- ① 512原子 PAW_GGA
- ② 512原子 USPP
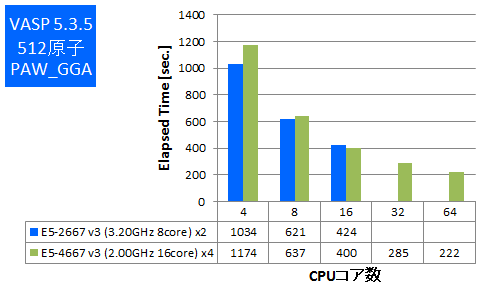
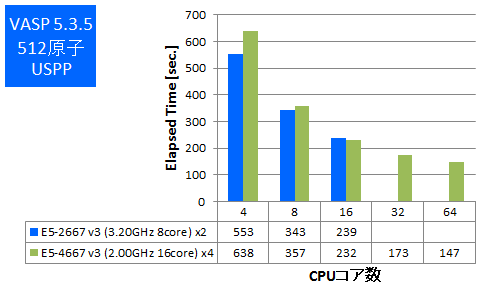
特長:メモリ帯域要求が強いVASPでもかろうじてフルコア並列まで性能向上
E5-2600 v3 2ソケットサーバーでのベンチマーク結果において24並列以上で伸び悩みが見受けられていたように、E5-4600 v3 4ソケットサーバーでも32並列以上は小幅な性能向上にとどまりました。しかし、経過時間はフルコア並列まで短縮されていますので、大規模なメモリを使用するケースで経過時間をできるだけ短縮されたいお客様にお勧めできると言えます。性能が伸び悩む原因はCPU-メモリ間帯域によるボトルネックと考えています(以前のモデルのCPUからも同様の傾向があります)。
Gaussian 09 ※AVX,AVX2未対応
量子化学計算のデファクトスタンダードであるGaussianでのベンチマークを行いました。今回使用したものはSSE4に最適化されたGaussian社標準のBinary版パッケージでAVX2やAVXは未対応のものになります。Gaussianパッケージに付属のtest0397に加えて、基底関数数の異なるDFT計算について実行時間を比較しました。
- ① rkest (基底関数数:1620, SP ,RB3LYP/6-31G(D,P))
- ② test0397 (基底関数数:882, SP, RB3LYP/3-21G )
(Gaussian09パッケージ付属) 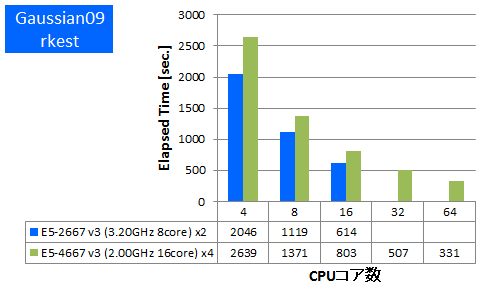
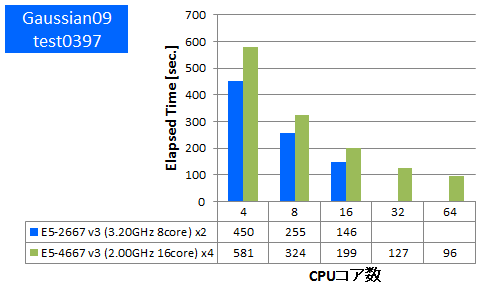
特長:AVX,AVX2非対応バイナリでもフルコア並列まで順調に性能向上
フルコア並列まで順調に経過時間短縮が確認できました。複数CPUにまたがったスレッド並列計算に、フルコア並列までE5-4600 v3 4ソケットサーバーの性能を引き出すことができると言えます。
関連リンク
インテル® Xeon® プロセッサー E5-4600 v3 ファミリー対応製品
・Intel、インテル、Intelロゴ、Xeon、Xeon Inside は、米国およびその他の国におけるIntel Corporationの商標です。
・その他、記載されている会社名、製品名、サービス名等は、各社の商標または登録商標です。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)